Amazon’s newest breakthrough in synthetic intelligence (AI) has shaken up the tech world with the revealing of the biggest text-to-speech mannequin. Developed by a workforce of AI researchers at Amazon AGI, this colossal mannequin boasts a formidable 980 million parameters and was skilled utilizing an enormous 100,000 hours of recorded speech, predominantly in English. Named the Large Adaptive Streamable TTS with Emergent skills (BASE TTS), this modern mannequin represents a major leap ahead within the realm of speech synthesis expertise.
Let’s break down its most charming options:
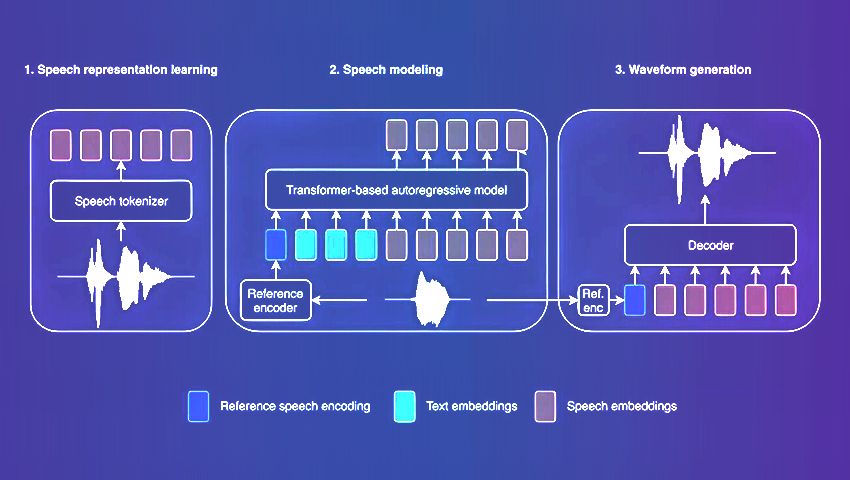
The Structure
- 1-billion-parameter autoregressive transformer: At its core, BASE TTS wields an enormous autoregressive transformer. This neural community converts uncooked textual content into discrete codes often known as “speechcodes.”
- Convolution-based decoder: Following the speechcodes, a convolution-based decoder transforms them into precise waveforms. The wonder lies in its incremental, streamable method, permitting real-time synthesis.
A novel method to speech codes
- Autoencoder-based speech tokens: BASE TTS introduces a novel speech tokenization method. These speech tokens disentangle speaker identification and compress data utilizing byte-pair encoding.
- Speaker ID disentanglement: Think about a TTS system that may mimic completely different audio system seamlessly. BASE TTS achieves this by disentangling speaker traits from the uncooked audio.
- Pure prosody emergence: Echoing the phenomenon seen in giant language fashions, BASE TTS variants with 10K+ hours and 500M+ parameters start to exhibit pure prosody even on advanced sentences.
State-of-the-art naturalness
- Speech naturalness: BASE TTS units a brand new benchmark for naturalness. Its output rivals publicly obtainable large-scale TTS techniques like YourTTS, Bark, and Tortoise TTS.
- Complicated phrases, feelings, and punctuation: BASE TTS handles advanced vocabulary, infuses feelings, and nails punctuation. It’s not simply robotic; it’s expressive.
State-of-the-art naturalness
- Information effectivity: BASE TTS demonstrates that information effectivity may be constructed into large-scale fashions. It achieves outstanding outcomes with fewer coaching hours.
- Streamability: The incremental, streamable method opens doorways for real-time functions in voice assistants, audiobooks, and extra.
The importance of the BASE TTS lies not solely within the sheer scale of the mannequin but additionally in its emergent skills – a phenomenon the place the AI utility displays a sudden breakthrough in intelligence. By means of rigorous testing, the researchers found that this leap occurred on the 150 million parameter mark, highlighting the crucial function of dataset dimension in driving developments in AI capabilities.
One of the crucial outstanding options of the BASE TTS mannequin is its versatility in dealing with numerous language attributes. From advanced compound nouns to emotive expressions, overseas language pronunciations, and even nuances in intonation and punctuation, the mannequin demonstrates a formidable command over linguistic intricacies. Furthermore, its capacity to appropriately emphasize key phrases in a sentence and pose questions with precision provides one other layer of sophistication to its performance.
Whereas the BASE TTS mannequin will not be made publicly obtainable as a result of moral issues surrounding its potential misuse, Amazon’s analysis workforce plans to leverage its learnings to reinforce the general high quality of text-to-speech functions.
Nonetheless, you’ll be able to expertise the comfort of QuData’s on-line text-to-speech service proper now! Get pleasure from our free speech synthesis expertise and convert written textual content into voice with out effort.


