
As AI techniques turn into extra superior, guaranteeing their secure and moral deployment has turn into a vital concern for researchers and policymakers. One of many urgent points in AI governance is the administration of dangers related to more and more highly effective AI techniques. These dangers embody potential misuse, moral issues, and unintended penalties that might come up from AI’s rising capabilities. Policymakers are exploring numerous methods to mitigate these dangers, however the problem lies in precisely predicting and controlling the potential harms AI techniques would possibly trigger as they scale.
Present governance methods typically depend on defining thresholds for the computational energy (measured in FLOP – floating-point operations) used to coach AI fashions. These thresholds are meant to establish and regulate AI techniques that exceed sure ranges of computational depth underneath the belief that larger compute correlates with larger danger. Frameworks just like the White Home Government Orders on AI Security and the EU AI Act have integrated these thresholds into their insurance policies.
Cohere for AI researcher has launched a vital examination of those compute thresholds as a governance device. They argue that present implementations are shortsighted and fail to successfully mitigate dangers. They emphasize that the connection between compute and danger is extremely unsure and quickly evolving. As an alternative of relying solely on compute thresholds, they recommend a extra nuanced method to AI governance that considers a number of components influencing AI’s danger profile.
The proposed method advocates for a dynamic and complete analysis of AI techniques moderately than fastened compute thresholds. This contains higher specifying FLOP as a metric, contemplating extra dimensions of AI efficiency and danger, and implementing adaptive thresholds that regulate to the evolving panorama of AI capabilities. The researchers advocate enhancing transparency and standardization in reporting AI dangers and aligning governance practices with the precise efficiency and potential harms of AI techniques. This complete methodology includes inspecting components resembling the standard of coaching knowledge, optimization methods, and the precise purposes of AI fashions to make sure a extra correct evaluation of potential dangers.
The analysis highlights that fastened compute thresholds typically miss important dangers related to smaller, extremely optimized AI fashions. Empirical proof means that many present insurance policies have to account for the fast developments and optimization methods that may make smaller fashions as succesful and dangerous as bigger ones. As an example, fashions with lower than 13 billion parameters have been proven to outperform bigger fashions with over 176 billion parameters in sure duties. This oversight signifies that compute thresholds, as at the moment utilized, are unreliable predictors of AI dangers and want substantial revision to be efficient.
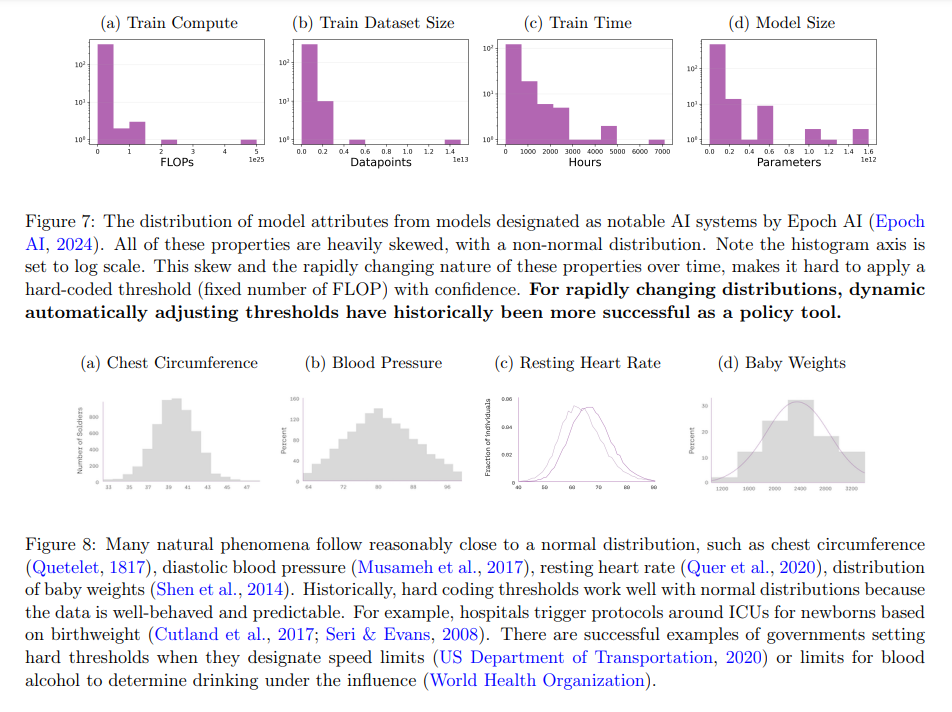
One noteworthy outcome from the analysis is that smaller fashions, when optimized, can obtain efficiency ranges corresponding to a lot bigger fashions. For instance, the research discovered that smaller fashions might attain as much as 77.15% efficiency scores on benchmark exams, a big enchancment from the 38.59% common simply two years prior. Moreover, the researchers identified that the present thresholds, resembling these set by the EU AI Act and the White Home Government Order, don’t seize the nuances of mannequin efficiency and danger, as they primarily concentrate on the sheer quantity of compute with out contemplating the precise capabilities and optimizations of the fashions.
In conclusion, the analysis underscores the inadequacy of compute thresholds as a standalone governance device for AI. The issue lies within the unpredictable relationship between compute and danger, necessitating a extra versatile and knowledgeable method to regulation. The proposed resolution includes shifting in direction of dynamic thresholds and multi-faceted danger assessments that may higher anticipate and mitigate the dangers posed by superior AI techniques. Researchers emphasize the necessity for insurance policies that evolve with the know-how and precisely replicate the complexities of contemporary AI growth.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. In case you like our work, you’ll love our publication..
Don’t Overlook to affix our 47k+ ML SubReddit
Discover Upcoming AI Webinars right here
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching purposes in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.



