Regardless of their vital contributions to deep studying, LSTMs have limitations, notably in revising saved data. As an example, when confronted with the Nearest Neighbor Search downside, the place a sequence wants to seek out essentially the most related vector, LSTMs wrestle to replace saved values when encountering a better match later within the sequence. This incapacity to revise storage selections hampers their efficiency in duties requiring dynamic changes to saved data. These challenges demand ongoing developments in neural community architectures to handle limitations and enhance mannequin capabilities.
Researchers from the ELLIS Unit, LIT AI Lab, Institute for Machine Studying, JKU Linz, Austria NXAI Lab, Linz, Austria, and NXAI GmbH, Linz, Austria, purpose to boost LSTM language modeling by addressing its limitations. They introduce exponential gating and modify reminiscence buildings to create xLSTM, which might revise saved values effectively, accommodate extra data, and allow parallel processing. Integrating these developments into residual block architectures achieves aggressive efficiency akin to state-of-the-art Transformers and State Area Fashions. Overcoming LSTM’s constraints opens avenues for scaling language fashions to the magnitude of present Massive Language Fashions, probably revolutionizing language understanding and technology duties.
Numerous approaches have emerged to handle the quadratic complexity of consideration mechanisms in Transformers, together with Linear Consideration methods like Synthesizer, Linformer, Linear Transformer, and Performer. State Area Fashions (SSMs) have gained traction for his or her linearity in context size, with fashions like S4, DSS, and BiGS exhibiting promising outcomes. Recurrent Neural Networks (RNNs) with linear items and gating mechanisms have additionally garnered consideration, as seen in fashions like HGRN and RWKV. Covariance replace guidelines, reminiscence mixing, and residual stacking architectures are pivotal elements in enhancing mannequin capabilities, with xLSTM architectures standing as contenders in opposition to Transformers in giant language modeling duties.
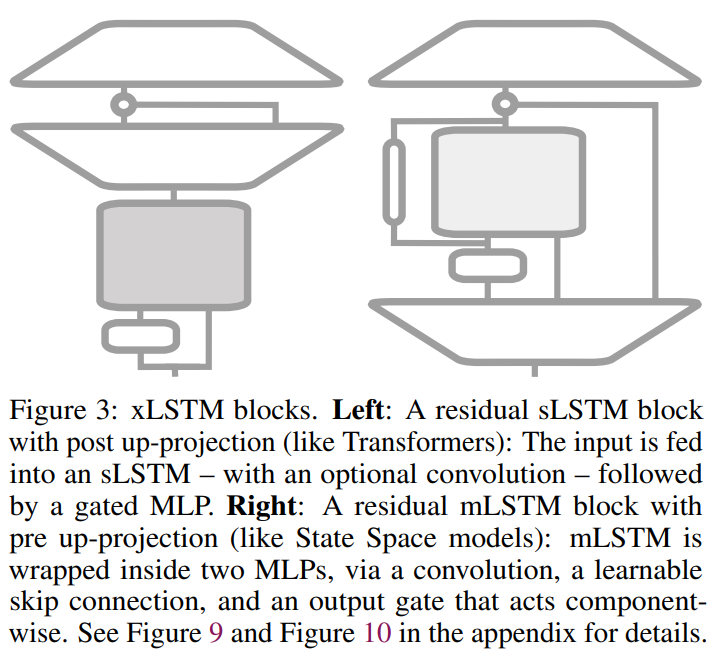
Prolonged Lengthy Quick-Time period Reminiscence (xLSTM) introduces exponential gating and reminiscence buildings to boost LSTM fashions. It presents two variants: sLSTM with scalar reminiscence and replace, that includes reminiscence mixing, and mLSTM with matrix reminiscence and covariance replace rule, which is totally parallelizable. Integration into residual block architectures yields xLSTM blocks, which might summarize previous contexts nonlinearly in high-dimensional areas. xLSTM architectures are constructed by stacking these blocks residually, providing linear computation and fixed reminiscence complexity regarding sequence size. Whereas mLSTM is computationally costly because of its matrix reminiscence, optimizations allow environment friendly parallel processing on GPUs.
Within the experimental analysis of xLSTM for language modeling, artificial duties and efficiency on SlimPajama datasets are investigated. xLSTM’s capabilities are examined on formal languages, associative recall duties, and long-range area eventualities. Comparisons with current strategies reveal xLSTM’s superiority in validation perplexity. Ablation research spotlight the significance of exponential gating and matrix reminiscence in xLSTM’s efficiency. Massive-scale language modeling experiments on 300B tokens additional validate xLSTM’s effectiveness, exhibiting its robustness in dealing with lengthy contexts, downstream duties, and numerous textual content domains. Scaling conduct evaluation suggests xLSTM’s favorable efficiency in comparison with different fashions as dimension will increase.
In conclusion, xLSTM faces limitations, together with slower parallelization than mLSTM, slower CUDA kernels, and computational complexity for matrix reminiscence. Cautious neglect gate initialization is essential, and longer contexts could pressure reminiscence. Regardless of these, xLSTM reveals promise in language modeling, rivaling Transformers, and State Area Fashions. Scaling legal guidelines recommend its potential competitiveness with giant language fashions. Additional optimization is required for bigger xLSTM architectures. General, xLSTM’s improvements in gating and reminiscence buildings place it as a big contender in language modeling and probably different deep studying domains like Reinforcement Studying and Time Sequence Prediction.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to comply with us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
If you happen to like our work, you’ll love our publication..
Don’t Overlook to affix our 42k+ ML SubReddit
Sana Hassan, a consulting intern at Marktechpost and dual-degree scholar at IIT Madras, is captivated with making use of know-how and AI to handle real-world challenges. With a eager curiosity in fixing sensible issues, he brings a recent perspective to the intersection of AI and real-life options.