
Query answering (QA) is a vital space in pure language processing (NLP), specializing in creating techniques that may precisely retrieve and generate responses to person queries from intensive information sources. Retrieval-augmented era (RAG) enhances the standard and relevance of solutions by combining data retrieval with textual content era. This strategy filters out irrelevant data and presents solely probably the most pertinent passages for big language fashions (LLMs) to generate responses.
One of many fundamental challenges in QA is the restricted scope of present datasets, which frequently use single-source corpora or concentrate on brief, extractive solutions. This limitation hampers evaluating how nicely LLMs can generalize throughout totally different domains. Present strategies comparable to Pure Questions and TriviaQA rely closely on Wikipedia or net paperwork, that are inadequate for assessing cross-domain efficiency. Consequently, there’s a important want for extra complete analysis frameworks that may take a look at the robustness of QA techniques throughout varied domains.
Researchers from AWS AI Labs, Google, Samaya.ai, Orby.ai, and the College of California, Santa Barbara, have launched Lengthy-form RobustQA (LFRQA) to deal with these limitations. This new dataset includes human-written long-form solutions that combine data from a number of paperwork into coherent narratives. Overlaying 26,000 queries throughout seven domains, LFRQA goals to judge the cross-domain generalization capabilities of LLM-based RAG-QA techniques.
LFRQA distinguishes itself from earlier datasets by providing long-form solutions grounded in a corpus, guaranteeing coherence, and protecting a number of domains. The dataset consists of annotations from varied sources, making it a precious instrument for benchmarking QA techniques. This strategy addresses the shortcomings of extractive QA datasets, which frequently fail to seize the excellent and detailed nature of contemporary LLM responses.
The analysis group launched the RAG-QA Enviornment framework to leverage LFRQA for evaluating QA techniques. This framework employs model-based evaluators to instantly examine LLM-generated solutions with LFRQA’s human-written solutions. By specializing in long-form, coherent solutions, RAG-QA Enviornment offers a extra correct and difficult benchmark for QA techniques. In depth experiments demonstrated a excessive correlation between model-based and human evaluations, validating the framework’s effectiveness.
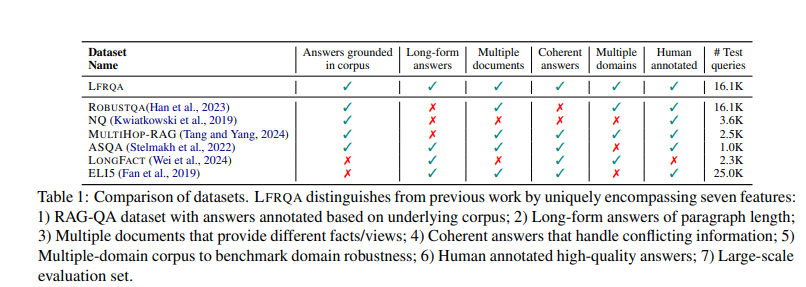
The researchers employed varied strategies to make sure the prime quality of LFRQA. Annotators had been instructed to mix brief extractive solutions into coherent long-form solutions, incorporating extra data from the paperwork when essential. High quality management measures included random audits of annotations to make sure completeness, coherence, and relevance. This rigorous course of resulted in a dataset that successfully benchmarks the cross-domain robustness of QA techniques.
Efficiency outcomes from the RAG-QA Enviornment framework present important findings. Solely 41.3% of solutions generated by probably the most aggressive LLMs had been most well-liked over LFRQA’s human-written solutions. The dataset demonstrated a robust correlation between model-based and human evaluations, with a correlation coefficient of 0.82. Moreover, the analysis revealed that LFRQA solutions, which built-in data from as much as 80 paperwork, had been most well-liked in 59.1% of circumstances in comparison with main LLM solutions. The framework additionally highlighted a 25.1% hole in efficiency between in-domain and out-of-domain information, emphasizing the significance of cross-domain analysis in creating sturdy QA techniques.
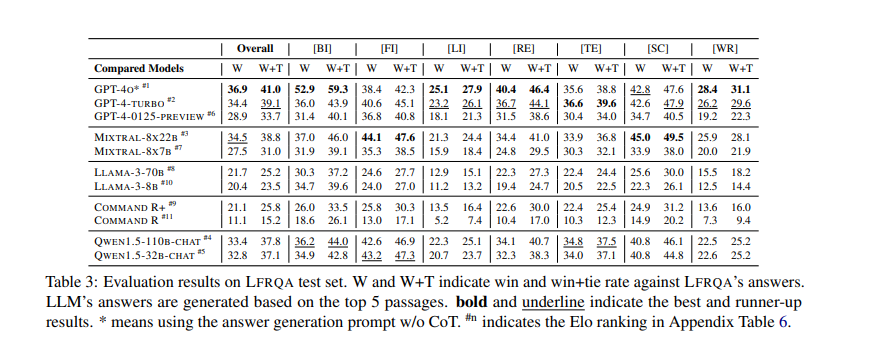
Along with its complete nature, LFRQA consists of detailed efficiency metrics that present precious insights into the effectiveness of QA techniques. For instance, the dataset comprises details about the variety of paperwork used to generate solutions, the coherence of these solutions, and their fluency. These metrics assist researchers perceive the strengths and weaknesses of various QA approaches, guiding future enhancements.
In conclusion, the analysis led by AWS AI Labs, Google, Samaya.ai, Orby.ai, and the College of California, Santa Barbara, highlights the restrictions of present QA analysis strategies and introduces LFRQA and RAG-QA Enviornment as modern options. These instruments supply a extra complete and difficult benchmark for assessing the cross-domain robustness of QA techniques, contributing considerably to the development of NLP and QA analysis.
Try the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. For those who like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our 47k+ ML SubReddit
Discover Upcoming AI Webinars right here
Nikhil is an intern marketing consultant at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching functions in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.



