
Within the quickly advancing area of synthetic intelligence, the environment friendly operation of enormous language fashions (LLMs) on consumer-level {hardware} represents a big technical problem. This difficulty arises from the inherent trade-off between the fashions’ dimension and computational effectivity. Compression strategies, together with direct and multi-codebook quantization (MCQ), have supplied partial options to attenuate these AI behemoths’ reminiscence necessities. Nonetheless, these approaches usually compromise mannequin efficiency, leaving a spot for innovation in excessive mannequin compression methods.
A pioneering technique known as Additive Quantization for Language Fashions (AQLM) by researchers from HSE College, Yandex Analysis, Skoltech, IST Austria, and NeuralMagic targeted on minimizing this trade-off goal by lowering the bit depend per mannequin parameter to an astonishingly low vary of two to three bits. This technique adopts and refines additive quantization, a way beforehand confined to data retrieval for the particular challenges of LLM compression.
AQLM distinguishes itself by preserving and, in some situations, enhancing the accuracy of compressed fashions, significantly in situations demanding excessive compression. That is achieved by a novel two-pronged method that features the discovered additive quantization of weight matrices in a way that adapts to enter variability and a complicated joint optimization of codebook parameters throughout layer blocks. This twin technique propels AQLM to the forefront of LLM compression applied sciences, setting new requirements within the area.
One of many standout options of AQLM is its sensible applicability throughout numerous {hardware} platforms. The researchers behind AQLM have supplied implementations demonstrating the tactic’s effectiveness on GPU and CPU architectures, making certain its utility in real-world purposes. This practicality is underpinned by an in depth analysis of up to date compression methods, the place AQLM constantly surpasses its opponents. It shines particularly in excessive compression settings, demonstrating a exceptional skill to attenuate mannequin dimension with out degrading efficiency. That is evidenced by AQLM’s superior efficiency in metrics similar to mannequin perplexity and accuracy in zero-shot duties, highlighting its effectivity in sustaining the integrity of the compressed mannequin.
The comparative evaluation of AQLM in opposition to different main compression methodologies reveals its distinctive place within the panorama of LLM compression. In contrast to different approaches that usually require a compromise between mannequin dimension and accuracy, AQLM maintains or improves efficiency throughout a spectrum of metrics. This benefit is especially evident in excessive compression, the place AQLM units new benchmarks in effectivity and effectiveness. The tactic’s success on this area is a testomony to the progressive method taken by the researchers, combining discovered additive quantization with joint optimization methods to attain unparalleled outcomes.
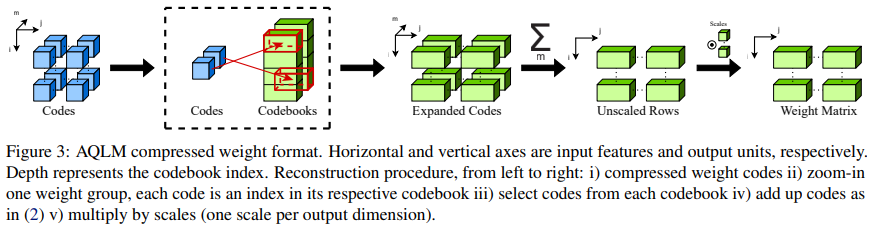
In conclusion, AQLM emerges as a groundbreaking method within the quest for environment friendly compression of LLMs. By addressing the crucial problem of lowering the mannequin dimension with out sacrificing accuracy, AQLM paves the way in which for deploying superior AI capabilities on a broader array of units. Its progressive use of additive quantization tailor-made to LLMs and the tactic’s sensible implementations on numerous {hardware} platforms mark a big development in making AI extra accessible. The spectacular efficiency of AQLM, validated by rigorous evaluations, positions it as a beacon of innovation in LLM compression.
Take a look at the Paper and Github. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to comply with us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
For those who like our work, you’ll love our publication..
Don’t Neglect to affix our 38k+ ML SubReddit
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Environment friendly Deep Studying, with a deal with Sparse Coaching. Pursuing an M.Sc. in Electrical Engineering, specializing in Software program Engineering, he blends superior technical data with sensible purposes. His present endeavor is his thesis on “Bettering Effectivity in Deep Reinforcement Studying,” showcasing his dedication to enhancing AI’s capabilities. Athar’s work stands on the intersection “Sparse Coaching in DNN’s” and “Deep Reinforcemnt Studying”.


