
Massive language fashions (LLMs), as computational giants able to understanding and producing textual content with astonishing accuracy, maintain the important thing to numerous functions, from automated content material creation to stylish conversational brokers. Nonetheless, their deployment is marred by a major hurdle: computational and reminiscence necessities. As fashions turn out to be advanced, deploying them outdoors high-powered servers turns into a formidable problem, limiting their accessibility and real-world utility.
Approaches to mannequin optimization have ventured into varied territories, from pruning to data distillation. But, an answer that marries a minimal reminiscence footprint with minimal loss in efficiency needs to be found. Inside this context, a pioneering method, dubbed OneBit, emerges from the collaborative efforts of researchers at Tsinghua College and Harbin Institute of Expertise. OneBit represents a paradigm shift, addressing the effectivity problem head-on by introducing a framework for quantization-aware coaching (QAT) of LLMs to an unprecedented 1-bit illustration.
Whereas profitable to a level, conventional quantization strategies falter when pushed to the extremes of low-bit representations, usually leading to a drastic degradation of mannequin efficiency. OneBit, nonetheless, circumvents this problem via a novel parameter illustration methodology that considerably reduces the bit-width of weight matrices with out severely impacting the mannequin’s effectiveness. That is achieved by decomposing weight matrices that retain important info with minimal spatial necessities, coupled with an astute parameter initialization methodology that enhances the convergence velocity of the coaching course of.
OneBit’s methodology leverages a novel linear layer and Signal-Worth-Impartial Decomposition (SVID) for weight matrices, enabling the illustration of LLMs utilizing roughly 1-bit values. This decomposition separates every authentic weight matrix into an indication matrix and two worth vectors, with the previous sustaining the excessive rank of the unique matrix at a fraction of the area value and the latter offering the required floating-point precision in linear projections. This strategic decomposition and the utilization of quantization-aware data distillation facilitate the switch of capabilities from the unique mannequin to its 1-bit counterpart, making certain that the essence of the mannequin’s predictive energy is preserved.
OneBit has demonstrated its capability to retain not less than 83% of a mannequin’s non-quantized efficiency throughout varied duties, showcasing its viability for environment friendly LLM deployment. This achievement paves the best way for making use of LLMs in environments with restricted assets and establishes a brand new customary for analysis in mannequin quantization.
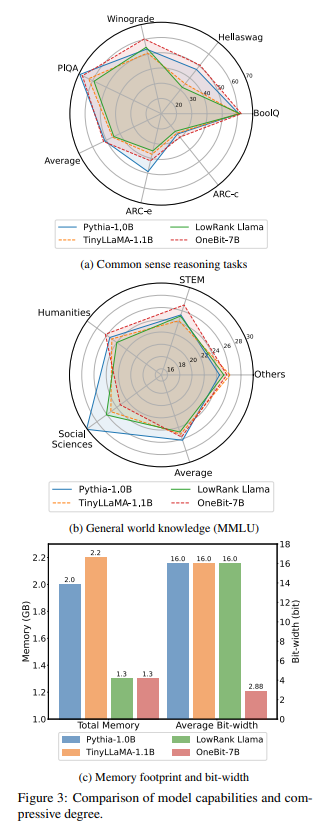
OneBit’s implications are profound. By considerably lowering the reminiscence footprint required to deploy LLMs, it democratizes entry to cutting-edge pure language processing capabilities, enabling their integration into on a regular basis gadgets and functions. This breakthrough has the potential to speed up the adoption of LLMs throughout a variety of sectors, from training and healthcare to leisure and customer support, making the advantages of AI extra accessible to individuals world wide.
In conclusion, OneBit represents a major leap ahead within the quest for environment friendly and accessible massive language fashions. By marrying the seemingly conflicting targets of minimal reminiscence utilization and minimal efficiency loss, it addresses a essential problem within the deployment of LLMs and opens new avenues for his or her software. The contributions of the OneBit analysis group remind us of the transformative energy of innovation, charting a course towards a future the place the potential of enormous language fashions might be totally realized, unfettered by the constraints of computational and reminiscence assets.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to comply with us on Twitter and Google Information. Be a part of our 38k+ ML SubReddit, 41k+ Fb Group, Discord Channel, and LinkedIn Group.
In the event you like our work, you’ll love our publication..
Don’t Overlook to affix our Telegram Channel
You might also like our FREE AI Programs….
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Environment friendly Deep Studying, with a give attention to Sparse Coaching. Pursuing an M.Sc. in Electrical Engineering, specializing in Software program Engineering, he blends superior technical data with sensible functions. His present endeavor is his thesis on “Enhancing Effectivity in Deep Reinforcement Studying,” showcasing his dedication to enhancing AI’s capabilities. Athar’s work stands on the intersection “Sparse Coaching in DNN’s” and “Deep Reinforcemnt Studying”.


