
The AI analysis group Zyphra has just lately unveiled two groundbreaking language fashions, Zamba2-1.2B-Instruct and Zamba2-2.7B-Instruct. These fashions are a part of the Zamba2 sequence and are important developments in pure language processing and AI-based instruction. Zamba2-1.2B-Instruct and Zamba2-2.7B-Instruct are designed to ship enhanced multi-turn chat capabilities and distinctive instruction-following skills, offering cutting-edge options for varied purposes within the AI panorama.
Overview of Zamba2-1.2B-Instruct and Its Capabilities
The Zamba2-1.2B-Instruct mannequin, because the identify suggests, incorporates 1.22 billion parameters, which permits it to deal with complicated pure language duties whereas sustaining an optimized computational footprint. This mannequin is a fine-tuned variant of Zamba2-1.2B-Instruct, leveraging state-of-the-art datasets corresponding to ultrachat_200k and Infinity-Instruct for superior efficiency. The fine-tuning course of features a two-stage methodology: Supervised Fantastic-Tuning (SFT) and Direct Desire Optimization (DPO) of the bottom mannequin checkpoint. The DPO stage employs datasets like ultrafeedback_binarized and OpenHermesPreferences to enhance the mannequin’s means to comply with directions precisely.
Zamba2-1.2B-Instruct contains a distinctive hybrid state-space mannequin (SSM) structure, incorporating state-space components (Mamba2) and transformer blocks. This hybrid construction gives distinctive versatility and computational effectivity. By integrating Mamba2 layers with transformer blocks, Zamba2-1.2B-Instruct achieves fast technology instances and low inference latency, making it appropriate for purposes requiring real-time responses.
Efficiency Benchmarks of Zamba2-1.2B-Instruct
Zamba2-1.2B-Instruct excels in quite a few benchmarks, outperforming bigger fashions in its class. As an example, in MT-Bench and IFEval scores, Zamba2-1.2B-Instruct outshines Gemma2-2B-Instruct, which is greater than twice its dimension, in addition to different aggressive fashions like StableLM-1.6B-Chat and SmolLM-1.7B-Instruct. The hybrid SSM structure contributes considerably to its strong efficiency, offering a balanced trade-off between computational useful resource necessities and output high quality.

The mannequin achieves excessive scores throughout varied analysis metrics, together with an Mixture MT-Bench rating of 59.53 and an IFEval rating of 41.45. These outcomes are spectacular, on condition that the mannequin maintains a compact dimension with a considerably smaller reminiscence footprint than its transformer-only counterparts.
Zamba2-2.7B-Instruct: Pushing the Limits Additional
The discharge of Zamba2-2.7B-Instruct, a bigger and extra superior variant of Zamba2, brings further capabilities and enhancements. With 2.69 billion parameters, this mannequin leverages the identical hybrid structure of Mamba2 state-space components mixed with transformer blocks and introduces enhancements to its consideration mechanisms and general construction. Zamba2-2.7B-Instruct is obtained by fine-tuning Zamba2-2.7B on instruction-following and chat datasets, making it a strong generalist mannequin appropriate for varied purposes.
