Key Takeaways
- Most companies deploying frontier LLMs for narrow, repeatable tasks are paying for capability they never use. According to Iterathon’s 2026 enterprise SLM cost analysis, serving a 7-billion parameter small language model is 10 to 30 times cheaper than running a 70 to 175 billion parameter LLM, cutting infrastructure costs by up to 75%.
- A fine-tuned small model on your own data does not just save money. It frequently outperforms the giant general-purpose model on the narrow task it was trained for, according to Machine Learning Mastery’s 2026 guide to small language models.
- Fine-tuning a 7B parameter model now costs under $5 and takes hours according to Spheron’s 2026 fine-tuning cost report, down from budgets that required dedicated ML teams and serious GPU clusters just three years ago.
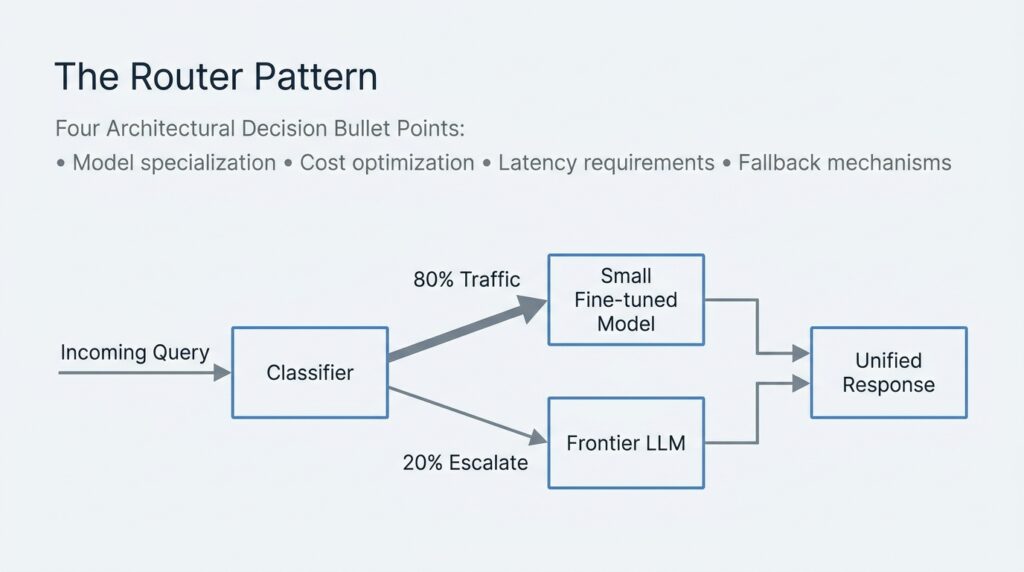
- The smartest production architectures in 2026 are not choosing LLM or SLM. They are routing roughly 80% of predictable queries to a small model and escalating only the genuinely complex 20% to a frontier LLM, a pattern multiple enterprise deployments now confirm works.
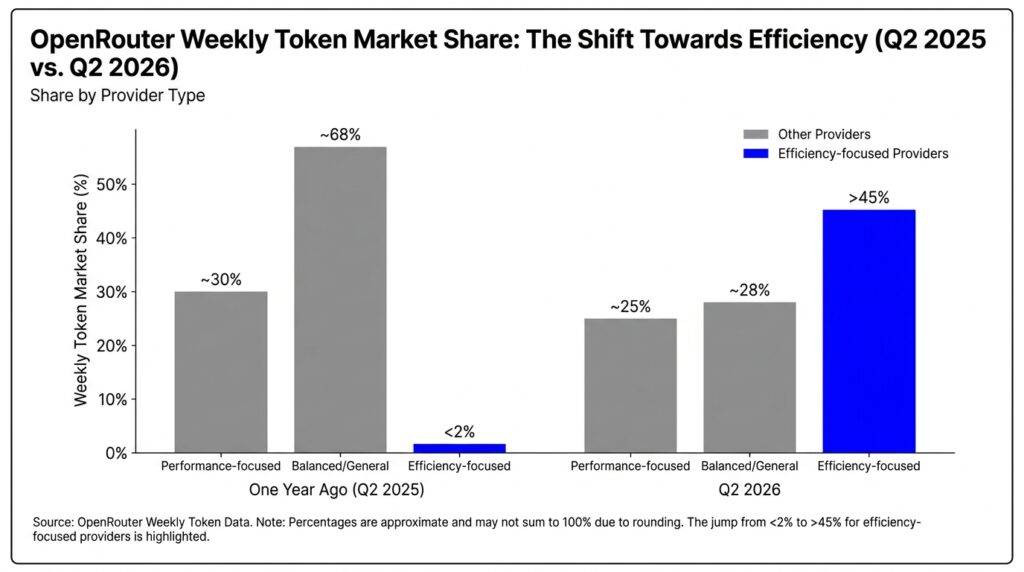
- This is not a future prediction. It is already happening at scale. Chinese AI providers running predominantly smaller, efficient models now account for more than 45% of Open Router’s total weekly token volume, up from under 2% a year earlier, according to Digital Applied’s Q2 2026 market share report.
