
Giant language fashions (LLMs) are designed to know and handle complicated language duties by capturing context and long-term dependencies. A essential issue for his or her efficiency is the power to deal with long-context inputs, which permits for a deeper understanding of content material over intensive textual content sequences. Nonetheless, this benefit comes with the disadvantage of elevated reminiscence utilization, as storing and retrieving contextual info from earlier inputs can eat substantial computational sources.
Reminiscence consumption in LLMs is primarily attributed to storing key-value (KV) pairs throughout autoregressive inference. In such a state of affairs, the mannequin should repeatedly entry these saved pairs for each new token it generates. Because the sequence size will increase, the reminiscence necessities develop exponentially, making it impractical for deployment in lots of {hardware} environments. This drawback is additional exacerbated when LLMs are utilized to long-context duties, the place your entire sequence should be preserved in reminiscence for correct predictions. Consequently, decreasing the reminiscence footprint of LLMs has turn into an pressing want for optimizing their efficiency in real-world purposes.
Conventional approaches for managing reminiscence utilization in LLMs contain complicated algorithms or fine-tuning methods tailor-made to particular person mannequin architectures. These strategies usually embody post-hoc compression of the KV cache by analyzing consideration scores or introducing adjustments to the mannequin itself. Whereas efficient, such methods are restricted by their complexity and the necessity for extra computational sources. Furthermore, a few of these approaches are incompatible with trendy consideration mechanisms like FlashAttention, that are designed to enhance reminiscence effectivity. Subsequently, researchers have explored new efficient and simply adaptable methods for varied LLMs.
