
Pure language processing (NLP) has superior considerably due to neural networks, with transformer fashions setting the usual. These fashions have carried out remarkably properly throughout a variety of standards. Nevertheless, they pose severe issues due to their excessive reminiscence necessities and excessive computational expense, significantly for functions that demand long-context work. This persistent downside motivates the pursuit of simpler substitutes that maintain efficiency requirements whereas requiring fewer assets.
The principle challenge with transformer fashions is their excessive reminiscence and processing necessities. Though these fashions carry out properly on NLP duties, they could possibly be extra sensible in contexts with restricted assets. This problem highlights the necessity for fashions with decrease computational overhead that may present comparable or higher efficiency than present ones. Resolving this challenge is crucial to growing the usability and accessibility of contemporary NLP expertise in varied functions.
Current analysis consists of Linear Transformers, which purpose to enhance effectivity over softmax transformers. The RWKV mannequin and RetNet supply aggressive efficiency with linear consideration mechanisms. State-space fashions like H3 and Hyena combine recurrent and convolutional networks for long-sequence duties. Strategies equivalent to Performers, Cosformer, and LUNA concentrate on enhancing transformer effectivity. The Griffin mannequin combines sliding window and linear consideration methods.
Researchers from the Toyota Analysis Institute have launched Scalable UPtraining for Recurrent Consideration (SUPRA), a way to transform pre-trained transformers into recurrent neural networks (RNNs). This method leverages high-quality pre-training information from transformers whereas using a linearization method that replaces softmax normalization with GroupNorm. SUPRA is exclusive because it combines the strengths of transformers and RNNs, attaining aggressive efficiency with decreased computational price.
The SUPRA methodology includes uptraining transformers equivalent to Llama2 and Mistral-7B. The method replaces softmax normalization with GroupNorm, together with a small multi-layer perceptron (MLP) for projecting queries and keys. The fashions had been educated utilizing the RefinedWeb dataset with 1.2 trillion tokens. Coaching and fine-tuning had been carried out utilizing a modified model of OpenLM, and evaluations had been performed with the Eleuther analysis harness on normal NLU benchmarks. This method permits transformers to function recurrently and effectively, dealing with quick and long-context duties.
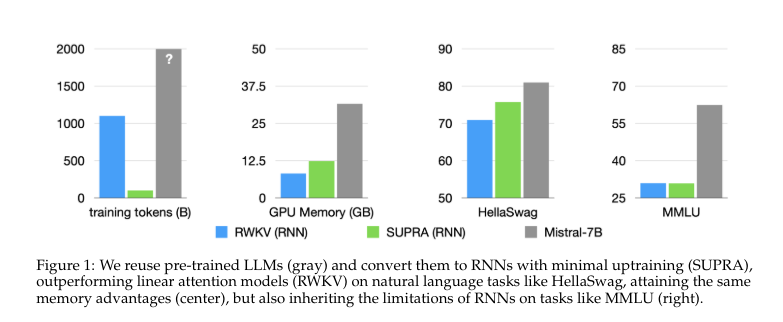
The SUPRA technique confirmed aggressive efficiency on varied benchmarks. It outperformed RWKV and RetNet on the HellaSwag benchmark, attaining a rating of 77.9 in comparison with 70.9 and 73.0, respectively. The mannequin additionally demonstrated sturdy outcomes on different duties, with scores of 76.3 on ARC-E, 79.1 on ARC-C, and 46.3 on MMLU. Coaching required solely 20 billion tokens, considerably lower than different fashions. Regardless of some efficiency drops in long-context duties, SUPRA maintained sturdy outcomes inside its coaching context size.
In conclusion, the SUPRA technique efficiently converts pre-trained transformers into environment friendly RNNs, addressing the excessive computational prices of conventional transformers. By changing softmax normalization with GroupNorm and utilizing a small MLP, SUPRA fashions obtain aggressive efficiency on benchmarks like HellaSwag and ARC-C with considerably decreased coaching information. This analysis highlights the potential for scalable, cost-effective NLP fashions, sustaining sturdy efficiency throughout varied duties and paving the best way for extra accessible superior language processing applied sciences.
Try the Paper and GitHub. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to observe us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
Should you like our work, you’ll love our publication..
Don’t Neglect to hitch our 42k+ ML SubReddit
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching functions in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