Table of Contents
Introduction
Here is a question most engineering teams never bother asking before they wire up an API call: does this task actually need a 175 billion parameter model, or did you reach for GPT-5 because it was the first name that came to mind?
That question is costing companies real money in 2026, and the answer is becoming impossible to ignore. The small language models vs large language models 2026 debate has moved past theory. It is now a production architecture decision with measurable cost and performance consequences, and most teams are still getting it wrong by default.
This is not an argument against frontier models. GPT-5.5, Claude Opus 4.7, and Gemini 3.1 Pro remain genuinely necessary for tasks that require broad world knowledge, complex multi-step reasoning, or handling questions you cannot predict in advance. But the overwhelming majority of production AI workloads, customer support routing, internal document classification, domain-specific code completion, structured data extraction, are not that. They are narrow, repeatable, and high-volume. And for that category of work, the data on SLM vs LLM cost comparison in 2026 makes the right answer obvious once you actually look at it.
This guide breaks down what small language models actually are, when they genuinely beat a frontier model rather than just being a cheaper compromise, and how to build the hybrid architecture that the most efficient AI teams are quietly running right now. If you are still wiring models together without a standard way for them to talk to your tools and data, it is worth first understanding how Model Context Protocol gives AI agents a consistent way to connect to everything around them, since the routing architecture covered later in this guide depends on exactly that kind of standardized plumbing.
What a Small Language Model Actually Is
Before going further, it helps to be precise about what separates an SLM from an LLM, because the boundary is about more than parameter count.
A large language model like GPT-5.5 or Claude Opus 4.7 is trained to be a generalist. It needs to handle questions about astrophysics, write poetry, debug Python, and explain tax law, often within the same conversation. That breadth requires enormous scale, generally tens to hundreds of billions of parameters, and the infrastructure to match.
A small language model is built around a different premise entirely. According to Label Your Data’s 2026 breakdown of SLM versus LLM tradeoffs, small language models and large language models differ mainly in scale, training scope, and deployment demands. Large language models are built to know a little about everything. Small language models, once fine-tuned, know a lot about one specific thing, and that depth is exactly where they pull ahead. A 3B model trained on customer support conversations will outperform GPT-4 on your specific support queries while running on hardware you already own.
The analogy that makes this click for most developers: hiring an employee who already speaks English and training them on your company’s procedures, rather than teaching a baby to speak from birth. An SLM arrives with general language understanding already built in. Fine-tuning adds the specialized knowledge for your specific use case on top of that foundation. You are not training a model from scratch. You are specializing one that already works.
LLMs are designed for breadth and unpredictability. SLMs are built for depth and repetition. That single distinction explains almost every architecture decision that follows.
Small Language Models vs Large Language Models 2026: The Cost Math Nobody on Your Team Has Run
This is where the AI cost reduction enterprise 2026 conversation stops being theoretical.
At one million monthly conversations, hosted frontier LLM costs run $15,000 to $75,000 per month depending on the model and tier, according to Ideas2IT’s 2026 enterprise LLM comparison. For narrow, repeatable, high-volume workflows with sensitive data, a fine-tuned small language model deployed inside your own infrastructure costs $150 to $800 per month at that same volume.
That is not a rounding error. That is a 20x to 100x cost difference for tasks where the small model performs equally well or better.
The training cost picture has shifted just as dramatically. Training frontier LLMs costs more than $100 million, and inference pricing grows steeply at scale, while SLMs reduce cost-per-million queries by over 100 times, according to Label Your Data’s analysis. Even fine-tuning a large model for a new domain can cost tens of thousands of dollars in GPU time. SLMs are far more manageable. Teams can fine-tune a 3 to 7B parameter model for domain-specific tasks at a fraction of that cost, sometimes on a single high-end GPU, the same kind of parallel hardware covered in our breakdown of how GPU parallel computing actually works under the hood for developers building AI infrastructure for the first time.
