
The exploration of pure language processing has been revolutionized with the appearance of LLMs like GPT. These fashions showcase distinctive language comprehension and era talents however encounter important hurdles. Their static information base usually challenges them, resulting in outdated info and response inaccuracies, particularly in eventualities demanding domain-specific insights. This hole requires modern methods to bridge the constraints of LLMs, guaranteeing their sensible applicability and reliability in numerous, knowledge-intensive duties.
The normal strategy has fine-tuned LLMs with domain-specific information to handle these challenges. Whereas this methodology can yield substantial enhancements, it has drawbacks. It necessitates a excessive useful resource funding and specialised experience, limiting its adaptability to the consistently evolving info panorama. This strategy can’t dynamically replace the mannequin’s information base, which is important for dealing with quickly altering or extremely specialised content material. These limitations level in the direction of the necessity for a extra versatile and dynamic methodology to reinforce LLMs.
Researchers from Tongji College, Fudan College, and Tongji College have offered a survey on Retrieval-Augmented Era (RAG), an modern methodology developed by researchers to reinforce the capabilities of LLMs. This strategy ingeniously merges the mannequin’s parameterized information with dynamically accessible, non-parameterized exterior information sources. RAG first identifies and extracts related info from exterior databases in response to a question. The retrieved information types the muse upon which the LLM generates its responses. This course of enriches the mannequin’s reactions with present and domain-specific info and considerably diminishes the prevalence of hallucinations, a typical concern in LLM responses.
Delving deeper into RAG’s methodology, the method begins with a classy retrieval system that scans by way of intensive exterior databases to find info pertinent to the question. This technique is finely tuned to make sure the relevance and accuracy of the knowledge being sourced. As soon as the related information is recognized, it’s seamlessly built-in into the LLM’s response era course of. The LLM, now geared up with this freshly sourced info, is healthier positioned to provide responses that aren’t solely correct but in addition up-to-date, addressing the inherent limitations of purely parameterized fashions.
The efficiency of RAG-augmented LLMs has been exceptional. A major discount in mannequin hallucinations has been noticed, straight enhancing the reliability of the responses. Customers can now obtain solutions that aren’t solely rooted within the mannequin’s intensive coaching information but in addition supplemented with essentially the most present info from exterior sources. This facet of RAG, the place the sources of the retrieved info could be cited, provides a layer of transparency and trustworthiness to the mannequin’s outputs. RAG’s capacity to dynamically incorporate domain-specific information makes these fashions versatile and adaptable to numerous purposes.
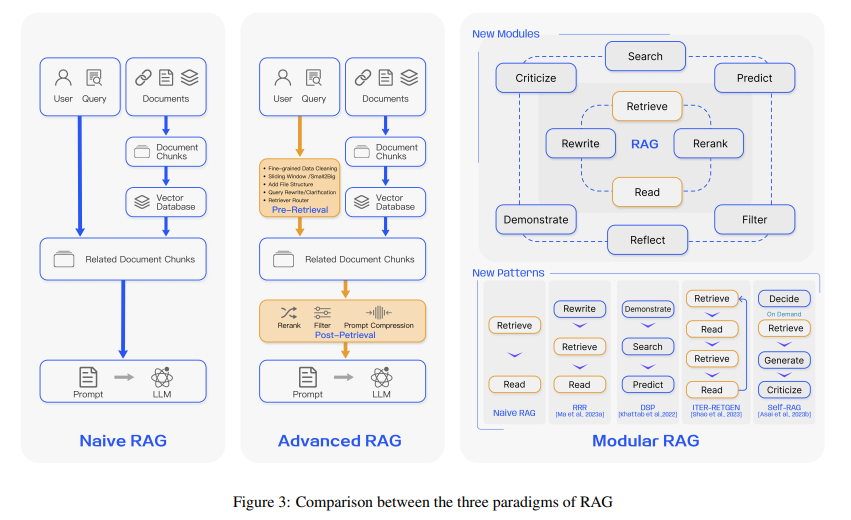
In a nutshell:
- RAG represents a groundbreaking strategy in pure language processing, addressing important challenges LLMs face.
- By bridging parameterized information with exterior, non-parameterized information, RAG considerably enhances the accuracy and relevance of LLM responses.
- The tactic’s dynamic nature permits for incorporating up-to-date and domain-specific info, making it extremely adaptable.
- RAG’s efficiency is marked by a notable discount in hallucinations and elevated response reliability, bolstering consumer belief.
- The transparency afforded by RAG, by way of supply citations, additional establishes its utility and credibility in sensible purposes.
This exploration into RAG’s position in augmenting LLMs underlines its significance and potential in shaping the way forward for pure language processing, opening new avenues for analysis and growth on this dynamic and ever-evolving discipline.
Take a look at the Paper and Github. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to hitch our 35k+ ML SubReddit, 41k+ Fb Neighborhood, Discord Channel, LinkedIn Group, and Electronic mail Publication, the place we share the newest AI analysis information, cool AI initiatives, and extra.
For those who like our work, you’ll love our publication..
Hi there, My identify is Adnan Hassan. I’m a consulting intern at Marktechpost and shortly to be a administration trainee at American Specific. I’m at the moment pursuing a twin diploma on the Indian Institute of Expertise, Kharagpur. I’m obsessed with expertise and wish to create new merchandise that make a distinction.


