
Unlocking the potential of huge multimodal language fashions (MLLMs) to deal with numerous modalities like speech, textual content, picture, and video is an important step in AI improvement. This functionality is important for functions reminiscent of pure language understanding, content material suggestion, and multimodal data retrieval, enhancing the accuracy and robustness of AI techniques.
Conventional strategies for dealing with multimodal challenges typically depend on dense fashions or single-expert modality approaches. Dense fashions contain all parameters in each computation, resulting in elevated computational overhead and decreased scalability because the mannequin dimension grows. Alternatively, single-expert approaches lack the flexibleness and flexibility required to successfully combine and comprehend numerous multimodal information. These strategies typically battle with complicated duties that contain a number of modalities concurrently, reminiscent of understanding lengthy speech segments or processing intricate image-text combos.
The researchers from Harbin Institute of Know-how have proposed the revolutionary Uni-MoE strategy, which leverages a Combination of Specialists (MoE) structure together with a strategic three-phase coaching technique. Uni-MoE optimizes professional choice and collaboration, permitting modality-specific specialists to work synergistically to boost mannequin efficiency. The three-phase coaching technique contains specialised coaching phases for cross-modality information, which improves mannequin stability, robustness, and flexibility. This new strategy not solely overcomes the drawbacks of dense fashions and single-expert approaches but in addition demonstrates vital developments within the capabilities of multimodal AI techniques, significantly in dealing with complicated duties that contain numerous modalities.
Uni-MoE’s technical developments embody a MoE framework specializing in several modalities and a three-phase coaching technique for optimized collaboration. Superior routing mechanisms allocate enter information to related specialists, optimizing computational assets, whereas auxiliary balancing loss strategies guarantee equal professional significance throughout coaching. These intricacies make Uni-MoE a sturdy answer for complicated multimodal duties.
Outcomes showcase Uni-MoE’s superiority with accuracy scores starting from 62.76% to 66.46% throughout analysis benchmarks like ActivityNet-QA, RACE-Audio, and A-OKVQA. It outperforms dense fashions, displays higher generalization, and handles lengthy speech understanding duties successfully. Uni-MoE’s success marks a big leap ahead in multimodal studying, promising enhanced efficiency, effectivity, and generalization for future AI techniques.
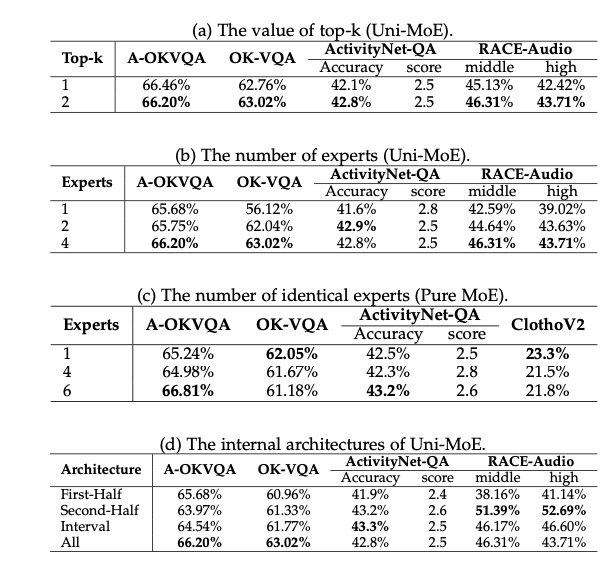
In conclusion, Uni-MoE represents a big leap ahead within the realm of multimodal studying and AI techniques. Its revolutionary strategy, leveraging a Combination of Specialists (MoE) structure and a strategic three-phase coaching technique, addresses the constraints of conventional strategies and unlocks enhanced efficiency, effectivity, and generalization throughout numerous modalities. The spectacular accuracy scores achieved on varied analysis benchmarks, together with ActivityNet-QA, RACE-Audio, and A-OKVQA, underscore Uni-MoE’s superiority in dealing with complicated duties reminiscent of lengthy speech understanding. This groundbreaking know-how not solely overcomes present challenges but in addition paves the way in which for future developments in multimodal AI techniques, reaffirming its pivotal function in shaping the way forward for AI know-how.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to observe us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
In the event you like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our 42k+ ML SubReddit
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Know-how, Kharagpur. He’s captivated with information science and machine studying, bringing a robust tutorial background and hands-on expertise in fixing real-life cross-domain challenges.


