
Tokenization is crucial in computational linguistics, significantly within the coaching and performance of huge language fashions (LLMs). This course of entails dissecting textual content into manageable items or tokens, which is foundational for mannequin coaching and operations. Whereas efficient tokenization can considerably improve a mannequin’s efficiency, points come up when tokens inside the mannequin’s vocabulary are underrepresented or absent within the coaching datasets, resulting in what researchers time period ‘glitch tokens.’ When encountered in new enter knowledge, these tokens can destabilize a mannequin and produce unpredictable outputs.
A prevalent concern in LLMs is the misalignment between tokenizer coaching and mannequin coaching. Typically, tokenizers are educated individually utilizing distinct datasets, which may differ considerably from the information used to coach the mannequin. This disjoint can result in a few of the vocabulary glitch tokens being under-trained. The notorious “_SolidGoldMagikarp” token is a infamous glitch token that may induce undesirable mannequin behaviors, reminiscent of hallucinations or producing nonsensical outputs.
Standard strategies for figuring out under-trained tokens sometimes contain handbook checks of the tokenizer’s habits, inspecting how tokens are encoded and decoded, or analyzing their frequency within the coaching knowledge. Nonetheless, these strategies usually are not scalable for the more and more giant and complicated LLMs being developed right this moment.
Researchers from Cohere introduce a novel strategy that makes use of the mannequin’s embedding weights to automate and scale the detection of under-trained tokens. The researchers developed a technique to research these weights to identify anomalies indicative of inadequate coaching. By assessing the embedding matrix of a mannequin, the analysis identifies tokens whose embedding weights deviate considerably from these of well-represented tokens. This technique offers a scientific solution to pinpoint glitch tokens by calculating the variance and distribution of embedding weights and evaluating them in opposition to a normative mannequin of adequately educated tokens.
The research demonstrated the effectiveness of this new technique by making use of it to a number of well-known fashions, together with variations of Google’s BERT and OpenAI’s GPT collection. The evaluation recognized a considerable proportion of the tokenizer’s vocabulary, as much as 10% in some instances, as under-trained. These tokens have been typically specialised or occasionally used phrases, which exhibited probably the most important discrepancies in embedding weight patterns.
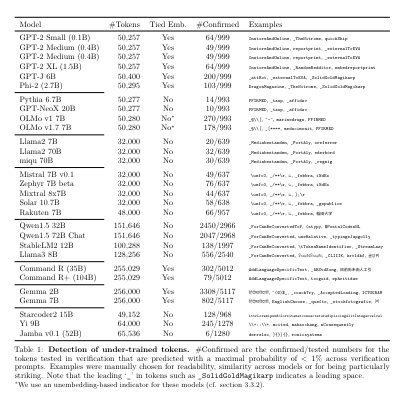
This analysis has important implications for the event and upkeep of LLMs. By using automated methods to detect and rectify under-trained tokens, builders can improve the accuracy and robustness of language fashions. This development is essential as LLMs are more and more utilized in varied purposes, from automated writing aids to classy conversational brokers.

In conclusion, this analysis highlights a important vulnerability in LLM coaching and presents a scalable resolution to mitigate this concern. Implementing automated strategies for detecting under-trained tokens permits for extra strong coaching processes, making certain that each one tokens in a mannequin’s vocabulary are adequately ready to deal with real-world purposes. This analysis improves the efficacy and reliability of language fashions, paving the way in which for extra dependable and efficient pure language processing instruments.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to observe us on Twitter. Be a part of our Telegram Channel, Discord Channel, and LinkedIn Group.
Should you like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our 42k+ ML SubReddit
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Expertise, Kharagpur. He’s obsessed with knowledge science and machine studying, bringing a robust educational background and hands-on expertise in fixing real-life cross-domain challenges.


