
Scale AI has introduced the launch of SEAL Leaderboards, an progressive and expert-driven rating system for big language fashions (LLMs). This initiative is a product of the Security, Evaluations, and Alignment Lab (SEAL) at Scale, which is devoted to offering impartial, reliable evaluations of AI fashions. The SEAL Leaderboards goal to deal with the rising want for dependable efficiency comparisons as LLMs grow to be extra superior and extensively utilized.
With a whole bunch of LLMs, evaluating their efficiency and security has grow to be more and more difficult. Scale, a trusted third-party evaluator for main AI labs, has developed the SEAL Leaderboards to rank frontier LLMs utilizing curated personal datasets that can not be manipulated. These evaluations are performed by verified area consultants, making certain the rankings are unbiased and supply a real measure of mannequin efficiency.
The SEAL Leaderboards initially cowl a number of vital domains, together with:
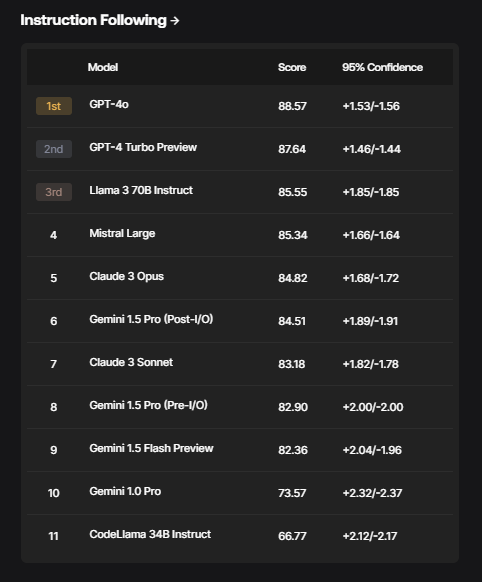
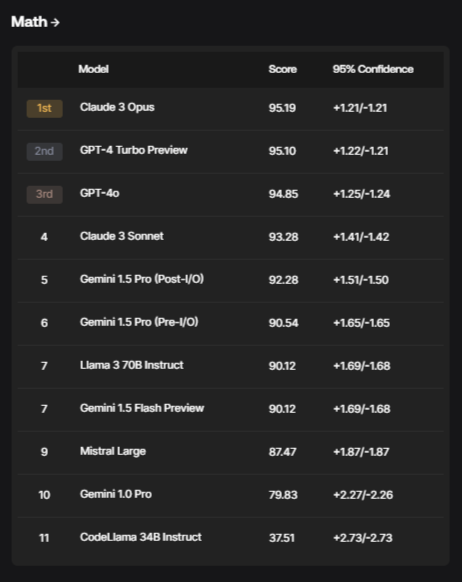
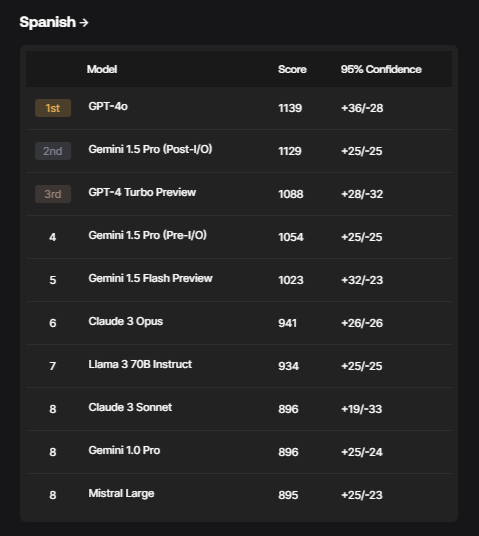
Every area options immediate units created from scratch by consultants, tailor-made to judge efficiency in that particular space finest. The evaluators are rigorously vetted, making certain they possess the required domain-specific experience.
To take care of the integrity of the evaluations, Scale’s datasets stay personal and unpublished, stopping them from being exploited or included in mannequin coaching information. The SEAL Leaderboards restrict entries from builders who may need accessed the precise immediate units, making certain unbiased outcomes. Scale collaborates with trusted third-party organizations to assessment their work, including one other layer of accountability.
Scale’s SEAL analysis lab, launched final November, is uniquely positioned to sort out a number of persistent challenges in AI analysis:
- Contamination and Overfitting: Making certain high-quality, uncontaminated analysis datasets.
- Inconsistent Reporting: Standardizing mannequin comparisons and reliability of analysis outcomes.
- Unverified Experience: Rigorous evaluation of evaluators’ experience in particular domains.
- Insufficient Tooling: Offering strong instruments for understanding and iterating on analysis outcomes with out overfitting.
These efforts goal to reinforce AI mannequin evaluations’ total high quality, transparency, and standardization.
Scale plans to constantly replace the SEAL Leaderboards with new immediate units and frontier fashions as they grow to be obtainable, refreshing the rankings a number of occasions a 12 months to replicate the most recent developments in AI. This dedication ensures that the leaderboards stay related and up-to-date, driving improved analysis requirements throughout the AI group.
Along with the leaderboards, Scale has introduced the overall availability of Scale Analysis, a platform designed to assist AI researchers, builders, enterprises, and public sector organizations analyze, perceive, and enhance their AI fashions and functions. This platform marks a step ahead in Scale’s mission to speed up AI improvement by way of rigorous, impartial evaluations.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.


