
The fast development of enormous language fashions (LLMs) has catalyzed the event of quite a few NLP functions, comparable to chatbots, writing assistants, and programming aids. Nevertheless, these functions usually require limitless enter size and sturdy reminiscence capabilities, which present LLMs lack. Extending pre-training textual content size is impractical, necessitating analysis into enabling LLMs to deal with infinite enter lengths whereas preserving reminiscence. Current research give attention to enhancing LLMs’ enter context size, primarily by way of optimizing consideration mechanisms. Strategies like Sliding-window consideration and StreamLLM intention to increase enter size however undergo from consideration sink and reminiscence loss points, prompting exploration into filtering much less essential tokens to take care of longer reminiscence spans.
Quite a few research have targeted on extending the enter context size of LLMs by refining the eye mechanism. Some strategies like Sliding window consideration, which limits every token to attend solely to latest tokens, guarantee secure decoding velocity. Different strategies like fastened Sparse Transformer and LogSparse self-attention have been proposed to protect native context data and improve world consideration. StreamLLM was launched to attain true infinite enter size by sustaining give attention to each preliminary and up to date tokens. Nevertheless, present approaches face challenges like token preservation and forgetting points.
Researchers from Shanghai Jiao Tong College and Wuhan College current Streaming Infinite Retentive LLM (SirLLM), a mannequin enabling LLMs to take care of prolonged reminiscence in infinite-length dialogues with out requiring fine-tuning. SirLLM makes use of the Token Entropy metric and reminiscence decay mechanism to filter key phrases, enhancing LLMs’ long-lasting and adaptable reminiscence. Three duties and datasets have been designed to evaluate SirLLM’s effectiveness comprehensively: DailyDialog, Grocery Buying, and Rock-Paper-Scissors.
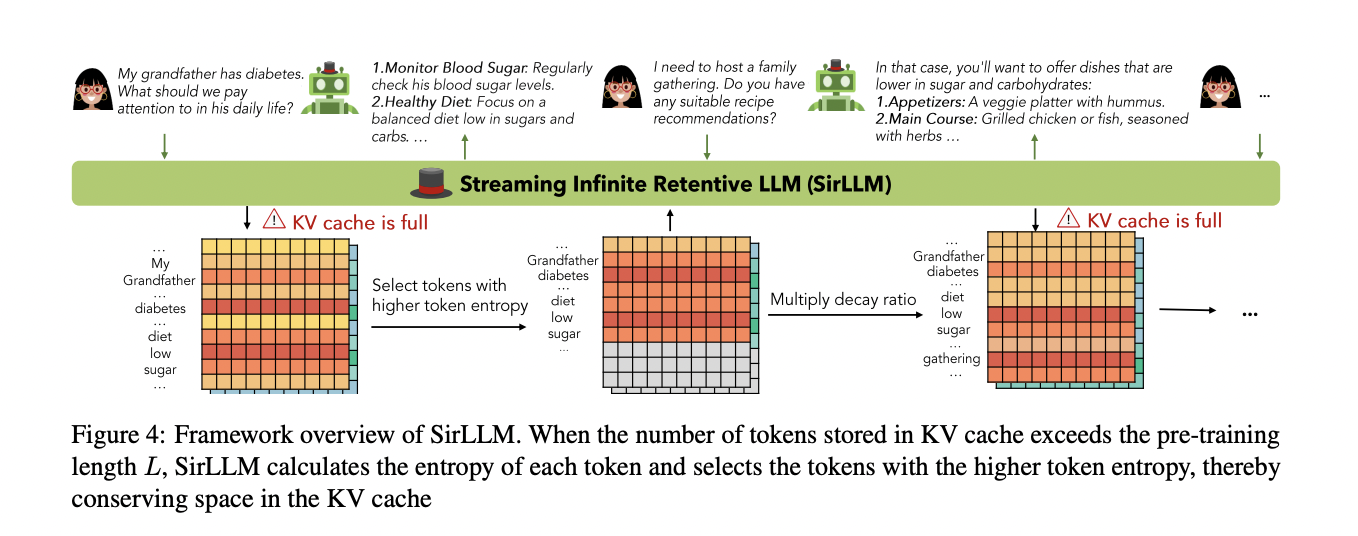
Entropy values for every token are used to reinforce the mannequin’s reminiscence functionality by selectively preserving the key-value states of solely the important thing tokens, resulting in the proposal of SirLLM. The framework overview of SirLLM entails sustaining each a key-value (KV) cache and a token entropy cache. When the variety of tokens saved within the KV cache exceeds the pre-training size L, SirLLM calculates the entropy of every token and selects tokens with greater entropy, thus conserving area within the KV cache. That is achieved by choosing the highest ok tokens with the very best token entropy. Larger token entropy implies a decrease likelihood of phrase era, indicating key tokens with extra data. SirLLM additionally adjusts token positions throughout the cache for relative distances, specializing in cache positions slightly than
authentic textual content positions. Nevertheless, preserving tokens solely primarily based on entropy can result in a inflexible reminiscence throughout the mannequin, hindering adaptability. To beat this, a decay ratio ηdecay lower than 1 is proposed, permitting the mannequin to overlook older key data after every spherical of dialogue, thereby enhancing flexibility and person expertise.
