
Massive language fashions (LLMs) have made vital leaps in pure language processing, demonstrating exceptional generalization capabilities throughout various duties. Nevertheless, as a consequence of inconsistent adherence to directions, these fashions face a vital problem in producing precisely formatted outputs, similar to JSON. This limitation poses a big hurdle for AI-driven functions requiring structured LLM outputs built-in into their information streams. Because the demand for managed and structured outputs from LLMs grows, researchers are confronted with the pressing must develop strategies that may guarantee exact formatting whereas sustaining the fashions’ highly effective language era talents.
Researchers have explored numerous approaches to mitigate the problem of format-constrained era in LLMs. These strategies will be categorized into three most important teams: pre-generation tuning, in-generation management, and post-generation parsing. Pre-generation tuning includes modifying coaching information or prompts to align with particular format constraints. In-generation management strategies intervene through the decoding course of, utilizing strategies like JSON Schema, common expressions, or context-free grammars to make sure format compliance. Nevertheless, these strategies usually compromise response high quality. Publish-generation parsing strategies refine the uncooked output into structured codecs utilizing post-processing algorithms. Whereas every strategy gives distinctive benefits, all of them face limitations in balancing format accuracy with response high quality and generalization capabilities.
Researchers from the Beijing Academy of Synthetic Intelligence, AstralForge AI Lab, Institute of Computing Expertise, Chinese language Academy of Sciences, College of Digital Science and Expertise of China, Harbin Institute of Expertise, School of Computing and Knowledge Science, Nanyang Technological College have proposed Sketch, an progressive toolkit designed to reinforce the operation of LLMs and guarantee formatted output era. This framework introduces a set of activity description schemas for numerous NLP duties, permitting customers to outline their particular necessities, together with activity aims, labeling programs, and output format specs. Sketch permits out-of-the-box deployment of LLMs for unfamiliar duties whereas sustaining output format correctness and conformity.
The framework’s key contributions embody:
- simplifying LLM operation by way of predefined schemas
- optimizing efficiency through dataset creation and mannequin fine-tuning primarily based on LLaMA3-8B-Instruct
- integrating constrained decoding frameworks for exact output format management.
These developments improve the reliability and precision of LLM outputs, making Sketch a flexible answer for various NLP functions in each analysis and industrial settings.
Sketch’s structure contains 4 key steps: schema choice, activity instantiation, immediate packaging, and era. Customers first select an applicable schema from a predefined set aligned with their NLP activity necessities. Throughout activity instantiation, customers populate the chosen schema with task-specific particulars, making a JSON-format activity occasion. The immediate packaging step robotically converts the duty enter right into a structured immediate for LLM interplay, integrating activity description, label structure, output format, and enter information.

Within the era part, Sketch can straight produce responses or make use of extra exact management strategies. It optionally integrates the lm-format-enforcer, utilizing context-free grammar to make sure output format compliance. Along with that, Sketch makes use of the JSON-schema software for output validation, resampling or throwing exceptions for non-compliant outputs. This structure permits managed formatting and simple interplay with LLMs throughout numerous NLP duties, streamlining the method for customers whereas sustaining output accuracy and format consistency.

Sketch-8B enhances LLaMA3-8B-Instruct’s capacity to generate structured information adhering to JSON schema constraints throughout numerous duties. The fine-tuning course of focuses on two key features: guaranteeing strict adherence to JSON schema constraints and fostering sturdy activity generalization. To realize this, two focused datasets are constructed: NLP activity information and schema following information.
The NLP activity information contains over 20 datasets masking textual content classification, textual content era, and data extraction, with 53 activity situations. The schema following information consists of 20,000 items of fine-tuning information generated from 10,000 various JSON schemas. The fine-tuning technique optimizes each format adherence and NLP activity efficiency utilizing a blended dataset strategy. The coaching goal is formulated as a log-probability maximization of the right output sequence given the enter immediate. This strategy balances enhancing the mannequin’s adherence to varied output codecs and enhancing its NLP activity capabilities.
