
Language modeling, a core part of machine studying, entails predicting the probability of a sequence of phrases. This subject primarily enhances machine understanding and era of human language, serving as a spine for numerous purposes reminiscent of textual content summarization, translation, and auto-completion techniques. Environment friendly language modeling faces vital hurdles, significantly with giant fashions. The primary problem is the computational and reminiscence overhead related to processing and storing intensive information sequences, which hampers scalability and real-time processing capabilities.
Present analysis in language modeling prominently options the Transformer structure, recognized for its self-attention mechanism that successfully processes phrase sequences no matter distance. Distinguished variations embrace the decoder-only Transformer, optimizing textual content era processes in fashions like OpenAI’s GPT collection. Improvements like Sparse Transformers have additionally emerged, decreasing computational calls for by limiting interactions between distant sequence components. Furthermore, hybrid fashions reminiscent of BERT and T5 mix numerous architectural strengths, enhancing language fashions’ effectivity and functionality in understanding and producing nuanced textual content.
Microsoft Analysis and Tsinghua College researchers have launched a novel structure, You Solely Cache As soon as (YOCO), for big language fashions. The YOCO structure presents a novel decoder-decoder framework that diverges from conventional approaches by caching key-value pairs solely as soon as. This technique considerably reduces the computational overhead and reminiscence utilization sometimes related to repetitive caching in giant language fashions. YOCO effectively processes lengthy sequences by leveraging precomputed world KV caches all through the mannequin’s operation, streamlining the eye mechanism and enhancing general efficiency by using a self-decoder and a cross-decoder.
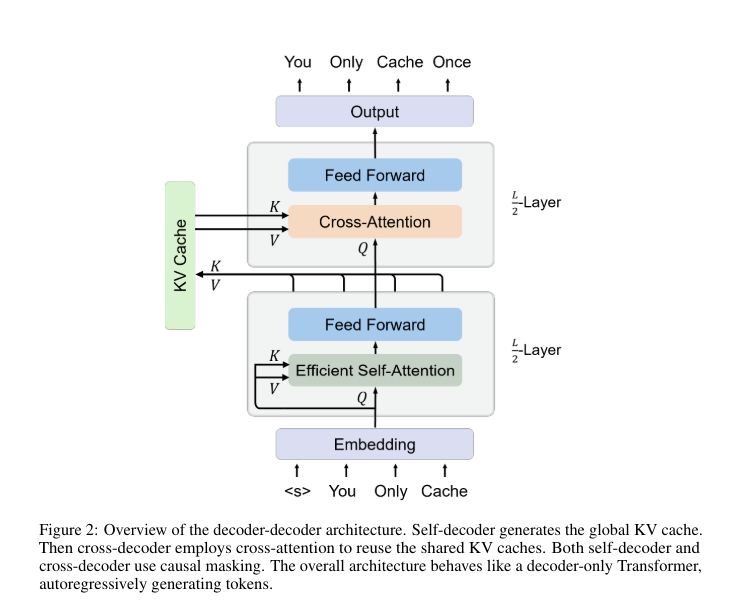
The YOCO methodology combines the usage of self-decoder and cross-decoder mechanisms with superior consideration strategies to optimize language processing. Particularly, the self-decoder makes use of a sliding window and gated retention consideration to generate a compact set of KV pairs. The cross-decoder reuses these pairs by way of cross-attention, eliminating the necessity for re-encoding and thus conserving computational assets. The mannequin was evaluated on numerous datasets to evaluate its efficiency in real-world eventualities, demonstrating substantial enhancements in processing speeds and reminiscence effectivity in comparison with standard Transformer-based fashions.
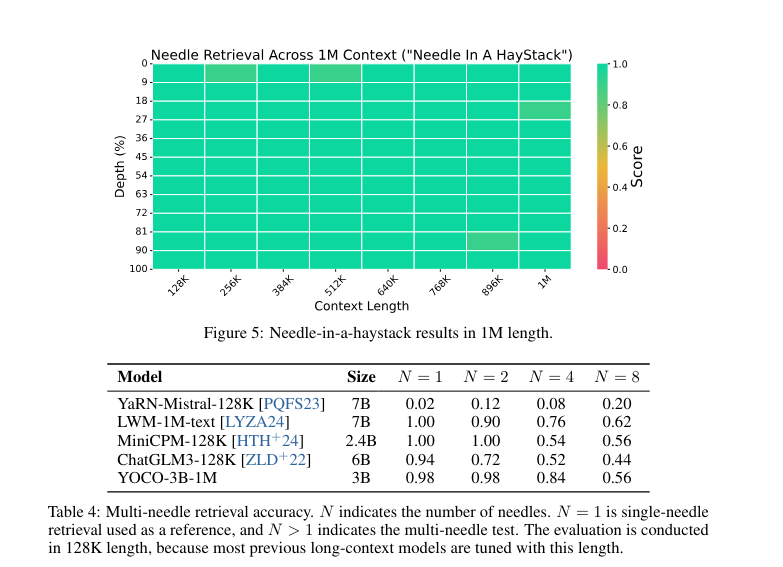
Experimental outcomes spotlight YOCO’s effectiveness, with the mannequin attaining near-perfect needle retrieval accuracy for sequences as much as 1 million tokens. YOCO reduces GPU reminiscence calls for by roughly 80 instances for 65-billion-parameter fashions. Moreover, it cuts down prefilling latency from 180 seconds to lower than 6 seconds for contexts as giant as 512,000 tokens whereas enhancing throughput to 43.1 tokens per second in comparison with 4.5 for the standard Transformer, marking a 9.6 instances improve. These metrics set up YOCO as a extremely environment friendly structure for processing intensive information sequences.
To summarize, the YOCO structure introduces an modern method to language modeling by caching key-value pairs solely as soon as, considerably decreasing computational overhead and reminiscence utilization. By using a novel decoder-decoder framework that leverages environment friendly consideration mechanisms, YOCO demonstrates substantial enhancements in dealing with lengthy sequences—attaining near-perfect retrieval accuracy and drastically reducing latency and reminiscence calls for. This analysis offers a scalable, environment friendly answer for deploying giant language fashions, providing substantial sensible advantages for real-world purposes that require processing intensive information sequences.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to comply with us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
For those who like our work, you’ll love our publication..
Don’t Overlook to hitch our 42k+ ML SubReddit
Nikhil is an intern marketing consultant at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching purposes in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


