Key Takeaways
- Alibaba’s new Zhenwu M890 chip, developed by its semiconductor unit T-Head, is purpose-built for AI agents not just faster inference marking a fundamental shift in how AI hardware is being designed.
- The M890 delivers triple the performance of its predecessor, and Alibaba has committed to two successor chips by 2028, mirroring the kind of sustained product cadence that defines Nvidia’s market dominance.
- The announcement was paired with Qwen 3.7-Max, a large language model engineered for 35-hour continuous agent operation making this a full-stack platform play, not a chip announcement.
- Over 560,000 Zhenwu units have already shipped to 400+ enterprise customers across 20 industries, giving Alibaba real-world scale before the M890 even reaches market.
- The move signals that Chinese tech companies have stopped treating US export restrictions as a logistics problem and started treating semiconductor self-sufficiency as a core long-term strategy.
Table of Contents
Introduction
Most chip announcements follow a predictable script. Bigger numbers. Better benchmarks. A comparison slide against last year’s model. Then everyone moves on.
Alibaba’s Zhenwu M890 announcement is a different kind of move and it deserves a different kind of read.
The M890, built by Alibaba’s semiconductor subsidiary T-Head, isn’t primarily interesting because of its performance specs. It’s interesting because of the design decision embedded underneath those specs. This chip was built from the ground up for AI agents autonomous software systems that need to hold long stretches of context in memory, coordinate with other models in real time, and execute complex multi-step tasks without a human in the loop.
That’s not the workload that most AI accelerators have been optimized for. And that distinction tells you exactly where Alibaba thinks enterprise AI compute is heading over the next several years.
Pair the chip with a confirmed roadmap through 2028, a new frontier model released on the same day, and a $53 billion infrastructure investment already underway, and the picture that emerges isn’t a hardware announcement. It’s a platform declaration.
Why AI Agents Need Different Hardware And Why That Matters Now
To understand why the M890 is architecturally significant, it helps to understand what makes agent workloads different from standard AI inference.
When a model answers a question, the compute demand is relatively bounded. You feed in a prompt, run the forward pass, get an output. That’s what most inference-optimized chips are built for. Fast throughput, efficient parallelism, good performance on dense matrix operations.
AI agents operate differently. Instead of a single prompt-response loop, agents run multi-step reasoning chains. They call tools, retrieve from memory, coordinate with other models, check intermediate results, and loop back until a task is complete. That kind of workload creates different hardware demands.
The Memory Bandwidth Problem
The bottleneck in agent workloads isn’t raw compute — it’s memory bandwidth. Agents have to maintain what’s called a KV (key-value) cache across long context windows: essentially the running memory of everything the model has processed in a given task sequence. The longer the task, the larger the cache. The larger the cache, the more pressure on memory bandwidth.
Standard inference chips can handle short contexts efficiently. But as context length scales into tens of thousands of tokens as it does in real agentic workflows — the performance of chips not designed for this use case degrades significantly. You’re paying for compute you can’t fully use because memory can’t keep up with it.
The M890 is built with that bottleneck specifically in mind. Its architecture prioritizes the memory bandwidth and inter-model communication throughput that agentic workloads actually need, rather than optimizing for the dense parallel throughput that dominates standard benchmark comparisons.
Multi-Model Coordination
There’s a second hardware requirement that agent infrastructure introduces: the ability to handle multiple models working in parallel or in sequence within a single pipeline. Agentic frameworks like multi-agent systems don’t run one model at a time they orchestrate several, with different models handling different subtasks and passing results between each other.
That kind of inter-model communication puts load on network fabric and memory interconnects that single-model inference chips weren’t designed to carry efficiently. Building a chip that treats orchestration as a first-class workload rather than a secondary consideration is what distinguishes purpose-built agent hardware from repurposed inference hardware.
The Roadmap Is the Real Signal
Performance announcements are easy to make and hard to verify. What’s harder to fake is a credible product roadmap with committed ship dates.
