
Massive Language Fashions (LLMs) are a subset of synthetic intelligence specializing in understanding and producing human language. These fashions leverage advanced architectures to grasp and produce human-like textual content, facilitating purposes in customer support, content material creation, and past.
A serious problem with LLMs is their effectivity when processing lengthy texts. The Transformer structure they use has a quadratic time complexity, which will increase computational load considerably, particularly when coping with prolonged sequences. This complexity poses a considerable barrier to attaining environment friendly efficiency, significantly because the size of textual content inputs grows. Addressing this problem is essential for the continued development and utility of LLMs in real-world eventualities.
Researchers have launched the KV-Cache mechanism to handle this problem, which shops keys and values generated by previous tokens. This reduces the time complexity from quadratic to linear. Nevertheless, KV-Cache will increase GPU reminiscence utilization, which scales with the dialog size, creating a brand new bottleneck. Present strategies goal to steadiness this trade-off between computational effectivity and reminiscence overhead, making it important to optimize KV-Cache utilization successfully.
The analysis crew from Wuhan College and Shanghai Jiao Tong College launched a number of KV-Cache compression strategies. These strategies optimize KV-Cache area utilization throughout LLMs’ pre-training, deployment, and inference phases, aiming to boost effectivity with out compromising efficiency. Their method contains modifying the mannequin structure throughout pre-training to scale back the scale of the Keys and Values vectors by as much as 75%. This adjustment maintains the benefits of the eye mechanism whereas considerably decreasing reminiscence necessities.
The proposed strategies embody architectural changes throughout pre-training, which cut back the scale of generated Keys and Worth vectors. Throughout deployment, frameworks like Paged Consideration and DistKV-LLM distribute KV-Cache throughout a number of servers to enhance reminiscence administration. Put up-training strategies embody dynamic eviction methods and quantization methods that compress KV-Cache with out considerably shedding mannequin capabilities. Particularly, Paged Consideration makes use of a mapping desk to retailer KV-Cache discontinuously in GPU reminiscence, minimizing fragmentation and enhancing inference pace. DistKV-LLM extends this by enabling distributed deployment throughout servers and enhancing large-scale cloud service effectivity.
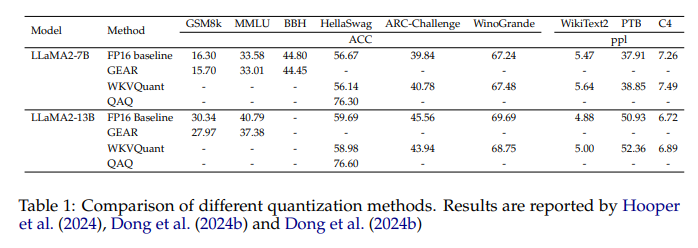
The strategies launched have proven vital enhancements in reminiscence effectivity and inference pace. For example, the GQA methodology utilized in common fashions like LLaMA2-70B achieves higher reminiscence utilization by lowering the KV-Cache measurement whereas sustaining efficiency ranges. These optimizations exhibit the potential to deal with longer contexts extra successfully. Particularly, GQA reduces reminiscence utilization to a fraction of that required by conventional strategies, attaining a 75% discount in KV-Cache measurement. Moreover, fashions utilizing Multi-Question Consideration (MQA) and GQA exhibit improved throughput and decreased latency, essential metrics for real-time purposes. The analysis signifies that the LLaMA2-70B mannequin’s per-token reminiscence utilization drops from 0.5MB to 0.125MB, showcasing a major enhancement in effectivity.
The analysis supplies complete methods for optimizing KV-Cache in LLMs, addressing the reminiscence overhead problem. By implementing these strategies, LLMs can obtain increased effectivity and higher efficiency, paving the way in which for extra sustainable and scalable AI options. The findings from Wuhan College and Shanghai Jiao Tong College provide a roadmap for future developments, emphasizing the significance of environment friendly reminiscence administration within the evolution of LLM know-how. These methods not solely mitigate present limitations but in addition open avenues for exploring extra refined purposes of LLMs in varied industries.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. In case you like our work, you’ll love our publication..
Don’t Neglect to affix our 47k+ ML SubReddit
Discover Upcoming AI Webinars right here
Nikhil is an intern marketing consultant at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching purposes in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


