Key Takeaways
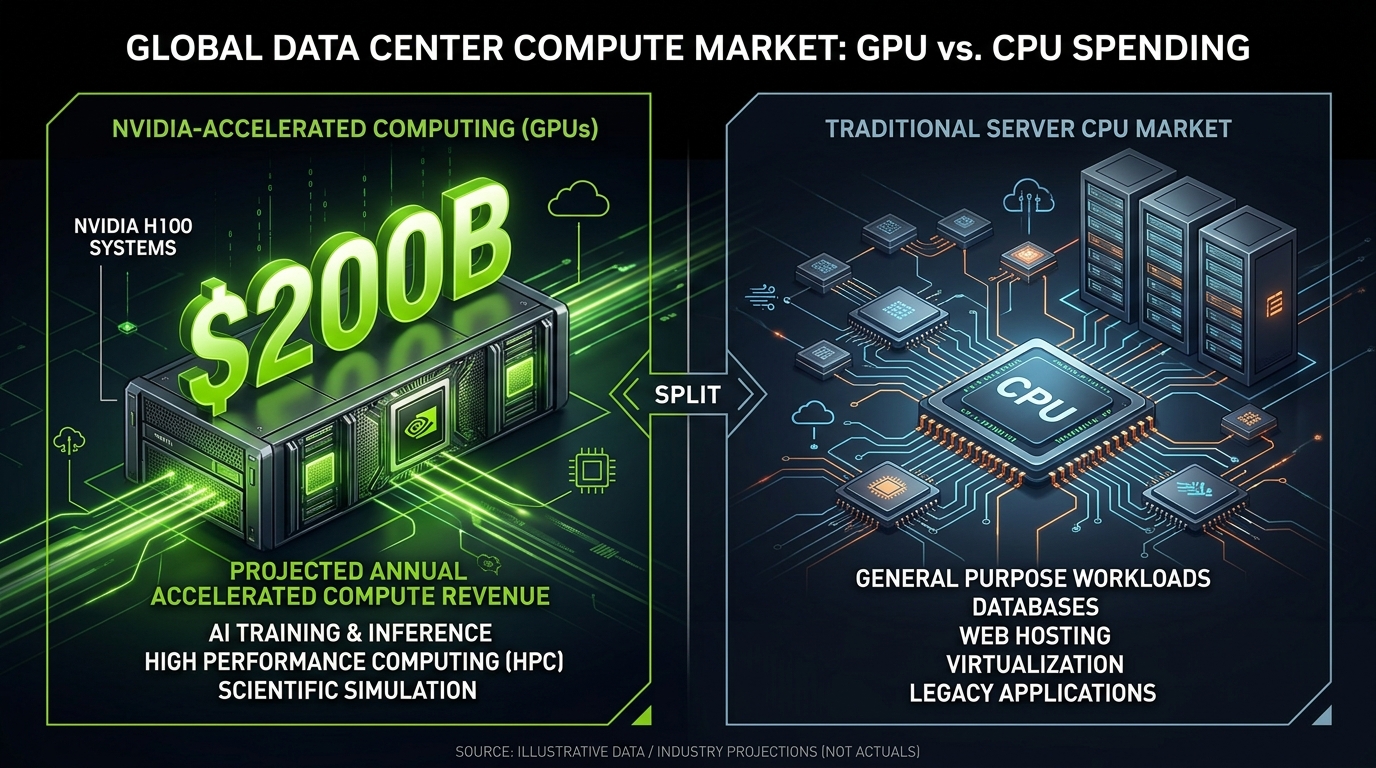
- Nvidia’s Vera CPU is not a GPU upgrade. It is a purpose-built central processor targeting the $200 billion inference and agentic AI workload market that sits entirely outside the company’s existing $1 trillion GPU forecast.
- Jensen Huang expects Vera to become Nvidia’s second largest revenue contributor by the end of fiscal year 2026, with projected revenue hitting $20 billion before the year closes.
- The chip was developed using technology licensed from Groq, a specialized inference startup, in a deal reportedly worth around $17 billion, signaling how seriously Nvidia takes the inference threat.
- Supply is already the binding constraint. Nvidia’s supply commitments jumped from $95.2 billion to $119 billion in a single quarter, driven by demand for Vera Rubin systems before they have even shipped at scale.