Researchers from the College of Edinburgh and Sapienza College of Rome proposed a novel strategy for KV cache compression that’s easier and extra environment friendly than present options. This technique leverages the correlation between the L2 norm of key embeddings and the corresponding consideration scores, enabling the mannequin to retain solely probably the most impactful KV pairs. In contrast to prior strategies that require extra coaching or intricate modifications, this strategy is non-intrusive and could be carried out immediately on any transformer-based, decoder-only LLM. By protecting solely the KV pairs with the bottom L2 norm, the researchers demonstrated that the mannequin might cut back its reminiscence footprint whereas sustaining excessive accuracy.
The methodology is rooted within the commentary that key embeddings with decrease L2 norm values are usually related to greater consideration scores throughout decoding. This means that such embeddings are extra influential in figuring out the mannequin’s output. Subsequently, retaining solely these key embeddings and their corresponding values permits the mannequin to compress its KV cache considerably with out shedding essential info. This technique is especially advantageous because it doesn’t depend on calculating consideration scores, making it suitable with varied consideration mechanisms, together with FlashAttention. Furthermore, it may be utilized to any present mannequin with out intensive retraining or architectural adjustments, broadening its applicability.
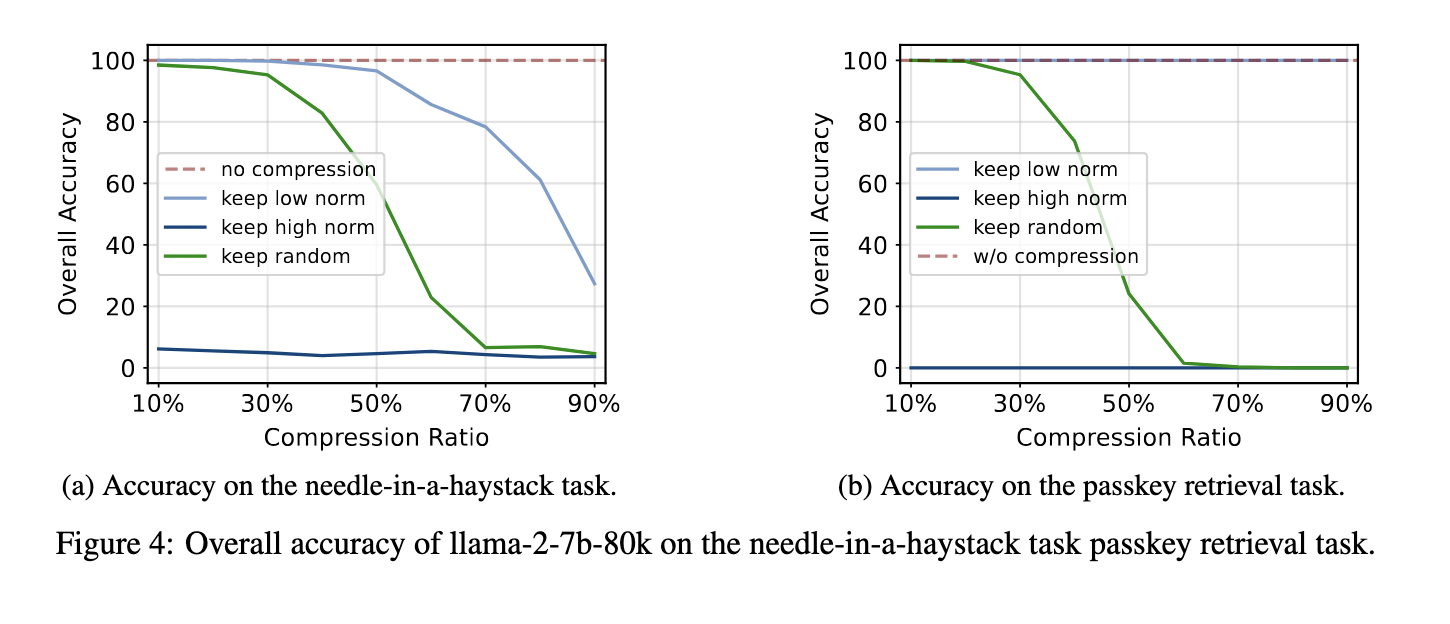
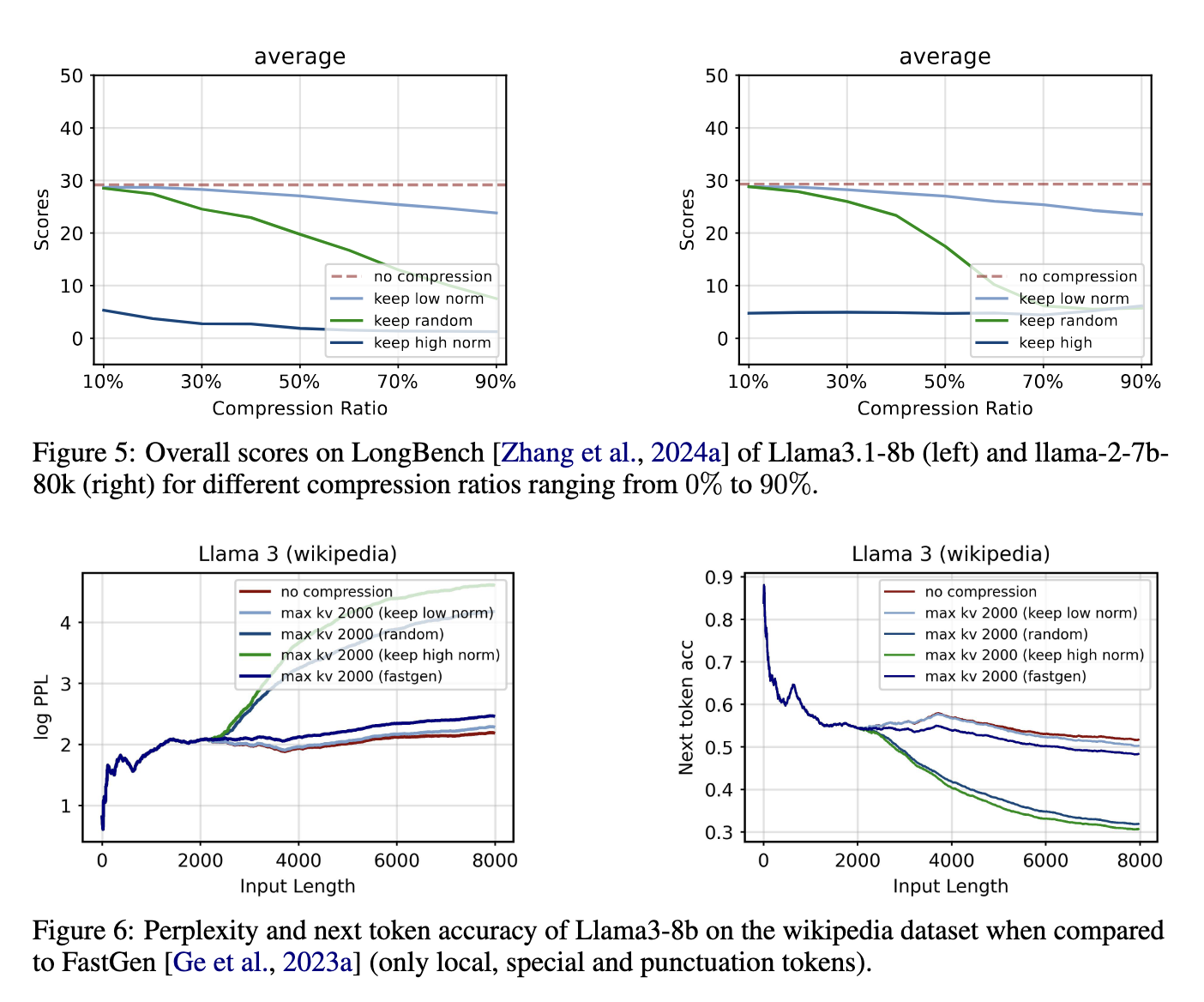
Relating to efficiency, the proposed technique yields exceptional outcomes throughout varied duties. Experimental evaluations confirmed that compressing the KV cache utilizing the L2 norm technique decreased reminiscence utilization by as much as 50% normally language modeling duties, with no important influence on mannequin perplexity or accuracy. For duties that require retrieving particular info from lengthy contexts, such because the passkey retrieval process, the mannequin achieved 100% accuracy even when compressing 90% of the KV cache. These outcomes spotlight the effectiveness of the compression technique in sustaining mannequin efficiency whereas considerably decreasing the reminiscence necessities.
