
Machine studying fashions, particularly these designed for code era, closely depend upon high-quality information throughout pretraining. This area has seen speedy development, with giant language fashions (LLMs) skilled on in depth datasets containing code from varied sources. The problem for researchers is to make sure that the information used is ample and of top of the range, as this considerably impacts the mannequin’s potential to deal with advanced duties. In code-related functions, well-structured, annotated, and clear information ensures that fashions can generate correct, environment friendly, and dependable outputs for real-world programming duties.
A major subject in code mannequin improvement is the shortage of exact definitions of “high-quality” information. Whereas huge quantities of code information can be found, a lot comprises noise, redundancy, or irrelevant info, which may degrade mannequin efficiency. Counting on uncooked information, even after filtering, typically results in inefficiencies. This downside turns into evident when fashions skilled on giant datasets underperform on sensible benchmarks. To deal with this, there was an elevated concentrate on not simply buying giant quantities of information however curating information that aligns properly with downstream functions, bettering the mannequin’s predictive skills and general utility.
Traditionally, the pretraining of code fashions concerned scraping giant repositories akin to GitHub and processing uncooked information by way of fundamental filtering and deduplication strategies. Researchers would then apply random forest classifiers or easy high quality filters to determine educationally beneficial code, as seen in fashions like Phi-1. Whereas these strategies improved information high quality to an extent, they weren’t sufficient to attain optimum efficiency on tougher coding duties. Newer approaches have adopted extra refined instruments, akin to BERT-based annotators, to categorise code high quality and choose information that may extra successfully contribute to the mannequin’s success.
The analysis staff from Snowflake AI Analysis, College of Illinois at Urbana-Champaign, and Seoul Nationwide College launched Arctic-SnowCoder-1.3B, a novel strategy to pretraining code fashions by progressively refining information high quality over three distinct phases. This methodology mixed common pretraining, continued pretraining with high-quality information, and remaining pretraining with artificial information. The researchers leveraged present datasets, akin to The Stack v1 and GitHub crawls, and synthetic information generated utilizing Llama-3.1-70B to construct a smaller, extra environment friendly mannequin. This course of centered on optimizing the information utilized in every section to make sure that the mannequin may outperform its opponents.
Within the first section, Arctic-SnowCoder was skilled on 500 billion code tokens derived from uncooked information sources akin to The Stack v1 and GitHub. This information underwent fundamental preprocessing steps, together with filtering and deduplication, leading to roughly 400 billion distinctive tokens. Throughout this section, the mannequin was skilled with out superior high quality filters, and the information was grouped by programming language and repository. This strategy ensured a broad code information base however required additional refinement. Within the second section, the analysis staff chosen 50 billion tokens from this preliminary dataset, specializing in high-quality information. A BERT-based high quality annotator was employed to rank code information, and the highest 12.5 billion tokens had been repeated 4 occasions to coach the mannequin additional. This section considerably improved the information high quality, because the annotator was particularly skilled to pick out tokens aligned with the mannequin’s downstream functions.
The ultimate section concerned enhanced pretraining with 5 billion artificial tokens generated by Llama-3.1-70B. These tokens had been created utilizing the top-quality information from section two as seeds, remodeling lower-quality information into artificial high-quality paperwork. This section additional refined the mannequin’s potential to generate exact code by making certain the coaching information was related and consultant of real-world coding duties. The end result was a mannequin that had undergone progressively extra rigorous coaching, with every section contributing to its enhanced efficiency.
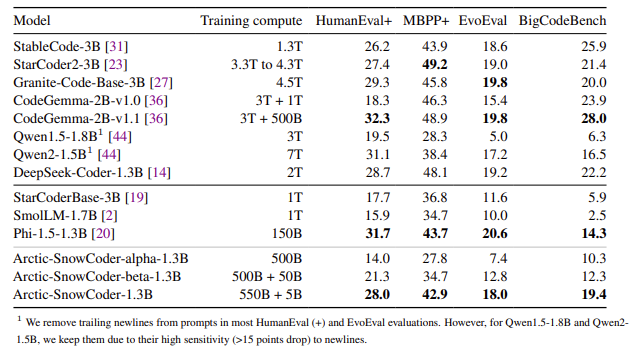
The effectiveness of this strategy is obvious in Arctic-SnowCoder-1.3B’s outcomes. Regardless of being skilled on solely 555 billion tokens, it considerably outperformed different fashions of comparable dimension, akin to Phi-1.5-1.3B and StarCoderBase-3B, which had been skilled on over 1 trillion tokens. On the BigCodeBench benchmark, which focuses on sensible and difficult programming duties, Arctic-SnowCoder exceeded the efficiency of Phi-1.5-1.3B by 36%. It surpassed StarCoder2-3B, skilled on over 3 trillion tokens, on HumanEval+, reaching a rating of 28.0 in comparison with StarCoder2-3B’s 27.4. Regardless of being skilled on fewer tokens, the mannequin’s potential to carry out properly highlights the significance of information high quality over amount.

In conclusion, Arctic-SnowCoder-1.3B illustrates the crucial function of progressively refined, high-quality information within the pretraining of code fashions. By adopting a three-phase strategy, the researchers enhanced the mannequin’s efficiency considerably in comparison with bigger fashions skilled on much more tokens. This methodology demonstrates the significance of aligning pretraining information with downstream duties and offers sensible tips for future mannequin improvement. Arctic-SnowCoder’s success is a testomony to the worth of high-quality information, exhibiting that cautious information curation and artificial information era can result in substantial enhancements in code era fashions.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to observe us on Twitter and LinkedIn. Be a part of our Telegram Channel.
For those who like our work, you’ll love our e-newsletter..
Don’t Overlook to hitch our 50k+ ML SubReddit
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.


