
Optimizing the effectivity of Feedforward Neural Networks (FFNs) inside Transformer architectures is a major problem in AI. Massive language fashions (LLMs) are extremely resource-intensive, requiring substantial computational energy and power, which restricts their applicability and raises environmental issues. Effectively addressing this problem is essential for selling sustainable AI practices and making superior AI applied sciences extra accessible by decreasing operational prices.
Present strategies to reinforce FFN effectivity usually contain low-rank approximations and structured matrices. Approaches equivalent to LowRank and BlockDense decompositions have been proposed to scale back parameters and FLOPs. Nevertheless, these strategies typically face limitations in sensible situations. As an illustration, low-rank approximations can undergo from poor optimization dynamics as a result of elevated symmetries resulting in saddle factors, and structured matrices can lead to suboptimal coaching dynamics and diminished effectivity in on-line decoding as a result of poor parallelism on GPUs. These limitations make the prevailing strategies much less appropriate for real-time functions and large-scale deployments.
A crew of researchers from Google DeepMind and EPFL suggest a hybrid construction combining low-rank and block-diagonal matrices with a way termed ‘self-guided coaching.’ This new technique goals to mitigate the optimization points by introducing a dense matrix in the course of the preliminary coaching section, which is steadily phased out, permitting the structured matrices to take over. This strategy ensures higher coaching stability and quicker convergence. The hybrid technique not solely addresses computational effectivity but additionally ensures that optimization dynamics are clean, decreasing the incidence of loss spikes and instability and thus representing a major development over current strategies.
The analysis employs structured linear parameterization, the place the FFN layers are approximated utilizing mixtures of low-rank and block-diagonal matrices. The important thing innovation is the ‘self-guided coaching’ technique, the place the dense matrix aids within the early coaching phases, progressively transitioning to environment friendly structured types. The coaching makes use of the RefinedWeb dataset, which incorporates 600B tokens, and employs superior GPU optimizations like combined precision coaching, Flash Consideration, and rotary embeddings. Hyperparameters equivalent to studying charges and dropout charges are meticulously tuned to make sure optimum efficiency. The proposed fashions are examined at scales starting from 110M to 1.3B parameters, demonstrating scalability and robustness.
The revolutionary technique considerably enhances coaching and inference effectivity. The structured FFN fashions achieved a 1.35× speed-up in coaching and a 2.5× quicker FFN at inference with solely a slight enhance in perplexity. The ‘self-guided coaching’ approach resulted in a 0.4 discount in perplexity on a 1.3B parameter mannequin with constant coaching FLOPs. The strategy demonstrated improved efficiency metrics, together with decrease perplexity and better throughput, validating its efficacy and superiority over conventional FFNs.
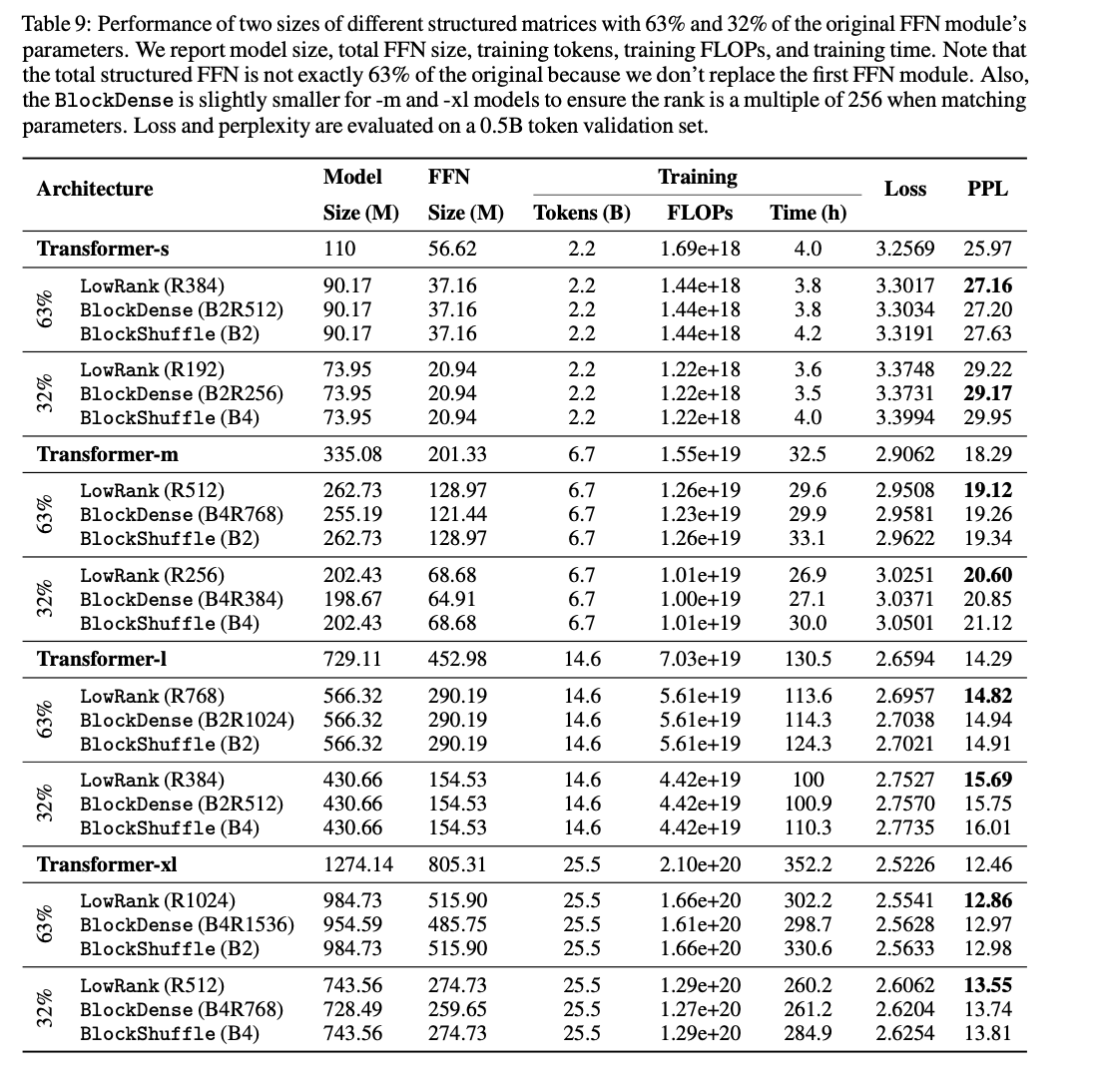
In conclusion, this analysis presents a major contribution to optimizing massive language fashions by introducing a hybrid structured FFN strategy mixed with self-guided coaching. This innovation addresses essential limitations of current strategies, leading to improved coaching effectivity and mannequin efficiency. The findings counsel that this development might propel AI analysis ahead by making large-scale fashions extra computationally environment friendly and accessible, thereby selling sustainable and democratized AI growth.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to observe us on Twitter.
Be a part of our Telegram Channel and LinkedIn Group.
Should you like our work, you’ll love our e-newsletter..
Don’t Overlook to affix our 45k+ ML SubReddit
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Expertise, Kharagpur. He’s keen about information science and machine studying, bringing a powerful educational background and hands-on expertise in fixing real-life cross-domain challenges.