- The competitive pressure Vera responds to is real: Google, Amazon, and Microsoft are collectively expected to spend more than $700 billion on AI infrastructure this year, and all three are building their own custom chips specifically to reduce GPU dependence.
Introduction
Nvidia posted Q1 revenue of $81.62 billion. It guided Q2 at $91 billion. Both numbers beat Wall Street expectations by a comfortable margin. The stock barely moved.
That tells you something about where Nvidia is in its story arc. The quarterly beats are priced in. What investors are actually watching now is whether Nvidia can hold its position as the AI compute landscape changes around it. And the most direct answer Jensen Huang gave to that question in his most recent analyst call was not about Blackwell or Rubin. It was about a chip that barely made the headlines.
The Vera CPU. A $200 billion market opportunity. Revenue expected to hit $20 billion before this fiscal year ends.
Huang called it his expected second largest sales contributor. That is not a footnote in an earnings call. That is a strategic declaration about where Nvidia thinks the next phase of AI compute is heading, and what the company intends to do about it before competitors close the gap.
Understanding Vera properly requires understanding what changed in the AI infrastructure market and why a CPU play from Nvidia makes sense right now in a way it would not have three years ago.
Why Nvidia Needs a Second Front
For most of its AI era dominance, Nvidia’s position was built on one core advantage: nobody else could train large AI models at scale without its GPUs. The H100, the A100 before it, and the Blackwell architecture after represent the clearest example of a single company owning a critical bottleneck in an emerging technology stack.
That bottleneck is eroding, specifically on one side of the AI compute equation.
Training vs. Inference: Two Different Problems
AI compute splits into two fundamentally different workloads. Training is the process of building a model, running billions of parameter updates across massive datasets until a model learns to perform a task. Inference is the process of running that trained model in production, generating outputs for users in real time, at scale, repeatedly.
Training still belongs to Nvidia. The GPU parallelism and memory bandwidth that Nvidia hardware delivers is genuinely hard to replicate for training workloads, and nothing from AMD, Intel, Google, or Amazon has demonstrated the ability to displace Nvidia at training scale in a way that enterprise customers have broadly adopted.
Inference is a different story.
Inference workloads have different requirements. They prioritize latency, throughput per watt, and cost per query over the raw parallel compute density that training demands. Custom silicon can be designed around those priorities in ways that general-purpose GPUs were not built for. And the three largest buyers of Nvidia hardware, Google, Amazon, and Microsoft, have all concluded that building their own inference-optimized chips is worth the investment.
Google’s TPU line has been running inference workloads for its own products for years. Amazon’s Trainium and Inferentia chips are now genuinely competitive for specific inference use cases on AWS. Microsoft’s Maia chip program is earlier but backed by serious capital.
The total AI infrastructure spend from these three companies alone is expected to exceed $700 billion in 2026, up from around $400 billion the year prior. A meaningful portion of that capital is going into chip programs designed specifically to reduce their dependence on Nvidia for inference.
This is the competitive dynamic that Vera is designed to address.
What the Vera CPU Actually Is
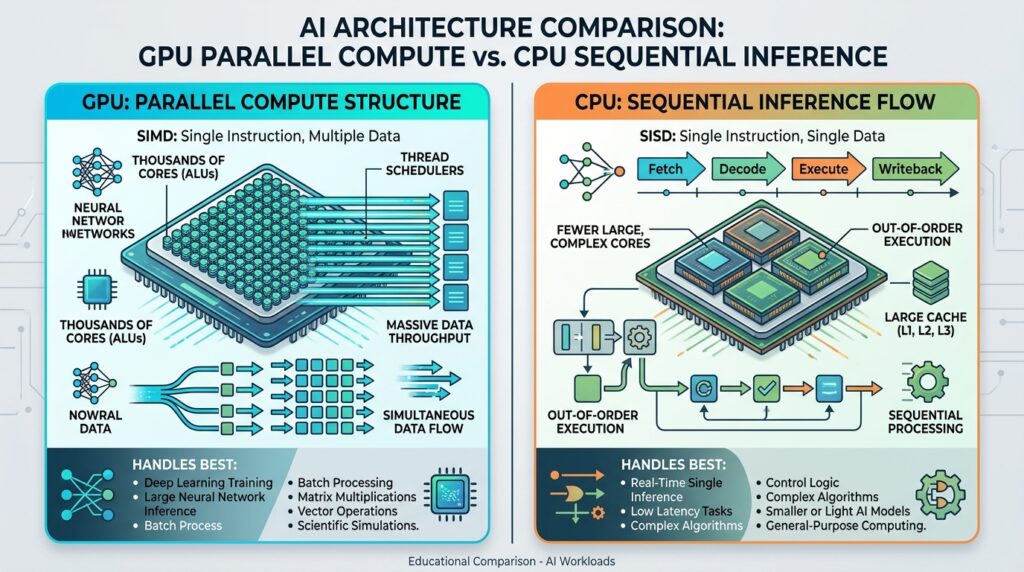
The distinction between a GPU and a CPU matters here and is worth explaining clearly, because Vera is not just another Nvidia chip with a different name.