Moreover, the tactic demonstrated sturdy efficiency on difficult long-context duties just like the needle-in-a-haystack take a look at, the place the mannequin must determine and retrieve essential info from a big quantity of information. On this state of affairs, the mannequin maintained 99% accuracy when compressing 50% of the KV cache, a testomony to the reliability of the compression technique. In comparison with present strategies like FastGen, which depend on consideration scores for compression, the L2 norm-based technique offers an easier and extra adaptable resolution. The outcomes additionally point out that discarding KV pairs with excessive L2 norm values harms efficiency, as these pairs usually correspond to much less informative embeddings.
In conclusion, the researchers from the College of Edinburgh and Sapienza College of Rome have offered an progressive resolution to a longstanding drawback in LLM deployment. Their L2 norm-based compression technique gives a sensible approach to handle LLMs’ reminiscence consumption with out compromising efficiency. This strategy is flexible, suitable with varied mannequin architectures, and simply implementable, making it a beneficial contribution to LLMs. As LLMs evolve and deal with more and more complicated duties, such memory-efficient methods will allow broader adoption throughout completely different industries and purposes.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. In the event you like our work, you’ll love our publication..
Don’t Overlook to hitch our 50k+ ML SubReddit.
We’re inviting startups, corporations, and analysis establishments who’re engaged on small language fashions to take part on this upcoming ‘Small Language Fashions’ Journal/Report by Marketchpost.com. This Journal/Report shall be launched in late October/early November 2024. Click on right here to arrange a name!
Nikhil is an intern marketing consultant at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching purposes in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


