
The efficacy of deep reinforcement studying (RL) brokers critically relies on their capability to make the most of community parameters effectively. Latest insights have forged mild on deep RL brokers’ challenges, notably their tendency to underutilize community parameters, resulting in suboptimal efficiency. This inefficiency will not be merely a technical hiccup however a basic bottleneck that curtails the potential of RL brokers in advanced domains.
The issue is the necessity for extra utilization of community parameters by deep RL brokers. Regardless of the exceptional successes of deep RL in numerous purposes, proof suggests these brokers usually fail to harness the total potential of their community’s capability. This inefficiency manifests in dormant neurons throughout coaching and an implicit underparameterization, resulting in a major efficiency hole in duties requiring intricate reasoning and decision-making.
Whereas pioneering, present methodologies within the area grapple with this problem to various levels of success. Sparse coaching strategies have proven promise, which goals to streamline community parameters to important ones. Nevertheless, these strategies usually result in a trade-off between sparsity and efficiency with out essentially addressing the basis reason for parameter underutilization.
The examine by researchers from Google DeepMind, Mila – Québec AI Institute, and Université de Montréal introduces a groundbreaking method often called gradual magnitude pruning, which meticulously trims down the community parameters, guaranteeing that solely these of paramount significance are retained. This method is rooted within the understanding that dormant neurons and underutilized parameters considerably hamper the effectivity of a community. This phenomenon restricts the agent’s studying capability and inflates computational prices with out commensurate advantages. By making use of a principled technique to extend community sparsity steadily, the analysis unveils an unseen scaling regulation, demonstrating that considered pruning can result in substantial efficiency positive aspects throughout numerous duties.
Networks subjected to gradual magnitude pruning constantly outperformed their dense counterparts throughout a spectrum of reinforcement studying duties. This was not restricted to easy environments however prolonged to advanced domains requiring refined decision-making and reasoning. The tactic’s efficacy was significantly pronounced when conventional dense networks struggled, underscoring the potential of pruning to unlock new efficiency ranges in deep RL brokers.
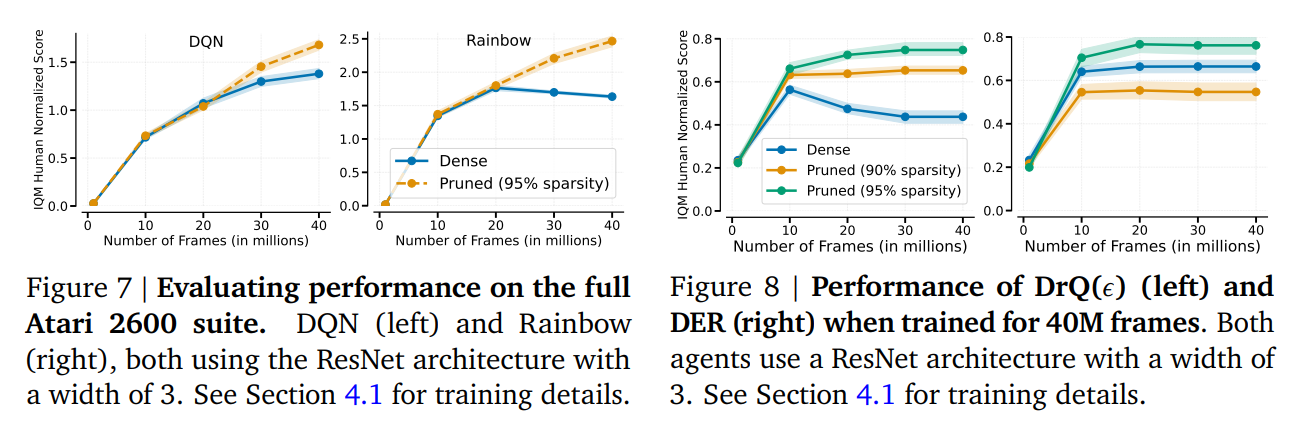
By considerably decreasing the variety of lively parameters, gradual magnitude pruning presents a sustainable path towards extra environment friendly and cost-effective reinforcement studying purposes. This method aligns with making AI applied sciences extra accessible and decreasing their environmental affect, a consideration of accelerating significance within the area.
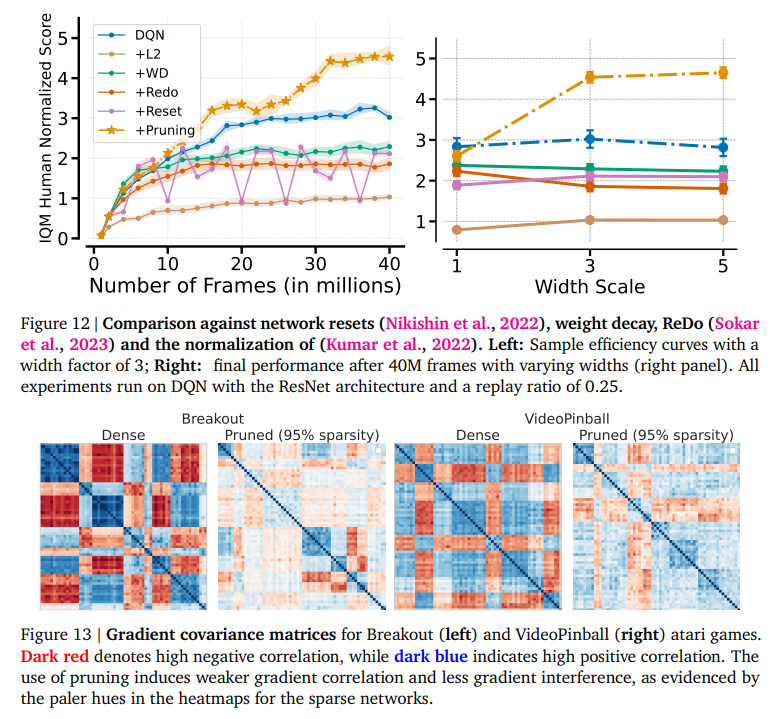
In conclusion, the contributions of this analysis are manifold, providing new views on optimizing deep RL brokers:
- Introduction of gradual magnitude pruning: A novel method that maximizes parameter effectivity, resulting in vital efficiency enhancements.
- Demonstration of a scaling regulation: Unveiling the connection between community measurement and efficiency, difficult the prevailing notion that greater networks are inherently higher.
- Proof of common applicability: Exhibiting the method’s effectiveness throughout numerous brokers and coaching regimes, suggesting its potential as a common technique for enhancing deep RL brokers.
- Alignment with sustainability objectives: Proposing a path in the direction of extra environmentally pleasant and cost-effective AI purposes by decreasing computational necessities.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to comply with us on Twitter and Google Information. Be part of our 38k+ ML SubReddit, 41k+ Fb Group, Discord Channel, and LinkedIn Group.
In the event you like our work, you’ll love our publication..
Don’t Overlook to hitch our Telegram Channel
You may additionally like our FREE AI Programs….
Hey, My identify is Adnan Hassan. I’m a consulting intern at Marktechpost and shortly to be a administration trainee at American Specific. I’m at present pursuing a twin diploma on the Indian Institute of Expertise, Kharagpur. I’m enthusiastic about know-how and wish to create new merchandise that make a distinction.