The barrier that used to justify defaulting to a frontier model API, namely that fine-tuning your own model required serious infrastructure investment, has collapsed. You can fine-tune a 7B parameter model with a single GPU for under $5 and see results in hours, not weeks, per Spheron’s 2026 fine-tuning data. The bar to entry has effectively disappeared, and most teams have not updated their architecture decisions to reflect that.
When a Small Model Actually Beats the Giant One
This is the part most coverage of this trend glosses over, and it is the part that actually matters for an engineering decision.
A fine-tuned small model frequently outperforms the frontier general-purpose model on the specific task it was trained for. This is not a consolation prize for teams on a budget. It is a measurable production outcome, according to MachineLearningMastery’s 2026 analysis.
A documented enterprise customer support deployment saw a 90% cost reduction, three times faster response times, and equal or better accuracy on common questions after switching from a general-purpose frontier model to a fine-tuned small model. Complex queries still escalate to the larger model, but 75% of tickets are now handled entirely by the small one.
The reasoning behind why this happens is straightforward once you think about what each model is optimized for. If you are building a legal document analyzer, a frontier LLM can handle any legal question from corporate law to international treaties. But if you are only processing employment contracts, a fine-tuned 7B model will be faster, cheaper, and more accurate on that specific task, because every parameter in that smaller model is doing work relevant to employment contracts rather than spreading capacity across the entire universe of legal knowledge it was never going to need.
The same logic holds for code completion. Bento ML’s 2026 review of open-source small language models documents a domain-specific fine-tuned coding model achieving a 45% code acceptance rate in production across more than 50 companies, compared to 35% for a general-purpose coding assistant on the same domain-specific codebases. Fine-tune that model further on 10,000 internal examples and acceptance climbs to 55 to 60%.
On graduate-level math and reasoning benchmarks, a 14B parameter small model has actually beaten a frontier model’s score, and it did it running fifteen times faster on local hardware.
This is the uncomfortable truth for teams that have built their entire architecture around a single frontier API call: bigger is not better when the task is narrow. Bigger is just more expensive at being equally good or worse.
The Router Pattern: What the Smart Teams Are Actually Building
The honest answer to the SLM versus LLM question is not a binary choice. It is an architecture pattern, and the teams getting this right in 2026 have converged on roughly the same design.
The pattern showing up across production teams is a split system. Small models handle the predictable bulk of traffic, and only the genuinely difficult cases get escalated up to a frontier model. MachineLearningMastery’s research describes this router pattern as combining the best of both worlds, and the documented split in successful deployments consistently lands around 80% of traffic handled by the small model with 20% escalated to the frontier model for genuinely complex cases.
Building this correctly requires a few specific architectural decisions.
- Classification first. Before a query reaches either model, a lightweight classifier or rules-based router determines whether it falls into a category your SLM has been fine-tuned to handle. This routing layer is itself usually a small model or even simpler logic, adding negligible latency and cost.
- Confidence thresholds, not hard rules. The most resilient implementations do not just route by category. They monitor the small model’s confidence signal on each response and escalate automatically when confidence drops below a defined threshold, regardless of category. This catches edge cases inside a category the small model was not actually trained well enough to handle.
- Continuous retraining on escalated cases. Every query that gets escalated to the frontier model is a signal. Feed those escalated cases back into your fine-tuning pipeline periodically, and the small model’s coverage expands over time, gradually reducing the percentage of traffic that needs the expensive model.
- Edge deployment for latency-sensitive paths. With four-bit quantization, small models in the 1 to 3 billion parameter range fit in under a gigabyte of RAM and run at usable speeds on consumer hardware, including phones. For any path in your application where latency matters more than raw capability, an on-device small model removes the network round trip entirely.
The Global Market Is Already Moving This Direction
This is not a Western enterprise trend happening in isolation. The market data shows a structural shift in production model usage that confirms the direction.
Chinese AI providers, whose flagship strategy leans heavily on efficient, smaller, and aggressively priced models, now account for more than 45% of total weekly token volume on OpenRouter, a major model marketplace, up from under 2% just one year earlier, according to Digital Applied’s Q2 2026 report. The provider with the single largest share of that traffic, a consumer electronics company better known for smartphones, processes more than four trillion weekly tokens for a 21.1% market share, three times OpenAI’s share on the same platform.
