
Advanced Human Exercise Recognition (CHAR) in ubiquitous computing, significantly in good environments, presents important challenges because of the labor-intensive and error-prone technique of labeling datasets with exact temporal info of atomic actions. This process turns into impractical in real-world eventualities the place correct and detailed labeling is scarce. The necessity for efficient CHAR strategies that don’t depend on meticulous labeling is essential for advancing purposes in healthcare, aged care, surveillance, and emergency response.
Conventional CHAR strategies sometimes require detailed labeling of atomic actions inside particular time intervals to coach fashions successfully. These strategies typically contain segmenting information to enhance accuracy, which is labor-intensive and liable to inaccuracies. In apply, many datasets solely point out the sorts of actions occurring inside particular assortment intervals with out exact temporal or sequential labeling, resulting in combinatorial complexity and potential errors in labeling.
To handle these points, a crew of researchers from Rutgers College suggest the Variance-Pushed Advanced Human Exercise Recognition (VCHAR) framework. VCHAR leverages a generative strategy to deal with atomic exercise outputs as distributions over specified intervals, thus eliminating the necessity for exact labeling. This framework makes use of generative methodologies to supply intelligible explanations for advanced exercise classifications by way of video-based outputs, making it accessible to customers with out prior machine studying experience.
The VCHAR framework employs a variance-driven strategy that makes use of the Kullback-Leibler divergence to approximate the distribution of atomic exercise outputs inside particular time intervals. This methodology permits for the popularity of decisive atomic actions with out the necessity to remove transient states or irrelevant information. By doing so, VCHAR enhances the detection charges of advanced actions even when detailed labeling of atomic actions is absent.
Moreover, VCHAR introduces a novel generative decoder framework that transforms sensor-based mannequin outputs into built-in visible area representations. This consists of visualizations of advanced and atomic actions together with related sensor info. The framework makes use of a Language Mannequin (LM) agent to prepare numerous information sources and a Imaginative and prescient-Language Mannequin (VLM) to generate complete visible outputs. The authors additionally suggest a pretrained “sensor-based basis mannequin” and a “one-shot tuning technique” with masked steerage to facilitate fast adaptation to particular eventualities. Experimental outcomes on three publicly obtainable datasets present that VCHAR performs competitively with conventional strategies whereas considerably enhancing the interpretability and usefulness of CHAR methods.
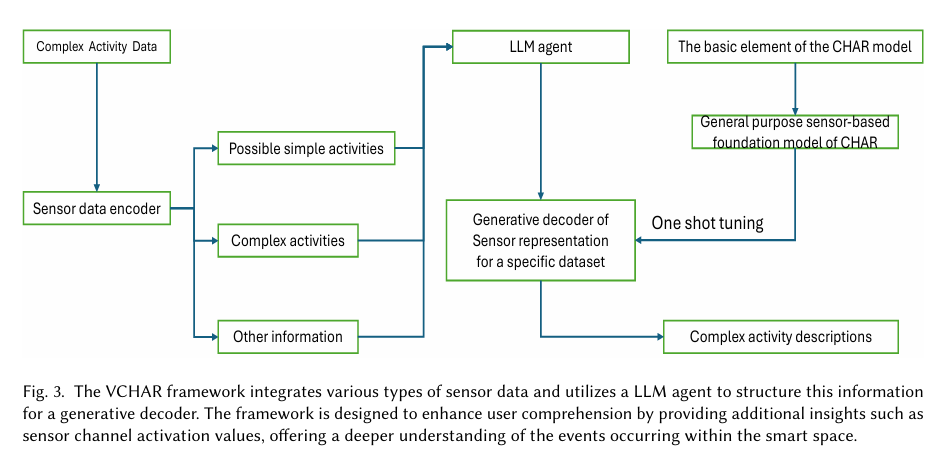
The mixing of a Language Mannequin (LM) and a Imaginative and prescient-Language Mannequin (VLM) permits for the synthesis of complete, coherent visible narratives that characterize the detected actions and sensor info. This functionality not solely aids in higher understanding and belief within the system’s outputs but in addition enhances the power to speak findings to stakeholders who might not have a technical background.
The VCHAR framework successfully addresses the challenges of CHAR by eliminating the necessity for exact labeling and offering intelligible visible representations of advanced actions. This progressive strategy improves the accuracy of exercise recognition and makes the insights accessible to non-experts, bridging the hole between uncooked sensor information and actionable info. The framework’s adaptability, achieved by way of pre-training and one-shot tuning, makes it a promising resolution for real-world good setting purposes that require correct and contextually related exercise recognition and outline.
Try the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to comply with us on Twitter. Be a part of our Telegram Channel and LinkedIn Group.
In case you like our work, you’ll love our publication.. Don’t Overlook to affix our 46k+ ML SubReddit
If You have an interest in a promotional partnership (content material/advert/publication), please fill out this type.
Shreya Maji is a consulting intern at MarktechPost. She is pursued her B.Tech on the Indian Institute of Know-how (IIT), Bhubaneswar. An AI fanatic, she enjoys staying up to date on the newest developments. Shreya is especially within the real-life purposes of cutting-edge expertise, particularly within the area of information science.


