
Desk understanding has gained consideration on account of its important position in enabling language fashions (LMs) to successfully course of and interpret structured knowledge. Leveraging LMs to research tabular knowledge helps carry out advanced operations like query answering, semantic reasoning, and knowledge extraction. Regardless of these advances, dealing with large-scale tables stays a major problem because of the inherent context size constraints of LMs, which restrict their capability to course of quite a few rows and columns concurrently. This creates a bottleneck for duties requiring the entire understanding of expansive tabular datasets, prompting the necessity for environment friendly options to assist large-scale desk understanding.
One main problem in desk understanding is the scalability of language fashions when coping with tables that comprise tens of millions of tokens. Conventional strategies tackle this subject by feeding the whole desk into the mannequin or focusing solely on the schema construction, resembling column names and knowledge varieties. Whereas these approaches present partial options, they usually outcome within the lack of essential context and might overwhelm LMs, resulting in efficiency degradation. Additional, as desk dimension will increase, so does the computational price, making it infeasible to course of the whole knowledge in a single move. Due to this fact, it’s important to develop frameworks that selectively retrieve and current related desk parts to LMs, sustaining excessive accuracy and effectivity.
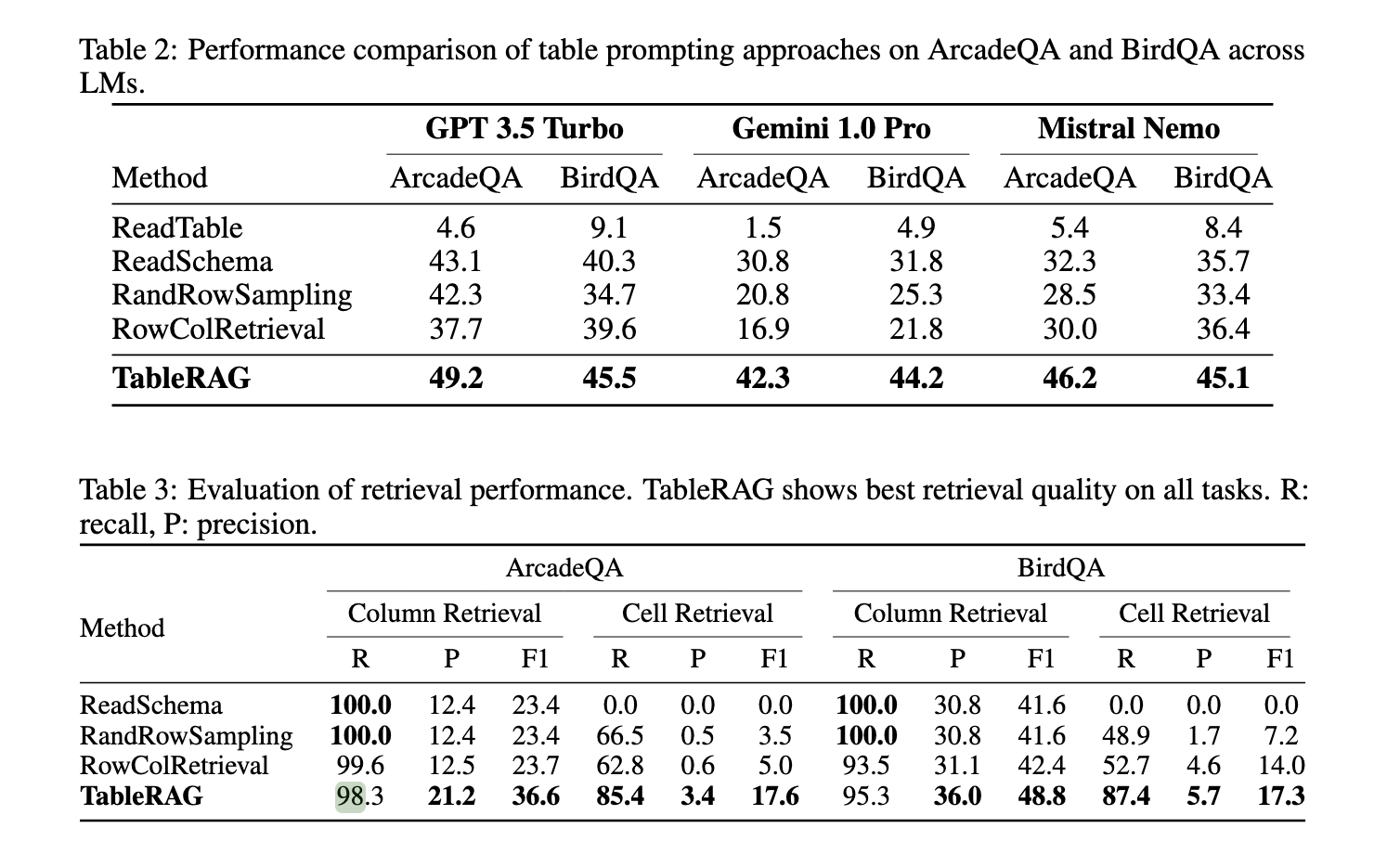
Present strategies used for large-scale desk understanding embrace row-column retrieval and schema-based approaches. Row-column retrieval methods choose essentially the most related rows and columns based mostly on their similarity to the question, establishing a sub-table for the LM to course of. Whereas this reduces the enter dimension, it nonetheless requires encoding whole rows and columns, which could be computationally costly. Then again, schema-based strategies solely make the most of the schema data, ignoring important cell values which will comprise the reply. These present strategies usually end in a trade-off between decreasing context dimension and preserving data, leaving room for enchancment in how LMs course of giant tables with excessive precision.
