
Giant Language Fashions (LLMs) have demonstrated outstanding capabilities throughout a variety of pure language processing (NLP) duties, corresponding to machine translation and question-answering. Nonetheless, a big problem stays in understanding the theoretical underpinnings of their efficiency. Particularly, there’s a lack of a complete framework that explains how LLMs generate contextually related and coherent sequences of textual content. This problem is compounded by limitations corresponding to fastened vocabulary dimension and context home windows, which constrain the complete comprehension of the token sequences LLMs can course of. Addressing this problem is important to optimize LLMs’ effectivity and increase their real-world applicability.
Earlier research have targeted on the empirical success of LLMs, significantly these constructed on the transformer structure. Whereas these fashions carry out properly in duties involving sequential token technology, current analysis has both simplified their architectures for theoretical evaluation or uncared for the temporal dependencies inherent in token sequences. This limits the scope of their findings and leaves gaps in our understanding of how LLMs generalize past their coaching knowledge. Furthermore, no framework has efficiently derived theoretical generalization bounds for LLMs when dealing with temporally dependent sequences, which is essential for his or her broader utility in real-world duties.
A workforce of researchers from ENS Paris-Saclay, Inria Paris, Imperial School London, and Huawei Noah’s Ark Lab introduces a novel framework by modeling LLMs as finite-state Markov chains, the place every enter sequence of tokens corresponds to a state, and transitions between states are decided by the mannequin’s prediction of the subsequent token. This formulation captures the complete vary of attainable token sequences, offering a structured option to analyze LLM conduct. By formalizing LLMs via this probabilistic framework, the examine affords insights into their inference capabilities, particularly the stationary distribution of token sequences and the velocity at which the mannequin converges to this distribution. This method represents a big development in understanding how LLMs operate, because it gives a extra interpretable and theoretically grounded basis.
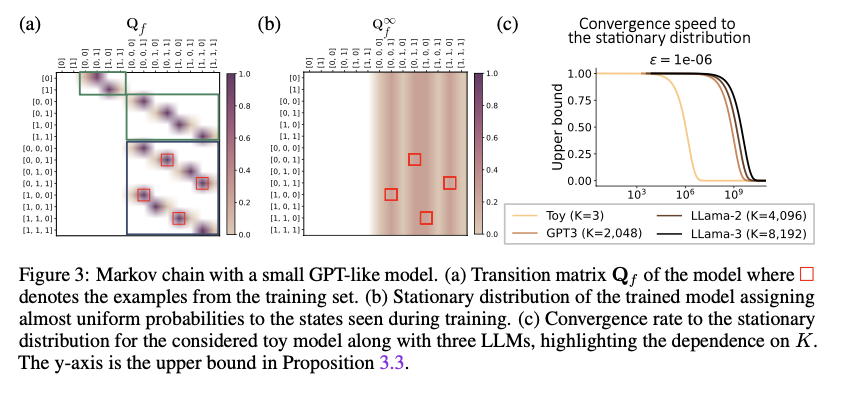
This methodology constructs a Markov chain illustration of LLMs by defining a transition matrix Qf, which is each sparse and block-structured, capturing the mannequin’s potential output sequences. The dimensions of the transition matrix is O(T^okay), the place T is the vocabulary dimension, and Ok is the context window dimension. The stationary distribution derived from this matrix signifies the LLM’s long-term prediction conduct throughout all enter sequences. The researchers additionally discover the affect of temperature on the LLM’s means to traverse the state house effectively, displaying that greater temperatures result in quicker convergence. These insights have been validated via experiments on GPT-like fashions, confirming the theoretical predictions.
Experimental analysis on varied LLMs confirmed that modeling them as Markov chains results in extra environment friendly exploration of the state house and quicker convergence to a stationary distribution. Greater temperature settings notably improved the velocity of convergence, whereas fashions with bigger context home windows required extra steps to stabilize. Moreover, the framework outperformed conventional frequentist approaches in studying transition matrices, particularly for giant state areas. These outcomes spotlight the robustness and effectivity of this method in offering deeper insights into LLM conduct, significantly in producing coherent sequences relevant to real-world duties.
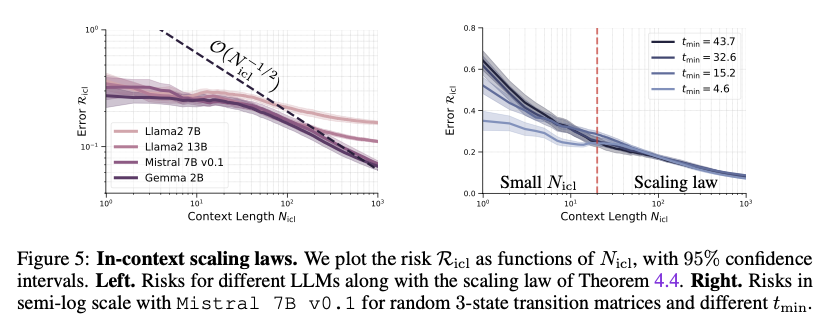
This examine presents a theoretical framework that fashions LLMs as Markov chains, providing a structured method to understanding their inference mechanisms. By deriving generalization bounds and experimentally validating the framework, the researchers reveal that LLMs are extremely environment friendly learners of token sequences. This method considerably enhances the design and optimization of LLMs, main to raised generalization and improved efficiency throughout a variety of NLP duties. The framework gives a strong basis for future analysis, significantly in analyzing how LLMs course of and generate coherent sequences in numerous real-world purposes.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. In the event you like our work, you’ll love our publication.. Don’t Neglect to affix our 50k+ ML SubReddit
[Upcoming Event- Oct 17 202] RetrieveX – The GenAI Knowledge Retrieval Convention (Promoted)
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Know-how, Kharagpur. He’s obsessed with knowledge science and machine studying, bringing a robust educational background and hands-on expertise in fixing real-life cross-domain challenges.