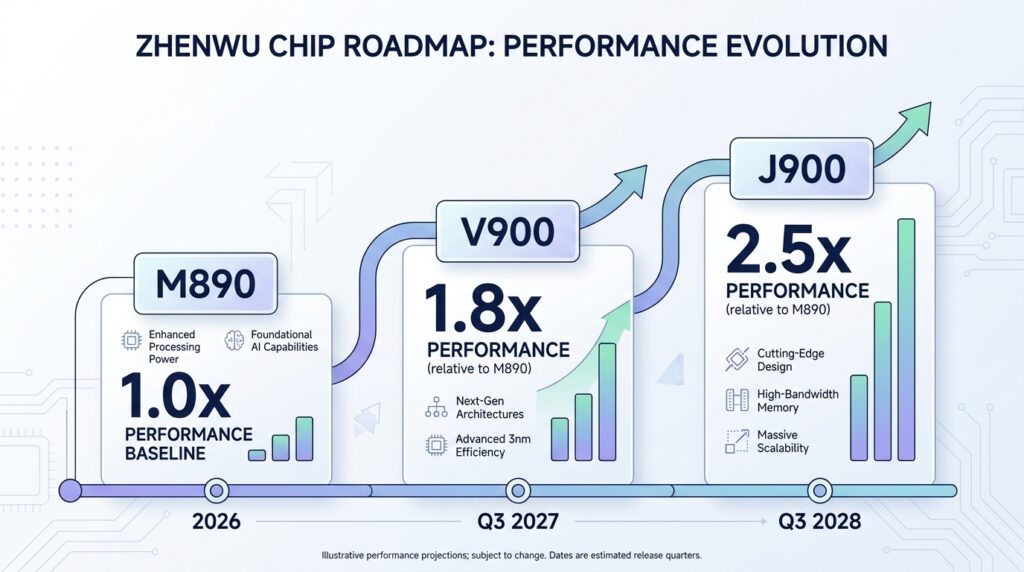
Alibaba put one alongside the M890. The Zhenwu V900 is scheduled for the third quarter of 2027, with another approximately threefold performance gain over the M890. The J900 follows in the third quarter of 2028. That’s a deliberate, multi-year silicon development cadence with public targets attached to it.
This matters for several reasons.
First, it tells customers something about the long-term planning horizon. Enterprise infrastructure decisions aren’t made on the basis of a single chip — they’re made on the basis of whether a vendor will have a viable platform in three to five years. A committed roadmap is a form of commercial trust-building.
Second, it mirrors the tick-tock product cycle that Nvidia has used to maintain its position in AI compute. Nvidia’s dominance isn’t just about the H100 or the Blackwell architecture — it’s about the consistent, predictable generational improvement that lets data centers plan their builds around a known upgrade path. Alibaba is signaling that it’s competing on that dimension, not just the spec sheet.
Third, it reflects a level of organizational investment that can’t be assembled quickly. Building the M890 required years of architectural work, silicon design, process engineering, and supply chain development. The roadmap means that work didn’t stop at the M890 — it’s a continuous program.
Qwen 3.7-Max and the Software Side of the Stack
The hardware announcement was paired with a model release, and that combination is more significant than either piece alone.
Qwen 3.7-Max, the latest version of Alibaba’s flagship large language model, is described as specifically engineered for advanced coding tasks and long-running agent operations. The most telling specification: the model can operate continuously for up to 35 hours without performance degradation.
That’s not a spec that makes sense unless you’re designing for extended autonomous execution. Nobody needs a 35-hour inference session. But a software agent running a complex multi-stage research workflow, an autonomous coding pipeline working through a large codebase, or an enterprise process automation system running overnight those use cases do.
Qwen 3.7-Max isn’t being designed as a standalone chatbot. It’s being designed as the cognitive layer inside agent pipelines that run the M890 as their compute substrate.
The Closed-Loop Platform Logic
This is the part of the announcement that deserves the most attention from a strategic standpoint.
Alibaba is now building a vertically integrated AI stack: T-Head for silicon, Qwen for frontier models, Bailian as the cloud delivery platform, and the Panjiu AL128 server system — which packs 128 M890 accelerators into a single rack — as the enterprise infrastructure package. Every component is Alibaba-built. Every component reinforces the others.
The enterprise customer who runs on this stack is getting optimized silicon running a model tuned for that silicon, delivered through a cloud platform managed by the same vendor. That integration compounds performance in ways that running third-party models on non-native hardware can’t fully match. It also compounds switching costs in ways that enterprise buyers should think carefully about before committing.