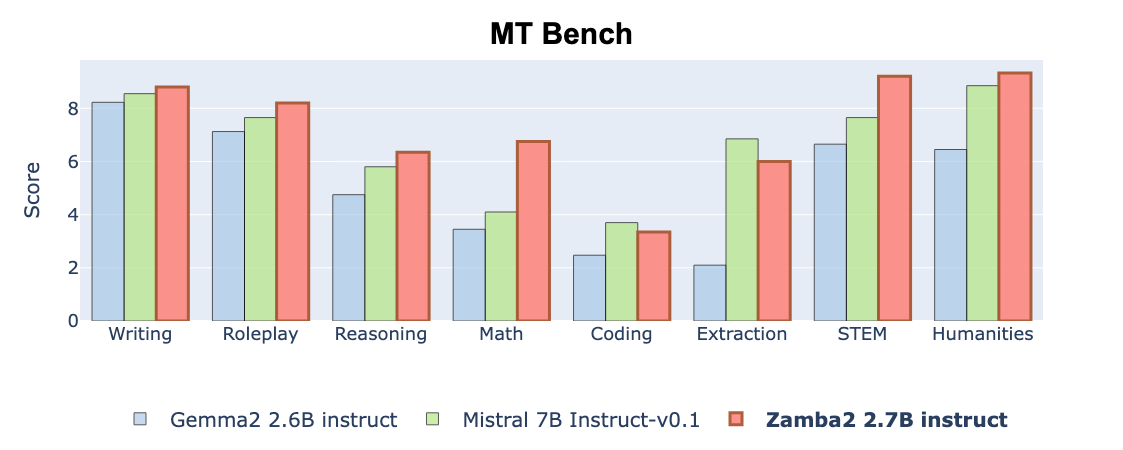
Like its smaller counterpart, Zamba2-2.7B-Instruct makes use of a two-stage finetuning method. The primary stage entails SFT on ultrachat_200k and Infinity-Instruct, whereas the second stage employs DPO on datasets corresponding to orca_dpo_pairs and ultrafeedback_binarized. The fine-tuning course of is tailor-made to boost the mannequin’s efficiency on complicated multi-turn dialogue and instruction-following duties.
Comparative Efficiency Evaluation
Zamba2-2.7B-Instruct demonstrates a considerable efficiency leap over fashions of the same and even bigger dimension. For instance, it achieves an Mixture MT-Bench rating of 72.40 and an IFEval rating of 48.02, considerably outperforming Mistral-7B-Instruct and Gemma2-2B-Instruct, which have Mixture MT-Bench scores of 66.4 and 51.69, respectively. The mannequin’s distinctive hybrid structure ensures decrease inference latency and sooner technology instances, making it a super resolution for on-device purposes the place computational assets are restricted.

Moreover, Zamba2-2.7B-Instruct has a definite benefit relating to Time to First Token (TTFT) and output technology velocity. This effectivity is achieved by using a spine of Mamba2 layers interleaved with shared consideration layers. Zamba2-2.7B-Instruct can preserve efficiency consistency throughout various depths of its structure by minimizing the parameter value of those consideration layers.
Architectural Improvements
Each fashions within the Zamba2 sequence implement modern design decisions that set them aside from others of their class. The spine of the structure consists of Mamba2 layers interleaved with shared consideration layers, minimizing the general parameter value. This hybrid construction and the applying of LoRA projection matrices enable every shared block to specialise in its distinctive place whereas sustaining a comparatively small further parameter overhead.
These design improvements end in highly effective and environment friendly fashions, offering customers with one of the best of each worlds: excessive efficiency and low computational necessities. This makes the Zamba2 sequence notably well-suited for deployment in situations with constrained reminiscence and compute assets, corresponding to cellular and edge units.
Sensible Functions and Future Instructions
With the discharge of Zamba2-1.2B-Instruct and Zamba2-2.7B-Instruct, Zyphra has made important strides in AI-based instruction-following fashions. These fashions have many potential purposes, together with chatbots, private assistants, and different conversational AI methods. Their excessive efficiency and low latency make them splendid for real-time interplay situations, whereas their small reminiscence footprint ensures they are often deployed in resource-constrained environments.
Zyphra plans to proceed creating the Zamba sequence, with future updates prone to embrace additional optimizations and expansions of the hybrid SSM and transformer structure. These developments are anticipated to push what is feasible in pure language understanding and technology, solidifying Zyphra’s place as a pacesetter in AI analysis and improvement.
In conclusion, the discharge of Zamba2-1.2B-Instruct and Zamba2-2.7B-Instruct marks a brand new milestone for Zyphra, providing fashions that mix cutting-edge efficiency with environment friendly use of computational assets. Because the AI discipline continues to evolve, Zyphra’s improvements in hybrid architectures will seemingly function a basis for future developments in AI and pure language processing.
Take a look at the Zyphra/Zamba2-1.2B-instruct and Zyphra/Zamba2-2.7B-instruct. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. In the event you like our work, you’ll love our publication.. Don’t Overlook to affix our 50k+ ML SubReddit
Interested by selling your organization, product, service, or occasion to over 1 Million AI builders and researchers? Let’s collaborate!
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.