The pattern across that shift is consistent: providers competing on cost and efficiency rather than raw benchmark leadership are capturing production volume at a pace that pure intelligence rankings do not predict. Usage and intelligence are decoupling. Developers are optimizing for blended cost per token and specific capabilities like coding throughput, not which model tops a leaderboard.
PyTorch Foundation leadership has made the same observation from the infrastructure side, as reported in IBM’s 2026 AI trends coverage. The industry has validated the thesis that smaller, domain-optimized models would become central, with advances in distillation, quantization, and memory-efficient runtimes pushing inference to edge clusters and embedded devices, driven by cost, latency, and data sovereignty needs.
That last factor, data sovereignty, deserves its own mention. For any team handling regulated or sensitive data, running a small model inside your own infrastructure rather than sending every query to a third-party API is not just a cost decision. It is a compliance and risk posture decision that frontier API usage cannot easily replicate.
What Small Models Genuinely Cannot Do
A blunt guide has to be blunt about the limitations too, because the SLM trend has its own hype cycle building, and overcorrecting toward small models for everything is just as wrong as defaulting to frontier models for everything.
Small models have limited factual knowledge. A small model does not store the breadth of world knowledge a frontier model does, and it will produce inaccurate or outdated facts, especially for knowledge-heavy or long-tail queries outside its fine-tuned domain. Pairing a small model with retrieval-augmented generation or external tool access is close to mandatory for production use outside a narrowly defined task.
Multilingual and cross-domain performance varies significantly. A small model fine-tuned well in English may perform unevenly in other languages, and a model fine-tuned for one domain will generally perform worse than a frontier model on a completely different domain it was never trained for. This is the tradeoff for the depth advantage discussed earlier. You gain accuracy and speed within the lane you fine-tuned for. You lose the generalist flexibility that made the frontier model expensive in the first place.
Format sensitivity is a real engineering constraint. Several widely used small models perform best only when prompts follow specific, documented formatting and function-calling structures, and deviate more noticeably than frontier models when those formats are not followed precisely. This adds engineering overhead that a frontier model’s more forgiving prompt handling does not require.
None of these limitations argue against using small models. They argue against using them carelessly, for the wrong task, without the supporting infrastructure, retrieval, routing, fallback escalation, that makes them production-ready rather than a cost-cutting shortcut that quietly degrades output quality.
A Practical Framework for Deciding Which One You Actually Need
Skip the philosophical debate. Here is the decision framework that actually works when you are staring at a real workload.
Ask whether the task is repeatable at volume. If you are solving the same type of problem thousands of times, with a bounded set of inputs and outputs, that is the textbook case for a fine-tuned small model. If every query could be about a genuinely different topic with no predictable pattern, you need the breadth a frontier model provides.
Ask what your actual latency and cost ceiling is. If you are running customer-facing interactions at meaningful volume and a 20 to 100x cost difference materially changes your unit economics, that gap alone often justifies the engineering investment in a small model pipeline.
Ask whether your data is sensitive enough that keeping inference inside your own infrastructure is a real requirement, not a nice-to-have. Regulated industries, healthcare, finance, legal, frequently have this constraint baked into compliance requirements that make self-hosted small models the only viable architecture regardless of cost.
Ask how much engineering capacity you actually have for the router pattern. A hybrid SLM plus LLM architecture is more capable but it is also more components to build and maintain than a single API call to a frontier model. If your team is evaluating outside help to build this properly rather than in-house, the same due diligence questions covered in our honest framework for evaluating an AI app development company apply directly: ask what they have actually shipped, not what they claim to specialize in.
For the majority of production AI workloads built around a specific, repeated business process, the honest answer in 2026 is that you are very likely overpaying for capability you do not need, and the fix is no longer expensive or technically difficult to implement.
Conclusion: Small Language Models vs Large Language Models 2026 Is Not Actually Close
The default behavior across most engineering teams in 2026 is still reaching for the biggest, most capable model available and routing every request through it regardless of what the task actually requires. That default is expensive, and the data is now unambiguous about how expensive.
The small language models vs large language models 2026 question is not close for the majority of narrow, repeatable production workloads. A fine-tuned small model deployed on infrastructure you control will frequently match or beat a frontier model’s accuracy on the specific task you trained it for, at a fraction of the cost, with the added benefit of keeping sensitive data inside your own systems.
The architecture that wins is not SLM instead of LLM. It is SLM for the predictable majority, with a frontier model held in reserve for the genuinely hard remainder. That hybrid pattern is what the most efficient production AI deployments are already running, and it is the architecture every team still defaulting to a single giant model API call should be building toward right now.