Researchers from Nationwide Taiwan College, Google Cloud AI Analysis, Google DeepMind and UC San Diego have launched a novel framework named TableRAG, which stands for Retrieval-Augmented Technology, particularly designed for LM-based desk understanding. The TableRAG framework integrates schema retrieval and cell retrieval strategies to optimize the presentation of desk knowledge to LMs. Not like conventional approaches, TableRAG first expands the question and retrieves a subset of related schema and cell values. This reduces the enter dimension whereas guaranteeing the LM receives all needed knowledge to generate an correct response. Via this hybrid retrieval methodology, TableRAG successfully addresses the problem of context overflow and mitigates the lack of essential data.
The methodology of TableRAG includes a number of important parts that work in tandem to boost its effectivity and accuracy. Initially, a schema retrieval course of identifies necessary columns by evaluating the relevance of their names and knowledge varieties to the question. This permits the LM to know the desk’s construction with out processing the whole content material. Subsequently, cell retrieval targets particular cell values throughout the recognized columns, guaranteeing that key data will not be neglected. Utilizing a mix of question enlargement strategies and frequency-aware truncation, TableRAG optimizes the number of essentially the most important knowledge factors. This strategy improves the encoding effectivity and ensures that the LM can give attention to essentially the most pertinent points of the desk. Additionally, the framework incorporates a token complexity evaluation to reduce computational overhead, sustaining the mannequin’s efficiency even with giant tables.
The efficiency of TableRAG has been evaluated towards present strategies utilizing benchmarks resembling ArcadeQA and BIRD-SQL. Outcomes point out that TableRAG achieves vital enhancements in retrieval high quality and total efficiency. For instance, in column and cell retrieval, TableRAG demonstrated a recall of 98.3% and precision of 85.4% on the ArcadeQA dataset, surpassing different strategies like ReadSchema and Row-Column Retrieval, which achieved recall charges of 12.4% and 66.5%, respectively. Furthermore, TableRAG confirmed a marked discount within the variety of tokens required for processing, resulting in quicker inference occasions and decrease computational prices. These outcomes spotlight the framework’s functionality to deal with advanced, large-scale desk constructions with excessive accuracy.
General, TableRAG units a brand new benchmark for desk understanding duties by effectively combining schema and cell retrieval mechanisms. The researchers demonstrated its effectiveness in dealing with datasets containing tens of millions of rows and columns, reaching superior outcomes whereas minimizing token utilization and computational bills. This novel strategy paves the best way for future developments in table-based reasoning and structured knowledge evaluation, offering a scalable answer for language fashions to course of and perceive expansive tabular datasets. The efficiency and adaptability of TableRAG underscore its potential to turn out to be a typical framework for large-scale desk understanding duties, revolutionizing the best way language fashions work together with structured knowledge in varied analysis and industrial purposes.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. In case you like our work, you’ll love our publication.. Don’t Neglect to hitch our 50k+ ML SubReddit
[Upcoming Event- Oct 17 202] RetrieveX – The GenAI Knowledge Retrieval Convention (Promoted)
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching purposes in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


