
Giant Language Fashions (LLMs) have gained important consideration within the discipline of simultaneous speech-to-speech translation (SimulS2ST). This know-how has turn into essential for low-latency communication in varied eventualities, equivalent to worldwide conferences, reside broadcasts, and on-line subtitles. The first problem in SimulS2ST lies in producing high-quality translated speech with minimal delay. This requires a classy coverage to find out the optimum moments to provoke translation inside streaming speech inputs (READ motion) and subsequently generate coherent goal speech outputs (WRITE motion).
Present methodologies face a number of challenges. Current simultaneous translation strategies primarily deal with text-to-text (Simul-T2TT) and speech-to-text translation (Simul-S2TT). These approaches sometimes depend on cascading exterior modules like speech recognition (ASR) and text-to-speech synthesis (TTS) to realize SimulS2ST. Nevertheless, this cascaded strategy tends to amplify inference errors progressively between modules and impedes the joint optimization of varied parts, highlighting the necessity for a extra built-in resolution.
Researchers have made a number of makes an attempt to handle the challenges in simultaneous speech-to-speech translation, primarily specializing in Simul-T2TT and Simul-S2TT translation strategies. In Simul-T2TT, approaches are categorized into fastened and adaptive strategies. Mounted strategies, such because the wait-k coverage, make use of a predetermined technique of ready for a set variety of tokens earlier than alternating between READ and WRITE actions. Adaptive strategies make the most of methods like monotonic consideration, alignments, non-autoregressive structure, or language fashions to dynamically carry out Simul-T2TT. For Simul-S2TT, the main target has been on speech segmentation. Mounted pre-decision strategies divide speech into equal-length segments, whereas adaptive strategies break up speech inputs into phrases or segments earlier than making use of Simul-T2TT insurance policies. Some researchers have additionally explored making use of offline fashions to Simul-S2TT duties. Regardless of these developments, these strategies nonetheless rely closely on cascading exterior modules, which may result in error propagation and hinder joint optimization of the interpretation course of.
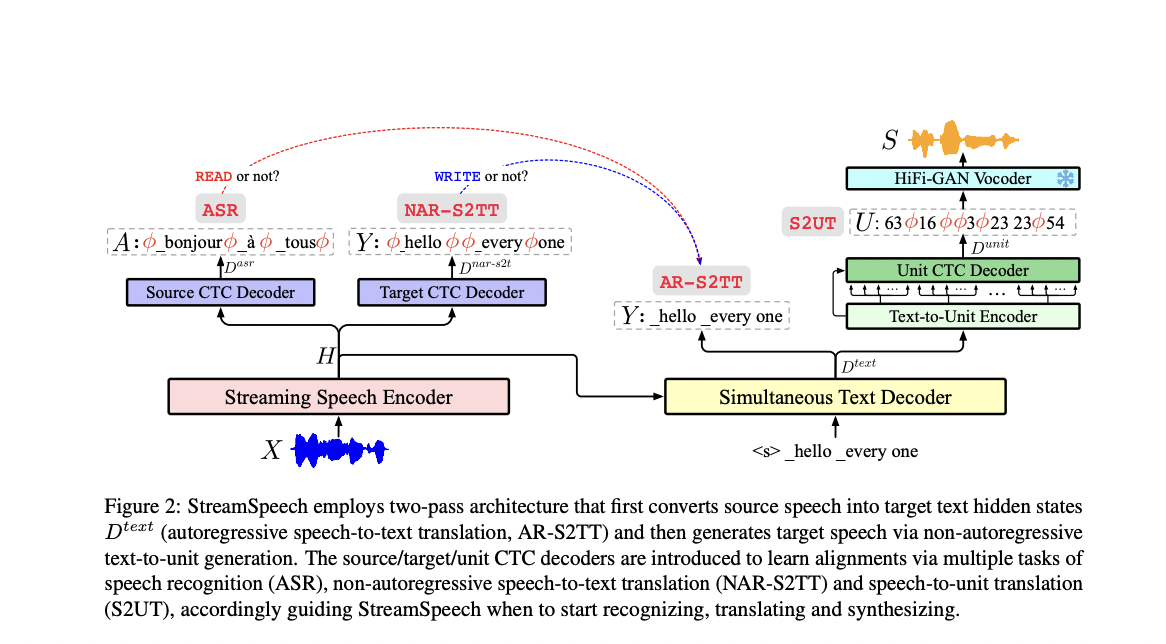
Researchers from Key Laboratory of Clever Info Processing, Institute of Computing Know-how, Chinese language Academy of Sciences (ICT/CAS), Key Laboratory of AI Security, Chinese language Academy of Sciences, College of Chinese language Academy of Sciences, Faculty of Future Science and Engineering, Soochow College current StreamSpeech, it addresses SimulS2ST challenges by introducing textual data for each supply and goal speech, offering intermediate supervision and guiding coverage by way of text-based alignments. This direct SimulS2ST mannequin employs a two-pass structure, first translating supply speech to focus on textual content hidden states, after which changing these to focus on speech. A number of CTC decoders, optimized through ASR and S2TT auxiliary duties, present intermediate supervision and be taught alignments for coverage steering. By collectively optimizing all modules by way of multi-task studying, StreamSpeech permits concurrent studying of translation and coverage, doubtlessly overcoming the constraints of earlier cascaded approaches.