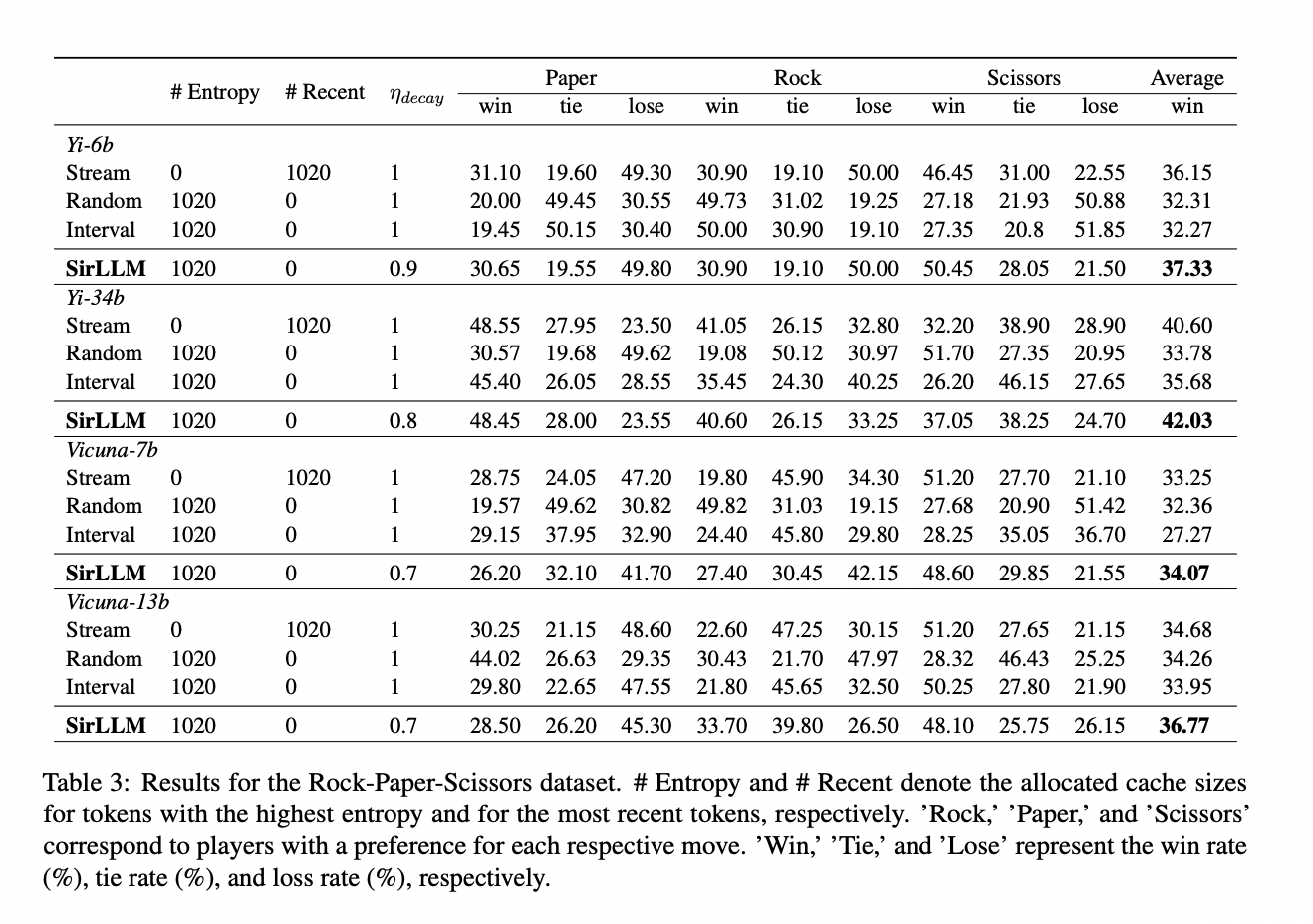
Evaluation of the Rock-Paper-Scissors dataset demonstrates SirLLM’s constant outperformance in comparison with the baseline StreamLLM throughout gamers with various throwing preferences. SirLLM displays a gradual enchancment in win charges towards gamers of varied preferences, sustaining this elevated efficiency persistently throughout all evaluated fashions. The built-in decay mechanism in SirLLM contributes considerably to sustaining balanced efficiency over a number of rounds, as evidenced by uniformly elevated win charges. This attribute is especially advantageous in situations involving extended interactions like prolonged Rock-Paper-Scissors video games, highlighting SirLLM’s capability to adapt and recall earlier strikes, important for fulfillment.
Introducing SirLLM, this research addresses the vital challenges of managing infinite enter lengths and reminiscence functionality. SirLLM achieves lengthy dialogue retention with out requiring mannequin fine-tuning by selectively reinforcing the give attention to pivotal data. Throughout three tailor-made duties: DailyDialog, Grocery Buying, and Rock-Paper-Scissors, SirLLM persistently demonstrates secure enchancment over present fashions, no matter dialogue complexity or size. Experimental outcomes validate SirLLM’s robustness and flexibility, positioning it as a precious asset for future explorations and functions in pure language processing.
Try the Paper and Github. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to observe us on Twitter. Be a part of our Telegram Channel, Discord Channel, and LinkedIn Group.
If you happen to like our work, you’ll love our e-newsletter..
Don’t Overlook to affix our 42k+ ML SubReddit
Asjad is an intern advisor at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the functions of machine studying in healthcare.