A GPU, Graphics Processing Unit, is built for massive parallelism. It handles thousands of smaller operations simultaneously, which makes it ideal for the matrix multiplications at the heart of model training. The tradeoff is that GPUs are power-hungry, expensive, and optimized for workloads that benefit from that parallel structure.
A CPU, Central Processing Unit, handles fewer operations at once but does so with much more flexibility, lower latency on individual tasks, and meaningfully better power efficiency for workloads that are more sequential in nature. Inference workloads, particularly agentic AI tasks where a model reasons step by step, retrieves from memory, and coordinates with other systems, often have characteristics that play to CPU strengths rather than GPU strengths.
Vera is built on technology that Nvidia licensed from Groq, a startup that specialized specifically in inference-optimized silicon. The reported value of that licensing deal was approximately $17 billion, a figure that reflects both how valuable the technology is and how seriously Nvidia took the threat of falling behind in inference architecture.
The full product is called the Vera Rubin platform: the Vera CPU paired with Rubin GPUs in a combined system. That combination is designed to handle both the parallel compute demands of complex AI workloads and the sequential, memory-intensive demands of real-time inference and agentic task execution. The full platform is scheduled to ship later in 2026.
The Supply Problem Jensen Huang Did Not Minimize
One of the more notable moments in Nvidia’s Q1 earnings call was Huang’s candor about supply constraints.
“My sense is that we’ll be supply-constrained through the entire life of Vera Rubin,” he told analysts.
For a company positioning a product as a major growth driver, that is an unusually direct admission of a limiting factor. It also reflects something real happening in the global semiconductor supply chain.
The specific bottleneck is high-bandwidth memory, the type of advanced memory that AI chips, including Vera, require in large quantities. Global production of HBM memory is concentrated among a small number of manufacturers, primarily SK Hynix, Samsung, and Micron. Demand from the broader AI chip market has outpaced the expansion of that manufacturing capacity, creating a genuine shortage that is affecting product availability across multiple vendors.
Nvidia’s response has been to commit capital aggressively. Supply commitments rose from $95.2 billion to $119 billion in a single quarter. That is a $24 billion increase in committed spend in roughly 90 days, driven primarily by the need to secure memory and component supply for Vera Rubin systems at a scale that matches expected demand.
The company also announced an $80 billion share repurchase program and raised its quarterly cash dividend from 1 cent to 25 cents per share in the same reporting period. That combination of capital commitment and shareholder return signals strong confidence in the demand trajectory even while acknowledging the supply ceiling.
The question this raises for enterprise customers is practical: if supply is constrained through the entire product life, how does a business that needs Vera Rubin capacity for its AI infrastructure plan around that? It is a real planning challenge, and it is one reason why the alternative chip programs from cloud providers have appeal beyond just cost optimization.
