
Synthetic intelligence (AI) has considerably superior with the event of huge language fashions (LLMs) that comply with consumer directions. These fashions goal to offer correct and related responses to human queries, usually requiring fine-tuning to boost their efficiency in numerous functions, akin to customer support, data retrieval, and content material era. The flexibility to instruct these fashions exactly has grow to be a cornerstone of contemporary AI, pushing the boundaries of what these techniques can obtain in sensible situations.
One of many challenges in growing and evaluating instruction-following fashions is the inherent size bias. This bias arises as a result of human evaluators and coaching algorithms favor longer responses, resulting in fashions that generate unnecessarily prolonged outputs. This choice complicates the evaluation of mannequin high quality and effectiveness, as longer responses are solely generally extra informative or correct. Consequently, the problem is to develop fashions that perceive directions and guarantee they will generate responses of applicable size.
Present strategies to handle the size bias embody incorporating size penalties into analysis benchmarks. As an illustration, AlpacaEval and MT-Bench have built-in these penalties to counteract the fashions’ tendency to provide longer responses. Moreover, numerous fine-tuning methods, akin to reinforcement studying with human suggestions (RLHF), are employed to optimize fashions for higher instruction-following capabilities. These strategies goal to refine the fashions’ skill to generate concise but complete responses, balancing the size and high quality of the output.
Researchers from Meta FAIR and New York College have launched a novel method referred to as Size-Instruction Fantastic-Tuning (LIFT), which includes augmenting coaching information with express size directions. This methodology allows fashions to be managed at inference time to stick to specified size constraints. The analysis crew, together with Meta FAIR and New York College members, designed this method to mitigate the size bias and enhance the fashions’ adherence to length-specific directions. The fashions study to respect these constraints throughout real-world functions by incorporating detailed directions into the coaching information.
The LIFT methodology incorporates Direct Choice Optimization (DPO) to fine-tune fashions utilizing datasets enhanced with size directions. This course of begins with augmenting a standard instruction-following dataset by inserting size constraints into the prompts. The strategy constructs choice pairs that replicate each size constraints and response high quality. These augmented datasets are then used to fine-tune fashions, akin to Llama 2 and Llama 3, making certain they will deal with prompts with and with out size directions. This systematic method permits the fashions to study from numerous directions, enhancing their skill to generate correct and appropriately concise responses.
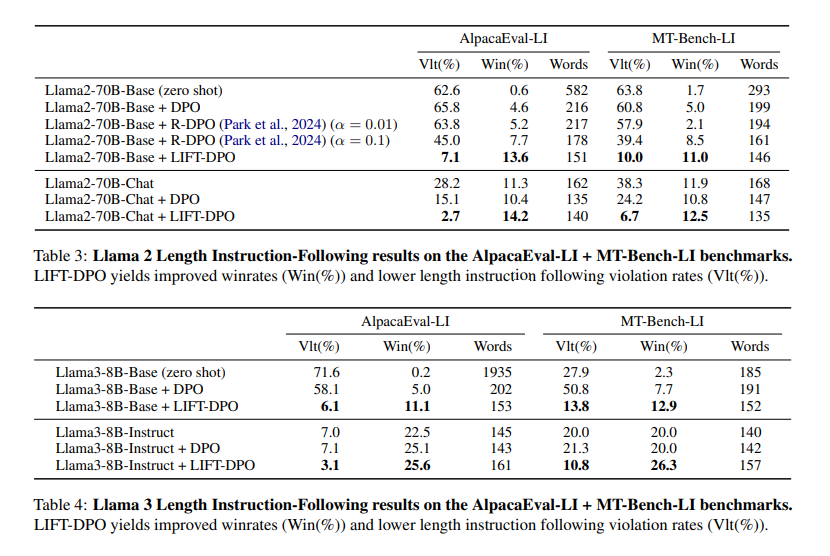
The proposed LIFT-DPO fashions demonstrated superior efficiency in adhering to size constraints in comparison with current state-of-the-art fashions like GPT-4 and Llama 3. For instance, the researchers discovered that the GPT-4 Turbo mannequin violated size constraints virtually 50% of the time, highlighting a major flaw in its design. In distinction, the LIFT-DPO fashions exhibited considerably decrease violation charges. Particularly, the Llama-2-70B-Base mannequin, when subjected to straightforward DPO coaching, confirmed a violation fee of 65.8% on AlpacaEval-LI, which dramatically decreased to 7.1% with LIFT-DPO coaching. Equally, the Llama-2-70B-Chat mannequin’s violation fee decreased from 15.1% with normal DPO to 2.7% with LIFT-DPO, demonstrating the tactic’s effectiveness in controlling response size.
Furthermore, the LIFT-DPO fashions maintained excessive response high quality whereas adhering to size constraints. The win charges improved considerably, indicating that the fashions might generate high-quality responses throughout the specified size limits. As an illustration, the win fee for the Llama-2-70B-Base mannequin elevated from 4.6% with normal DPO to 13.6% with LIFT-DPO. These outcomes underscore the tactic’s success in balancing size management and response high quality, offering a sturdy resolution for length-biased evaluations.
In conclusion, the analysis addresses the issue of size bias in instruction-following fashions by introducing the LIFT methodology. This method enhances the controllability and high quality of mannequin responses by integrating size constraints into the coaching course of. The outcomes point out that LIFT-DPO fashions outperform conventional strategies, offering a extra dependable and efficient resolution for length-constrained instruction following. The collaboration between Meta FAIR and New York College has considerably improved the event of AI fashions that may generate concise, high-quality responses, setting a brand new normal for instruction-following capabilities in AI analysis.
Try the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to comply with us on Twitter.
Be a part of our Telegram Channel and LinkedIn Group.
Should you like our work, you’ll love our e-newsletter..
Don’t Overlook to hitch our 46k+ ML SubReddit
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching functions in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


