
Giant language fashions (LLMs) face a crucial problem of their coaching course of: the approaching shortage of high-quality web knowledge. Predictions recommend that by 2026, the out there pool of such knowledge will likely be exhausted, forcing researchers to show to model-generated or artificial knowledge for coaching. This shift presents each alternatives and dangers. Whereas some research have proven that scaling up artificial knowledge can enhance efficiency on complicated reasoning duties, others have revealed a regarding development. Coaching on artificial knowledge can probably result in a downward spiral in mannequin efficiency, amplifying biases, propagating misinformation, and reinforcing undesired stylistic properties. The core problem lies in designing artificial knowledge that successfully addresses knowledge shortage with out compromising the standard and integrity of the ensuing fashions. This job is especially daunting because of the present lack of expertise relating to how artificial knowledge influences LLM habits.
Researchers have explored numerous approaches to sort out LLM coaching challenges utilizing artificial knowledge. Customary strategies like teacher-forcing on knowledgeable knowledge have proven limitations, notably in math reasoning. Efforts to generate optimistic artificial knowledge intention to imitate high-quality coaching knowledge, utilizing sources like stronger instructor fashions and self-generated content material. Whereas this method has proven promise, challenges persist in verifying the standard of artificial math knowledge. Issues about bias amplification, mannequin collapse, and overfitting on spurious steps stay. To mitigate these points, researchers are investigating the usage of detrimental model-generated responses to determine and unlearn problematic patterns in coaching knowledge.
Researchers from Carnegie Mellon College, Google DeepMind, and MultiOn current the examine to analyze the affect of artificial knowledge on LLM math reasoning capabilities. It examines each optimistic and detrimental artificial knowledge, discovering that optimistic knowledge improves efficiency however with slower scaling charges than pretraining. Notably, self-generated optimistic responses typically match the effectiveness of twice the quantity of information from bigger fashions. They introduce a sturdy method utilizing detrimental artificial knowledge, contrasting it with optimistic knowledge at crucial steps. This system, equal to per-step advantage-weighted reinforcement studying, demonstrates the potential to scale effectivity as much as eight occasions in comparison with utilizing solely optimistic knowledge. The examine develops scaling legal guidelines for each knowledge sorts on widespread reasoning benchmarks, providing worthwhile insights into optimizing artificial knowledge use for enhancing LLM efficiency in math reasoning duties.
The detailed structure of the proposed technique entails a number of key parts:
- Artificial Knowledge Pipeline:
- Prompts succesful fashions like GPT-4 and Gemini 1.5 Professional to generate new issues just like actual ones.
- Obtains resolution traces with step-by-step reasoning for these issues.
- Implements a binary reward operate to confirm the correctness of resolution traces.
- Dataset Building:
- Creates optimistic artificial dataset from appropriate problem-solution pairs.
- Generates optimistic and detrimental datasets utilizing model-generated options.
- Studying Algorithms:
- Supervised Finetuning (SFT):
- Trains on 𝒟syn utilizing next-token prediction.
- Supervised Finetuning (SFT):
- Rejection Finetuning (RFT):
- Makes use of SFT coverage to generate optimistic responses for 𝒟syn issues.
- Applies next-token prediction loss on these self-generated optimistic responses.
- Choice Optimization:
- Makes use of Direct Choice Optimization (DPO) to study from each optimistic and detrimental knowledge.
- Implements two variants: commonplace DPO and per-step DPO.
- Per-step DPO identifies the “first pit” in resolution traces to give attention to crucial steps.
This structure permits for complete evaluation of various artificial knowledge sorts and studying approaches, enabling the examine of their affect on LLM math reasoning capabilities.
The examine reveals vital insights into artificial knowledge scaling for LLM math reasoning. Constructive knowledge scaling exhibits enchancment however with slower charges than pre-training. Surprisingly, self-generated optimistic knowledge (RFT) outperforms knowledge from extra succesful fashions, doubling effectivity. Probably the most hanging outcome comes from strategically utilizing detrimental knowledge with per-step Direct Choice Optimization, which will increase knowledge effectivity by 8x in comparison with optimistic knowledge alone. This method persistently outperforms different strategies, highlighting the crucial significance of fastidiously setting up and using each optimistic and detrimental artificial knowledge in LLM coaching for mathematical reasoning duties.