The Competitive Landscape Vera Is Entering
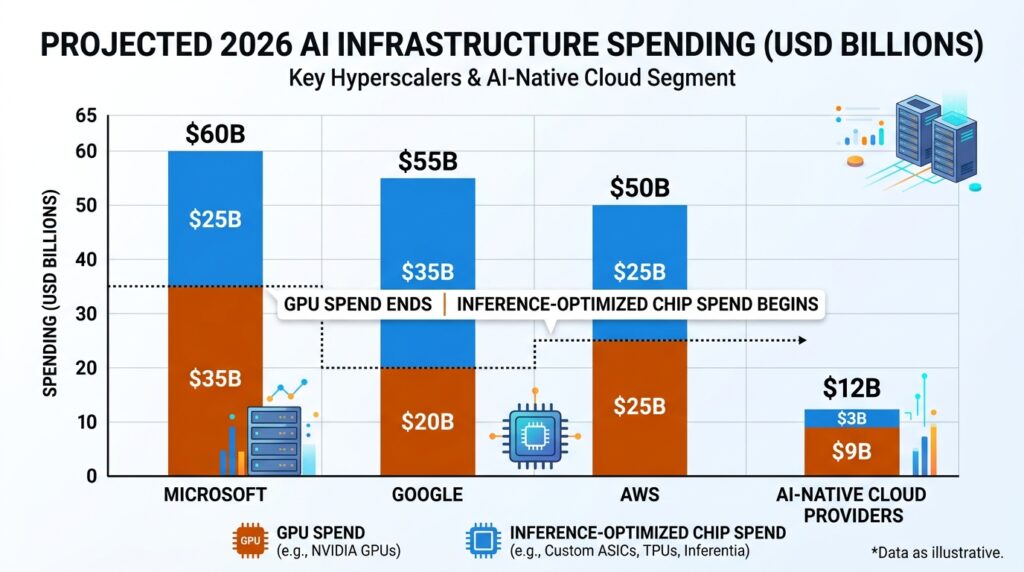
Vera does not arrive into an empty market. It enters a segment where several well-resourced competitors have been building for years.
- AMD’s CPU Play
AMD has been positioning its EPYC CPU line as a credible inference platform for AI workloads, particularly for organizations running open-source models that do not require GPU-level compute for every inference task. AMD’s argument is straightforward: for a large class of inference workloads, a well-configured CPU cluster delivers acceptable performance at a fraction of the cost per query.
- Intel’s Persistent Push
Intel has not had a clean run in the AI accelerator market. Its Gaudi line has struggled to gain the kind of broad adoption that would threaten Nvidia’s position. But Intel’s CPUs remain deeply embedded in enterprise data centers, and the company has been working to make those existing deployments more capable for AI inference through software optimization and architectural improvements.
- Google’s TPU Advantage
Google’s Tensor Processing Units represent the most mature custom inference silicon in the market. TPUs have been running Google’s production AI workloads, including Search, Translate, and the infrastructure underlying Gemini, for years. The performance and cost efficiency data Google has from running TPUs at hyperscale is a significant competitive advantage. When Google offers TPU-based inference capacity through Google Cloud, it is backed by production-validated performance data that Vera, as a newer product, cannot yet match.
- Amazon Trainium and Inferentia
Amazon’s two-chip inference strategy is worth watching. Inferentia handles high-throughput, lower-latency inference for established models. Trainium handles training and more complex inference for newer architectures. Together, they give Amazon a path to reducing its GPU dependency on AWS while offering customers a cost-competitive alternative for inference workloads.
The common thread across all these competitors is that none of them are trying to out-GPU Nvidia. They are competing in the specific workload category where GPU architecture is not the most efficient solution. That is exactly the category Vera is designed to address, which means Nvidia will be competing against specialists who have been focused on this problem longer.
What the Groq Licensing Deal Tells You
The decision to license inference technology from Groq rather than develop it entirely in-house is worth examining, because it reveals something about the timeline pressure Nvidia is operating under.
Groq built a chip architecture specifically designed for fast, efficient inference. Its approach prioritized deterministic performance, meaning predictable latency on every request, over the flexible parallel compute that GPUs offer. That predictability is valuable in production AI systems where inconsistent response times create problems for user experience and system design.
By licensing Groq’s technology rather than building equivalent capability from scratch, Nvidia compressed its development timeline significantly. The $17 billion price tag is substantial. But the alternative, spending three to four years building comparable inference architecture internally while competitors gained ground in the inference market, carried a higher strategic cost.
It also tells you that Nvidia’s own engineers evaluated Groq’s approach and concluded it was worth paying for rather than replicating. That is a meaningful endorsement of the architectural direction.
The AI-Native Cloud Customer: Nvidia’s Fastest Growing Segment
One of the data points from Huang’s analyst call that received less attention than the headline revenue numbers is the emergence of AI-native cloud customers as a distinct and fast-growing segment.
