
At this time’s language fashions are mind-blowingly good…for generalists. Ask them about historical past, science, or present occasions; they’ll dazzle you with many info and insights. However with regards to specialised, area of interest matters. That’s the place even the mightiest AI mind can get slightly fuzzy.
Think about you’re a physician making an attempt to get assist researching a uncommon medical situation. Or a lawyer on the lookout for judgments on an obscure authorized difficulty. Typical language fashions want extra deep area data. It’s like asking a straight-A pupil to weigh in on quantum physics – they’re good, simply not that good.
A group of researchers at UC Berkeley Suggest Enter RAFT (Retrieval Augmented High-quality Tuning), an ingenious new strategy that could possibly be the Rosetta Stone for translating between generalized AI and hyper-specific experience. It’s a option to stuff these extremely succesful however generalist language fashions full of specialised data and documentation. Whereas instruments like GPT-3 dazzle with broad capabilities, their efficiency will get shaky when domain-specific data is required. Conventional strategies like retrieval augmentation let fashions reference docs however don’t optimize for the goal area. Supervised fine-tuning exposes them to area information however lacks connection to retrievable proof.
RAFT combines one of the best of each worlds by a novel coaching course of mimicking an “open-book examination” setting:
1) It trains on question-answer pairs from the specialised area.
2) However it additionally will get test-like prompts with a mixture of related “oracle” docs and irrelevant “distractor” docs.
3) Studying to sift by all that, cite pertinent quotes, and construct multi-step “chain-of-thought” reasoning.
Utilizing distractors and sourced proof, RAFT successfully cross-trains language fashions in area comprehension and focusing expertise.When evaluated on coding, biomedicine, and common question-answering benchmarks, RAFT demonstrated dramatic enhancements over conventional fine-tuning approaches.
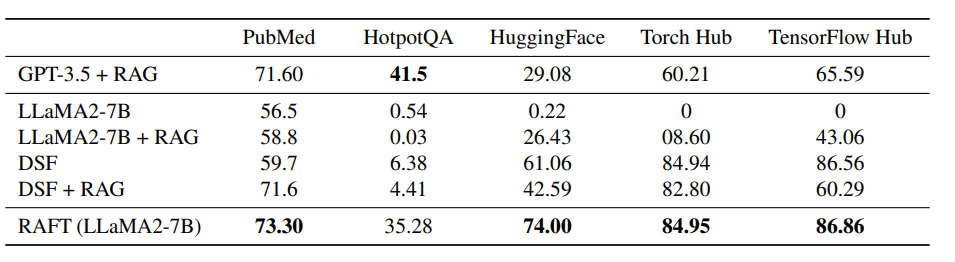
The analysis outcomes exhibit RAFT’s clear superiority over present baselines throughout a spread of specialised domains. When examined on datasets like PubMed biomedical literature, HotpotQA common questions, and coding benchmarks like HuggingFace and TorchHub, RAFT persistently outperformed commonplace language fashions and domain-specific fine-tuning strategies. In comparison with the bottom LLaMA2 mannequin, RAFT exhibited dramatic good points, enhancing by a staggering 35.25% on HotpotQA and 76.35% on the TorchHub coding analysis. It considerably outperformed domain-specific fine-tuning approaches as nicely, boosting efficiency by 30.87% on HotpotQA and 31.41% on the HuggingFace datasets over these strategies. Even in opposition to the highly effective GPT-3.5, RAFT demonstrated a transparent benefit when it got here to leveraging offered context and area data to unravel specialised questions precisely. The outcomes spotlight RAFT’s effectiveness in imbuing language fashions with correct material comprehension throughout technical domains.
Extra than simply incremental progress, RAFT represents a paradigm shift in unlocking area mastery for language AI. We’re speaking digital assistants and chatbots that may expertly information you thru every little thing from genetics to connoisseur cooking.
Whereas at present’s language fashions are highly effective generalists, RAFT presents a path towards true AI specialization and material experience. Mixed with their present common reasoning, this might open up unprecedented new frontiers throughout industries like healthcare, regulation, science, and software program improvement.
By bridging the strengths of common reasoning and focused experience, RAFT clears a path towards a future the place language AI transcends being “jacks of all trades” to turn into true material authorities. It’s a pivotal step in creating synthetic intelligence that matches or surpasses human mastery throughout each conceivable data area.
Take a look at the Paper and Github. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to comply with us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
If you happen to like our work, you’ll love our e-newsletter..
Don’t Neglect to affix our 38k+ ML SubReddit
Vibhanshu Patidar is a consulting intern at MarktechPost. At the moment pursuing B.S. at Indian Institute of Know-how (IIT) Kanpur. He’s a Robotics and Machine Studying fanatic with a knack for unraveling the complexities of algorithms that bridge idea and sensible purposes.