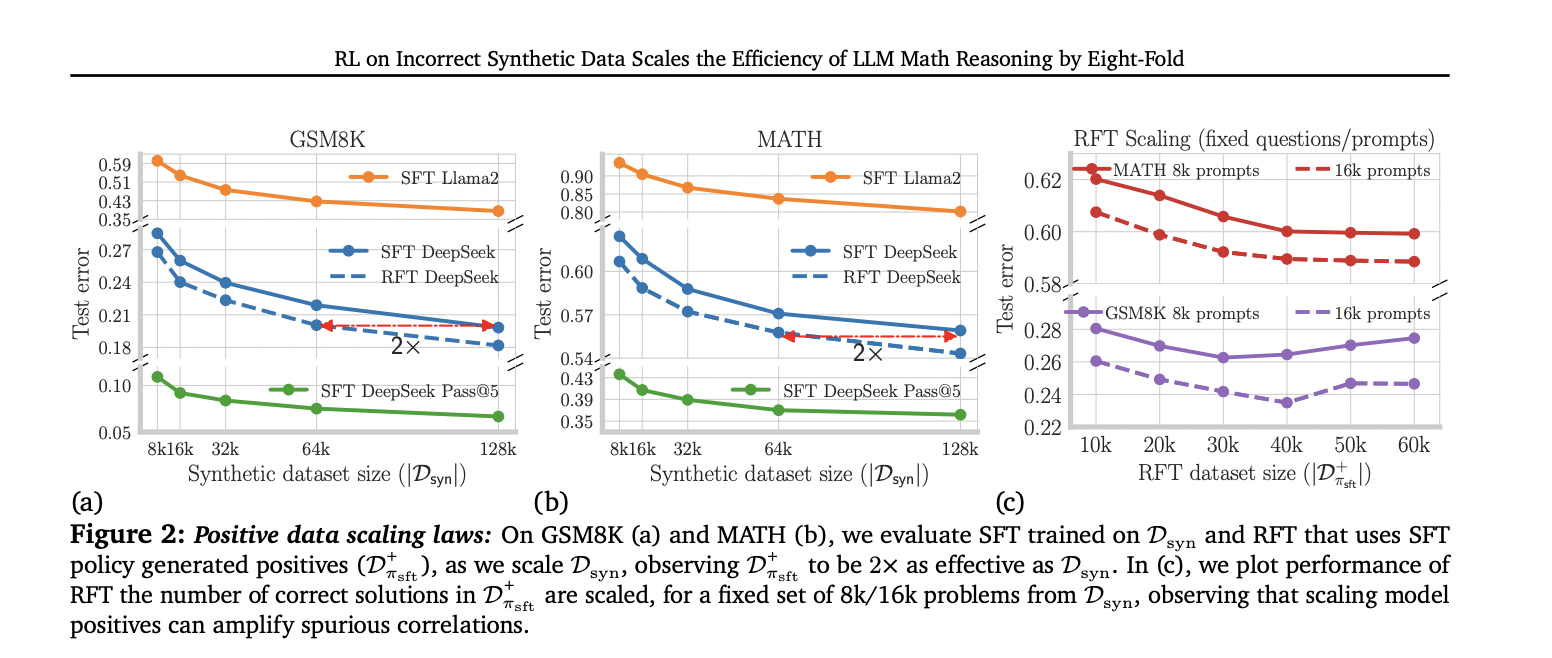
This examine explores the affect of artificial knowledge on enhancing LLMs’ math reasoning capabilities. It reveals that conventional strategies utilizing optimistic options from superior fashions present restricted effectivity. Self-generated optimistic knowledge from fine-tuned 7B fashions improves effectivity by 2x however can amplify reliance on spurious steps. Surprisingly, incorporating detrimental (incorrect) traces addresses these limitations. By utilizing detrimental knowledge to estimate step-wise benefits and making use of reinforcement studying strategies, the analysis demonstrates an 8x enchancment in artificial knowledge effectivity. This method, using choice optimization aims, considerably enhances LLMs’ mathematical reasoning skills by successfully balancing optimistic and detrimental artificial knowledge.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to observe us on Twitter.
Be a part of our Telegram Channel and LinkedIn Group.
When you like our work, you’ll love our publication..
Don’t Neglect to hitch our 45k+ ML SubReddit
Asjad is an intern guide at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the functions of machine studying in healthcare.