These are companies that were built entirely around AI infrastructure from the start, rather than traditional enterprises or hyperscalers that have added AI capabilities to existing operations. According to Huang, this segment’s spend has reached roughly the same scale as hyperscaler spending, but is growing faster quarter over quarter.
This matters for Vera specifically because AI-native companies are building inference-heavy products from the beginning. They are not optimizing existing workloads for inference. They are building systems where inference is the primary compute demand from day one. Those customers have a strong incentive to adopt purpose-built inference hardware early.
If Vera’s supply constraints can be managed, the AI-native cloud segment represents a customer base that is well-aligned with what Vera is designed to do and is actively growing its compute spend.
What This Means for Enterprise AI Buyers in 2026
For organizations making infrastructure decisions about AI deployment, the Vera announcement changes the conversation in a few specific ways.
Inference costs are about to get more competitive. The entrance of Nvidia into purpose-built inference silicon, alongside the existing competition from AMD, Google, Amazon, and Intel, increases the pressure on all vendors to improve their price-performance ratios. Enterprise buyers who are currently paying GPU-level costs for inference workloads that do not require GPU-level compute should expect that market to get more favorable over the next 12 to 18 months.
Supply planning requires a longer horizon. If Vera is supply-constrained through its product life as Huang suggested, organizations that need guaranteed capacity for AI infrastructure should start conversations with vendors now rather than waiting until procurement cycles require it. The companies that secured H100 allocations early in that chip’s life cycle had a meaningful operational advantage over those who waited.
Not every workload needs a GPU. This is the underlying message of the Vera announcement from an enterprise planning perspective. Mapping AI workload requirements to the right compute class, GPU for training and heavy inference, CPU for agentic tasks and lighter inference loads, becomes a real cost optimization lever as the hardware options mature.
Platform lock-in is a growing consideration. As Nvidia, Google, Amazon, and others develop increasingly integrated AI infrastructure stacks, the switching costs between platforms are rising. Evaluating those lock-in dynamics at the point of adoption, rather than after significant infrastructure has been built, will save organizations substantial renegotiation cost down the line.
Where the AI Chip Market Goes From Here
The Vera announcement is one data point in a market that is restructuring faster than most enterprise planning cycles can track.
The shift from a single-vendor GPU market to a multi-vendor, workload-segmented market is already underway. Training will likely remain Nvidia’s strongest position for the next several years. Inference is contested now and will become more so. Agentic workloads, the category that Vera and Alibaba’s Zhenwu M890 are both targeting, represent a third category that is still early enough that no vendor has established a clear dominant position.
The companies best positioned for the next phase are the ones building infrastructure with workload-specific hardware in mind, rather than defaulting to GPU compute for every AI task. That kind of deliberate architecture requires understanding what each hardware category is actually optimized for, and making procurement decisions that reflect those differences.
Nvidia’s decision to invest heavily in a CPU product, to license external inference technology, and to commit billions in supply chain capital before the product ships at scale reflects the company’s own read on where the market is heading. Jensen Huang does not make $17 billion licensing decisions or $119 billion supply commitments based on optimism. He makes them based on where the demand is going.
The Vera CPU is the evidence that even Nvidia believes the GPU era of AI compute has a ceiling, and the company is building its next floor before the current one shows its limits.
Conclusion
The Vera CPU story is not about Nvidia adding a new product line. It is about Nvidia acknowledging that the next hundred billion dollars in AI compute spending will not all look like the last hundred billion.
GPU dominance in training is real and durable. But inference at scale, particularly as agentic AI workloads grow in volume and complexity, runs on different requirements. Lower latency. Better power efficiency. More predictable performance. Those are CPU strengths, not GPU strengths, and the $200 billion market Huang described is the market where that difference matters most.
Whether Vera captures that market depends on two things that are outside Nvidia’s complete control: whether supply chains cooperate, and whether the competitors who have been building in this space longer, Google, Amazon, AMD, can maintain enough of a cost and performance advantage to keep enterprise customers from defaulting to a familiar Nvidia brand.
The bet is placed. The supply chain is being loaded. And Jensen Huang has made clear that Vera is not the footnote. It is the second act.