
The pursuit of producing lifelike photographs, movies, and sounds via synthetic intelligence (AI) has just lately taken a major leap ahead. Nevertheless, these developments have predominantly centered on single modalities, ignoring our world’s inherently multimodal nature. Addressing this shortfall, researchers have launched a pioneering optimization-based framework designed to combine visible and audio content material creation seamlessly. This revolutionary strategy makes use of present pre-trained fashions, notably the ImageBind mannequin, to determine a shared representational area that facilitates the technology of content material that’s each visually and aurally cohesive.
The problem of synchronizing video and audio technology presents a singular set of complexities. Conventional strategies, which regularly contain producing video and audio in separate levels, fall quick in delivering the specified high quality and management. Recognizing the restrictions of such two-stage processes, researchers have explored the potential of leveraging highly effective, pre-existing fashions that excel in particular person modalities. A key discovery was the ImageBind mannequin’s capacity to hyperlink completely different knowledge varieties inside a unified semantic area, thus serving as an efficient “aligner” within the content material technology course of.
On the core of this methodology is the usage of diffusion fashions, which generate content material by progressively lowering noise. The proposed system employs ImageBind as a type of referee, offering suggestions on the alignment between the partially generated picture and its corresponding audio. This suggestions is then used to fine-tune the technology course of, guaranteeing a harmonious audio-visual match. The strategy is akin to classifier steerage in diffusion fashions however utilized throughout modalities to keep up semantic coherence.
The researchers additional refined their system to sort out challenges such because the semantic sparsity of audio content material (e.g., background music) by incorporating textual descriptions for richer steerage. Moreover, a novel “guided immediate tuning” approach was developed to reinforce content material technology, significantly for audio-driven video creation. This methodology permits for dynamic adjustment of the technology course of primarily based on textual prompts, guaranteeing a better diploma of content material alignment and constancy.
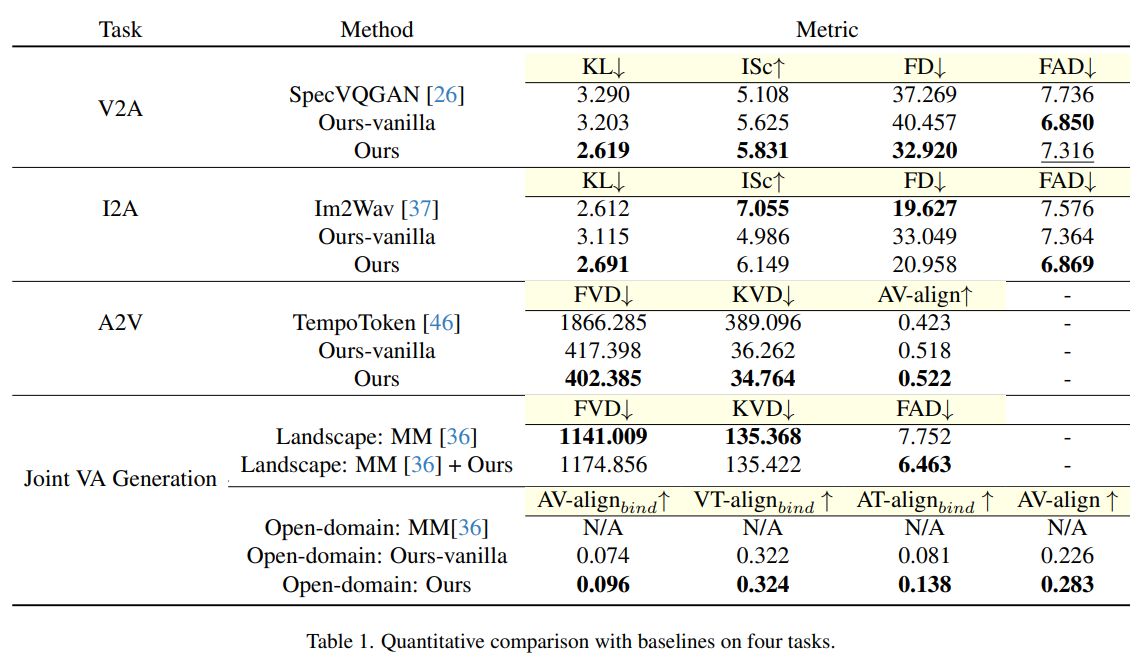
To validate their strategy, the researchers carried out a complete comparability towards a number of baselines throughout completely different technology duties. For video-to-audio technology, they chose SpecVQGAN as a baseline, whereas for image-to-audio duties, Im2Wav served because the comparability level. TempoTokens was chosen for the audio-to-video technology process. Moreover, MM-Diffusion, a state-of-the-art mannequin for joint video and audio technology in a restricted area, was used as a baseline for evaluating the proposed methodology in open-domain duties. These rigorous comparisons revealed that the proposed methodology constantly outperformed present fashions, demonstrating its effectiveness and suppleness in bridging visible and auditory content material technology.
This analysis gives a flexible, resource-efficient pathway for integrating visible and auditory content material technology, setting a brand new benchmark for AI-driven multimedia creation. The flexibility to harness pre-existing fashions for this goal hints on the potential for future developments, the place enhancements in foundational fashions may result in much more compelling and cohesive multimedia experiences.
Regardless of its spectacular capabilities, the researchers acknowledge limitations primarily stemming from the technology capability of the foundational fashions, akin to AudioLDM and AnimateDiff. The present efficiency in points like visible high quality, advanced idea composition, and movement dynamics in audio-to-video and joint video-audio duties suggests room for future enhancements. Nevertheless, the adaptability of their strategy signifies that integrating extra superior generative fashions may additional refine and enhance the standard of multimodal content material creation, providing a promising outlook for the longer term.
Take a look at the Paper and Venture. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to observe us on Twitter and Google Information. Be part of our 38k+ ML SubReddit, 41k+ Fb Neighborhood, Discord Channel, and LinkedIn Group.
Should you like our work, you’ll love our publication..
Don’t Overlook to affix our Telegram Channel
You might also like our FREE AI Programs….
Vineet Kumar is a consulting intern at MarktechPost. He’s at present pursuing his BS from the Indian Institute of Know-how(IIT), Kanpur. He’s a Machine Studying fanatic. He’s captivated with analysis and the most recent developments in Deep Studying, Pc Imaginative and prescient, and associated fields.