StreamSpeech’s structure includes three primary parts: a streaming speech encoder, a simultaneous textual content decoder, and a synchronized text-to-unit era module. The streaming speech encoder makes use of a chunk-based Conformer design, which permits it to course of streaming inputs whereas sustaining bi-directional encoding inside native chunks. The simultaneous textual content decoder generates goal textual content by attending to the supply speech hidden states, guided by a coverage that determines when to generate every goal token. This coverage is knowledgeable by alignments discovered by way of a number of CTC decoders, that are optimized through auxiliary duties of ASR and S2TT. The text-to-unit era module employs a non-autoregressive structure to synchronously generate models comparable to the decoded textual content. Lastly, a HiFi-GAN vocoder synthesizes the goal speech from these models.
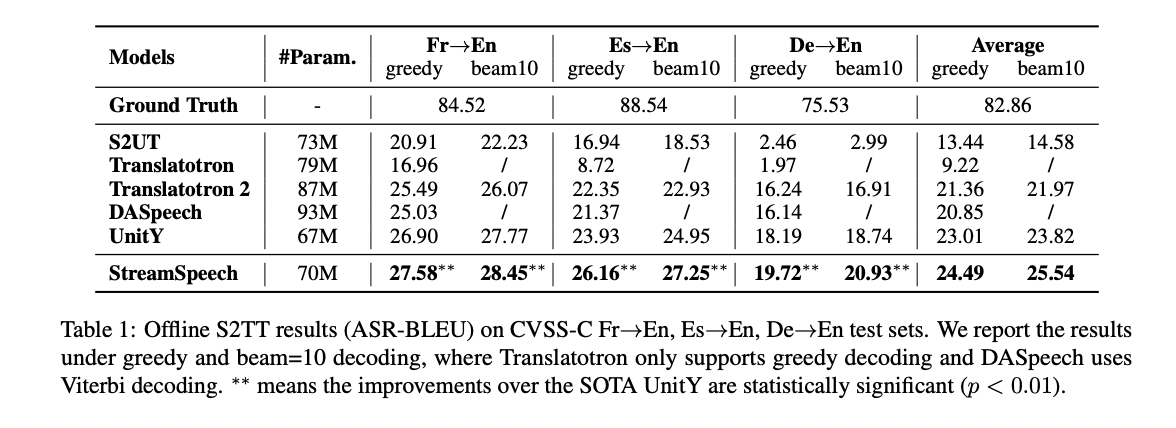
StreamSpeech demonstrates superior efficiency in each offline and S2ST duties. In offline S2ST, it outperforms the state-of-the-art UnitY mannequin with a mean enchancment of 1.5 BLEU. The mannequin’s structure, combining autoregressive speech-to-text translation with non-autoregressive text-to-unit era, proves efficient in balancing modeling capabilities and alignment seize. In simultaneous S2ST, StreamSpeech considerably outperforms the Wait-k baseline, displaying roughly 10 BLEU enchancment underneath low latency circumstances throughout French, Spanish, and German to English translations. The mannequin’s alignment-derived coverage permits extra applicable translation timing and coherent goal speech era. Additionally, StreamSpeech exhibits benefits over cascaded programs, highlighting the advantages of its direct strategy in decreasing error accumulation and enhancing total efficiency in Simul-S2ST duties.
StreamSpeech represents a major development in simultaneous speech-to-speech translation know-how. This revolutionary “All in One” seamless mannequin successfully handles streaming ASR, simultaneous translation, and real-time speech synthesis inside a unified framework. Its complete strategy permits for improved efficiency throughout a number of duties, together with offline speech-to-speech translation, streaming ASR, simultaneous speech-to-text translation, and simultaneous speech-to-speech translation.
Take a look at the Paper and GitHub. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to comply with us on Twitter.
Be a part of our Telegram Channel and LinkedIn Group.
When you like our work, you’ll love our publication..
Don’t Neglect to hitch our 45k+ ML SubReddit
Asjad is an intern guide at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the purposes of machine studying in healthcare.