This is precisely what Google is doing with TPUs and Gemini, what Amazon is doing with Trainium and Bedrock, and what Microsoft is doing with Azure’s Maia chips and its deep integration with OpenAI. Alibaba’s move is a direct play at the same integrated infrastructure model just built from a Chinese supply chain with Chinese export independence as an explicit design constraint.
The Geopolitical Layer Nobody Can Ignore
The M890 exists in a specific context that shapes its significance, and it would be incomplete to analyze it without addressing that directly.
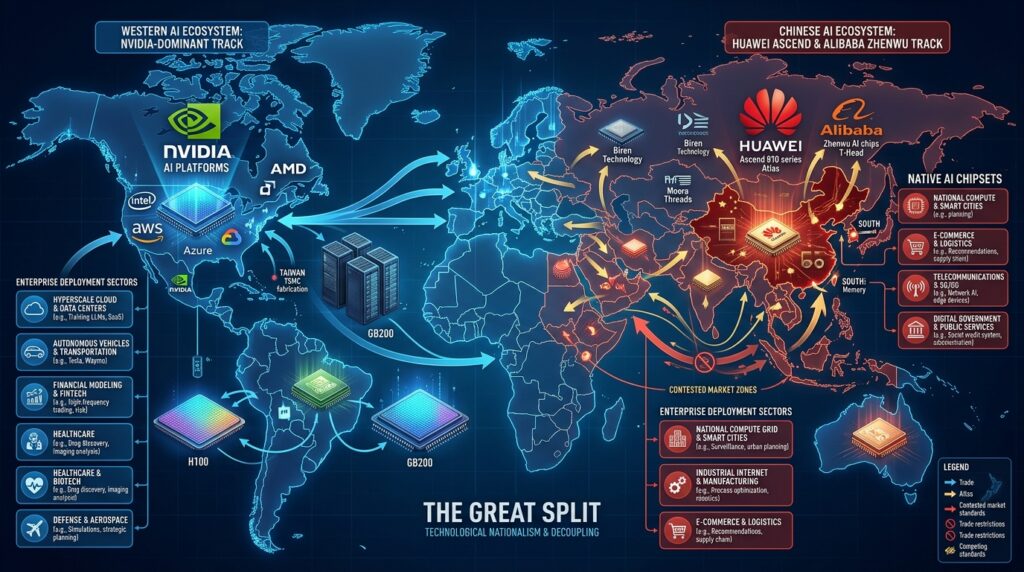
US export controls have progressively restricted access to advanced AI semiconductors for Chinese customers. Nvidia’s H100 chips, the primary workhorses of global AI training and inference infrastructure are effectively unavailable to Chinese buyers at the cutting edge. The H200 situation following the Trump-Xi summit in May 2026 remains unresolved. The controls have been tightened, relaxed, and retightened in ways that make long-term infrastructure planning genuinely difficult for any Chinese organization depending on American silicon.
The response from Chinese tech companies has been consistent: build domestic alternatives, build them at scale, and build them on a long enough roadmap that the capability trajectory converges with global leaders even if it can’t match them today.
Huawei’s Ascend chip program followed this logic. SMIC’s process development followed this logic. The M890 follows this logic. Each announcement is another data point in a sustained program of semiconductor self-sufficiency that has been underway for years and is accelerating.
What This Means for the Global AI Stack
The practical consequence for global technology is that the AI infrastructure market is fragmenting. For most of the last decade, the hardware layer of enterprise AI was essentially unified around Nvidia. Data centers ran the same accelerators regardless of geography.
That’s changing. Chinese enterprises are building on a different silicon stack. As Alibaba’s chips mature and Qwen models deepen their optimization for that hardware, the performance and cost equations for running AI workloads will increasingly diverge between the two ecosystems.
For global enterprises with operations in both China and Western markets, this fragmentation creates complexity. For AI vendors serving both markets, it creates porting and optimization overhead. For governments trying to maintain visibility into AI capabilities, it raises new questions about evaluation and oversight.
The M890 is one chip. But it’s also evidence that the AI hardware race has split into two tracks, and both tracks are now moving fast.
What 560,000 Chips Already Shipped Actually Tells You
There’s a detail in the announcement that doesn’t get enough attention: T-Head has already shipped more than 560,000 Zhenwu units to over 400 enterprise customers across 20 industries, including automotive manufacturers and financial services firms.