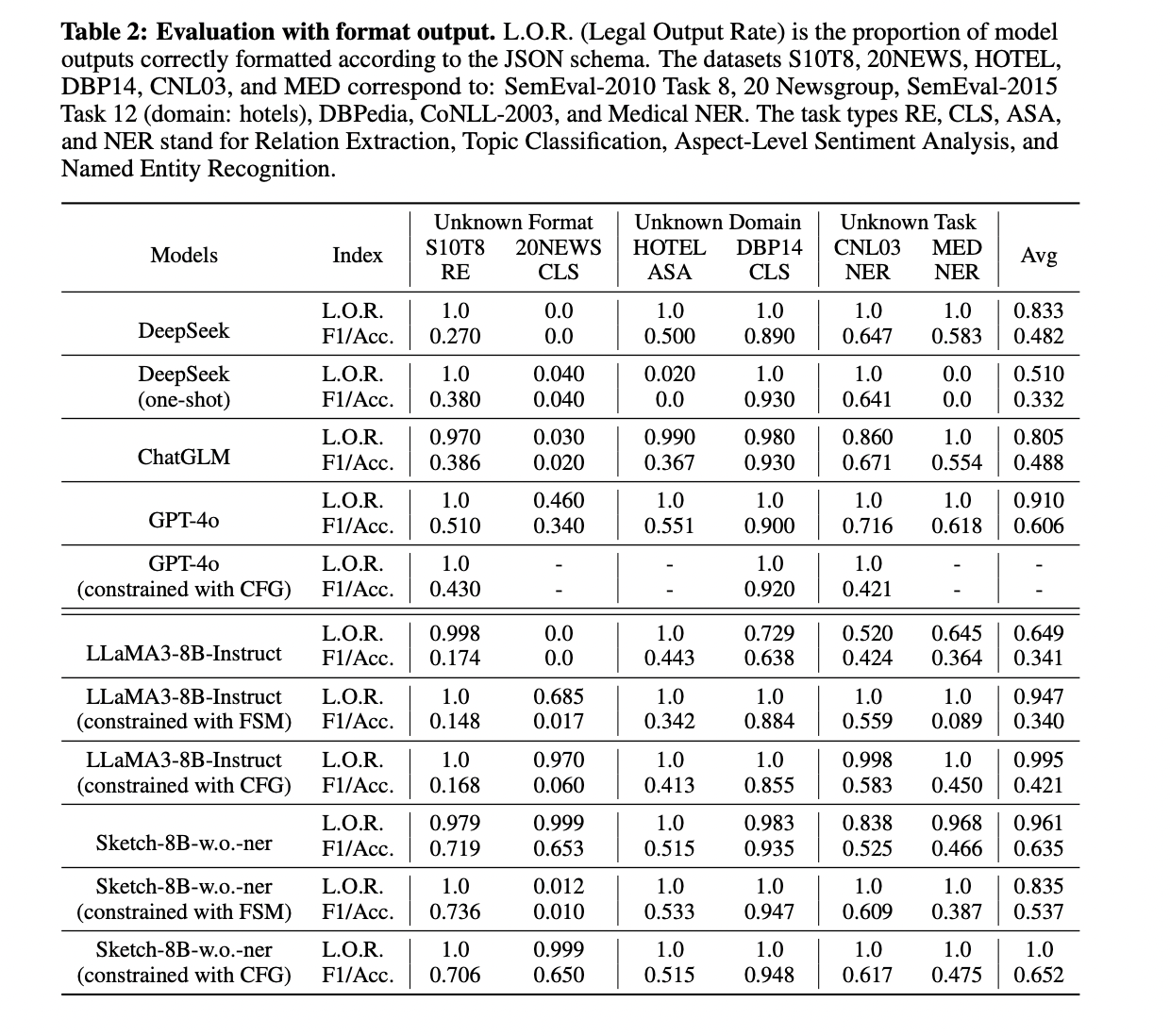
The analysis of Sketch-8B-w.o.-ner demonstrates its robust generalization capabilities throughout unknown codecs, domains, and duties. In schema adherence, Sketch-8B-w.o.-ner achieves a median authorized output ratio of 96.2% below unconstrained situations, considerably outperforming the baseline LLaMA3-8B-Instruct’s 64.9%. This enchancment is especially notable in advanced codecs like 20NEWS, the place Sketch-8B-w.o.-ner maintains excessive efficiency whereas LLaMA3-8B-Instruct fully fails.
Efficiency comparisons reveal that Sketch-8B-w.o.-ner persistently outperforms LLaMA3-8B-Instruct throughout numerous decoding methods and datasets. In comparison with mainstream fashions like DeepSeek, ChatGLM, and GPT-4o, Sketch-8B-w.o.-ner reveals superior efficiency on unknown format datasets and comparable outcomes on unknown area datasets. Nevertheless, it faces some limitations on unknown activity datasets as a consequence of its smaller mannequin dimension.
The analysis additionally highlights the inconsistent results of constrained decoding strategies (FSM and CFG) on activity efficiency. Whereas these strategies can enhance authorized output ratios, they don’t persistently improve activity analysis scores, particularly for datasets with advanced output codecs. This means that present constrained decoding approaches is probably not uniformly dependable for real-world NLP functions.
This research introduces Sketch, a big development in simplifying and optimizing the functions of enormous language fashions. By introducing a schema-based strategy, it successfully addresses the challenges of structured output era and mannequin generalization. The framework’s key improvements embody a complete schema structure for activity description, a strong information preparation and mannequin fine-tuning technique for enhanced efficiency, and the combination of a constrained decoding framework for exact output management.
Experimental outcomes convincingly display the prevalence of the fine-tuned Sketch-8B mannequin in adhering to specified output codecs throughout numerous duties. The effectiveness of the custom-built fine-tuning dataset, notably the schema following information, is obvious within the mannequin’s improved efficiency. Sketch not solely enhances the sensible applicability of LLMs but additionally paves the best way for extra dependable and format-compliant outputs in various NLP duties, marking a considerable step ahead in making LLMs extra accessible and efficient for real-world functions.
Try the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. For those who like our work, you’ll love our e-newsletter..
Don’t Neglect to affix our 50k+ ML SubReddit
Asjad is an intern guide at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the functions of machine studying in healthcare.


