
Researchers in laptop imaginative and prescient and robotics constantly attempt to enhance autonomous methods’ notion capabilities. These methods are anticipated to understand their surroundings precisely in real-time. Creating new strategies and algorithms permits for improvements that profit varied industries, together with transportation, manufacturing, and healthcare.
A major problem on this area is enhancing the precision and effectivity of object detection and segmentation in photos and video streams. These duties require fashions that may course of visible data shortly and appropriately to acknowledge, classify, and description totally different objects. This want for velocity and accuracy pushes researchers to discover new strategies that may present dependable leads to dynamic environments.
Present analysis consists of convolutional neural networks (CNNs) and transformer-based object detection and segmentation architectures. CNNs are identified for his or her capability to successfully determine visible patterns, making them well-suited for detailed function extraction. However, transformers excel in dealing with advanced duties as a consequence of their versatility and effectivity in processing international contexts. These strategies have superior the sphere, but there may be room for enchancment in balancing accuracy, velocity, and computational effectivity.
Researchers from the College of Wisconsin-Madison have launched a brand new method specializing in retrieval-augmented activity adaptation for vision-language fashions. Their methodology emphasizes utilizing image-to-image (I2I) retrieval because it constantly outperforms text-to-image (T2I) retrieval in downstream duties. The strategy leverages a function cache constructed from retrieved samples, considerably impacting the difference course of and optimizing the efficiency of vision-language fashions by incorporating one of the best practices of retrieval-augmented adaptation.
The analysis employed retrieval-augmented adaptation for vision-language fashions, using Caltech101, Birds200, Food101, OxfordPets, and Flowers102 datasets. The method used a pre-trained CLIP mannequin and exterior image-caption datasets like LAION to construct a function cache by means of I2I and T2I retrieval strategies. This function cache was then leveraged to adapt the mannequin for downstream duties with restricted knowledge. The retrieval methodology gave the mannequin invaluable context, enabling it to deal with the distinctive challenges of fine-grained visible classes in these datasets.
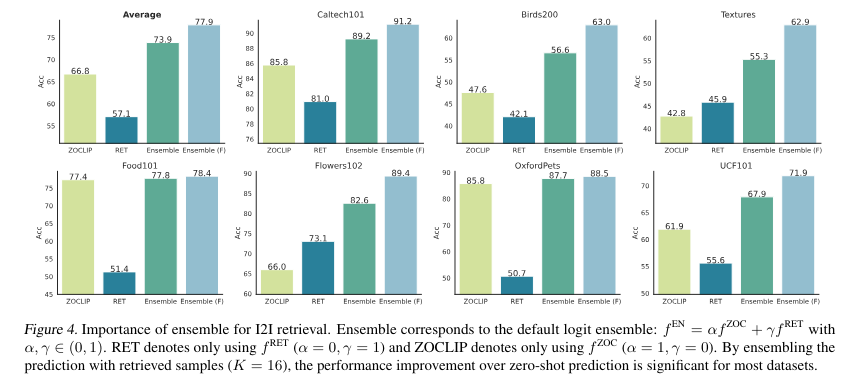
The analysis demonstrated vital efficiency enhancements in retrieval-augmented adaptation for vision-language fashions. Utilizing I2I retrieval, the strategy achieved a excessive accuracy of as much as 93.5% on Caltech101, outperforming T2I retrieval by over 10% throughout varied datasets. On datasets like Birds200 and Food101, the proposed mannequin improved classification accuracy by round 15% in comparison with earlier strategies. The usage of function cache retrieval led to a 25% discount in error charges for difficult fine-grained visible classes.
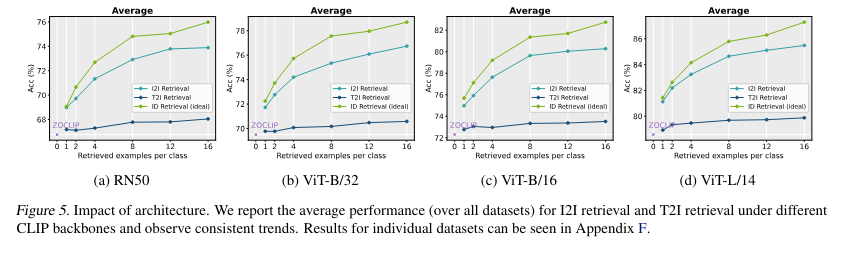
To conclude, the analysis targeted on retrieval-augmented activity adaptation, combining I2I and T2I retrieval strategies for vision-language fashions. By using pre-trained fashions and have cache retrieval, the research improved mannequin adaptation on a number of datasets. The method confirmed vital developments in accuracy and error discount, highlighting the potential of retrieval-augmented adaptation in dealing with fine-grained visible classes. This analysis offers invaluable insights into enhancing vision-language fashions, emphasizing the significance of retrieval strategies in low-data regimes.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to observe us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
If you happen to like our work, you’ll love our publication..
Don’t Overlook to affix our 41k+ ML SubReddit
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching purposes in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