That’s not a lab prototype number. That’s a production deployment number. It means T-Head has real-world data at scale on how its chips perform under enterprise workloads, where the failure modes are, and what the support and maintenance requirements look like in practice.
This matters because production-scale deployment is the graveyard of chips that benchmark well but struggle in the field. Heat management behaves differently at rack scale than in a test environment. Memory reliability under sustained load is a different problem than peak performance on a benchmark suite. Supply chain consistency across hundreds of enterprise deployments reveals constraints that small-scale testing never surfaces.
Alibaba comes to the M890 launch with that data in hand. The customer base already exists. The deployment patterns are already understood. The M890 is being introduced into a production ecosystem, not a speculative one.
What This Means for Enterprises and AI Builders
If you’re building AI products or managing enterprise AI infrastructure, the Zhenwu M890 announcement has practical implications that go beyond the China market.
For teams evaluating AI cloud infrastructure: The Alibaba Cloud Bailian platform with M890-backed compute will offer an integrated alternative to AWS Trainium, Google TPU pods, and Azure’s Maia-optimized instances for certain workload classes, particularly long-running agent pipelines. The competitive pressure this creates will affect pricing and roadmap decisions across all major cloud providers.
For AI product teams designing agent architectures: The emergence of purpose-built agent hardware from multiple vendors, not just Alibaba, is a signal that the architecture of AI agents needs to be designed with hardware-level execution in mind, not just model-level performance. Chips are now being shaped around agentic workloads. Product designs should account for that.
For anyone building on open-source Qwen models: Qwen 3.7-Max continues the pattern of Alibaba releasing frontier-class models under permissive licenses. The combination of a capable open model and optimized hardware creates a development environment that’s increasingly competitive with proprietary alternatives.
For enterprise buyers: The platform lock-in dynamics here are real. The deeper an organization builds into the Alibaba stack Qwen on M890 through Bailian the harder it becomes to migrate. Evaluating integrated AI platforms requires accounting for that exit cost upfront, not after the migration has happened.
Where the AI Chip Race Goes From Here
The Zhenwu M890 isn’t the end of this story, it’s a chapter marker in a race that’s just finding its pace.
Nvidia’s next-generation Rubin architecture is on its own roadmap. AMD is deepening its Instinct line. Intel’s Gaudi program continues. And now both Alibaba and Huawei are running sustained chip development programs with committed multi-year roadmaps.
The pattern that emerges from all of this is that the AI hardware market is transitioning from a single dominant vendor model to a genuinely competitive multi-vendor landscape except that competition is happening along geographically separated tracks, with different regulatory environments, different customer bases, and increasingly different technical architectures.
The most significant open question isn’t which chip wins on raw performance. It’s which architectural choices agent-first, inference-first, training-first prove most aligned with how enterprise AI actually evolves over the next three to five years.
Alibaba has made a clear bet. The M890, Qwen 3.7-Max, and the 2028 roadmap all reflect the same conviction: that autonomous agent workloads are the defining use case of the next phase of enterprise AI, and that hardware should be designed around that workload from the start rather than adapted to it after the fact.
That bet may be right. If it is, the company building the silicon specifically for it has a structural advantage that raw compute benchmarks don’t fully capture.
Conclusion
The Zhenwu M890 would be worth paying attention to as a hardware announcement alone. As a platform declaration, it’s worth understanding carefully.
Alibaba isn’t filling a gap left by export controls. It’s building the infrastructure it would have needed to build regardless, because the alternative — permanent dependence on foreign silicon for the workloads that will define enterprise AI was never a viable long-term position.
The M890 is agent-native hardware. Qwen 3.7-Max is agent-native software. The Panjiu AL128 is the rack-scale infrastructure to run both. And the roadmap to 2028 is the commitment that this is a sustained program, not a one-cycle announcement.
For the companies and developers building AI products, the message is the same regardless of geography: the hardware layer of AI is no longer a commodity. The architecture choices being made in silicon today will shape what kinds of AI systems are practical and affordable three years from now. The teams that understand those choices earliest will have a meaningful advantage over the ones who treat infrastructure as an afterthought.
The race changed. The Zhenwu M890 is part of the evidence.