
The sphere of language fashions has seen exceptional progress, pushed by transformers and scaling efforts. OpenAI’s GPT collection demonstrated the ability of accelerating parameters and high-quality knowledge. Improvements like Transformer-XL expanded context home windows, whereas fashions akin to Mistral, Falcon, Yi, DeepSeek, DBRX, and Gemini pushed capabilities additional.
Visible language fashions (VLMs) have additionally superior quickly. CLIP pioneered shared vision-language function areas by way of contrastive studying. BLIP and BLIP-2 improved on this by aligning pre-trained encoders with massive language fashions. LLaVA and InstructBLIP confirmed robust generalization throughout duties. Kosmos-2 and PaLI-X scaled pre-training knowledge utilizing pseudo-labeled bounding bins, linking improved notion to higher high-level reasoning.
Latest developments in visible language fashions (VLMs) have targeted on aligning visible encoders with massive language fashions (LLMs) to reinforce capabilities throughout varied visible duties. Whereas progress has been made in coaching strategies and architectures, datasets usually stay simplistic. To handle this, researchers are exploring VLM-based knowledge augmentation as a substitute for labor-intensive human-created datasets. The paper introduces a novel coaching regime involving self-augment and specialist-augment steps, iteratively refining pretraining knowledge to generate stronger fashions.
The analysis focuses on auto-regressive Visible Language Fashions (VLMs), using a three-stage coaching paradigm: align-pretrain-SFT. The methodology introduces a novel augmentation coaching regime, beginning with self-augmenting VLM coaching in a bootstrapped loop, adopted by specialist augmenting to take advantage of expertise gained throughout SFT. This strategy progressively enhances knowledge high quality by enhancing visible semantics and decreasing hallucinations, straight boosting VLM efficiency. The research introduces the VILA 2 mannequin household, which outperforms present strategies throughout important benchmarks with out extra complexities.
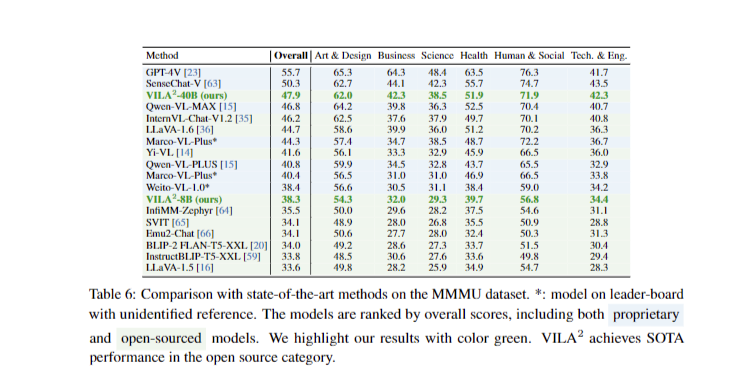
VILA 2 achieves state-of-the-art efficiency on the MMMU check dataset leaderboard amongst open-sourced fashions, utilizing solely publicly obtainable datasets. The self-augmentation course of steadily removes hallucinations from captions, enhancing high quality and accuracy. Via iterative rounds, VILA 2 considerably will increase caption size and high quality, with enhancements noticed primarily after round-1. The enriched captions constantly outperform state-of-the-art strategies on varied visual-language benchmarks, demonstrating the effectiveness of enhanced pre-training knowledge high quality.
The specialist-augmented coaching additional enhances VILA 2’s efficiency by infusing domain-specific experience into the generalist VLM, enhancing accuracy throughout a variety of duties. The mix of self-augmented and specialist-augmented coaching methods ends in important efficiency boosts throughout varied benchmarks, pushing VILA’s capabilities to new heights. This system of recapturing and coaching cycles not solely improves knowledge high quality but in addition enhances mannequin efficiency, contributing to constant accuracy enhancements and new state-of-the-art outcomes.
Outcomes present gradual removing of hallucinations and improved caption high quality because the self-augmenting course of iterates. The mixed self-augmented and specialist-augmented coaching strategy results in enhanced accuracy throughout varied duties, reaching new state-of-the-art outcomes on the MMMU leaderboard amongst open-sourced fashions. This system demonstrates the potential of iterative knowledge refinement and mannequin enchancment in advancing visible language understanding capabilities.
In conclusion, VILA 2 represents a major leap ahead in visible language fashions, reaching state-of-the-art efficiency by way of modern self-augmentation and specialist-augmentation methods. By iteratively refining pretraining knowledge utilizing solely publicly obtainable datasets, the mannequin demonstrates superior caption high quality, lowered hallucinations, and improved accuracy throughout varied visual-language duties. The mix of generalist data with domain-specific experience ends in important efficiency boosts throughout benchmarks. VILA 2’s success highlights the potential of data-centric enhancements in advancing multi-modal AI techniques, paving the way in which for extra subtle visible and textual info understanding. This strategy not solely enhances mannequin efficiency but in addition showcases the effectiveness of leveraging present fashions to enhance knowledge high quality, probably revolutionizing the event of future AI techniques.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. For those who like our work, you’ll love our publication..
Don’t Overlook to affix our 47k+ ML SubReddit
Discover Upcoming AI Webinars right here

Shoaib Nazir is a consulting intern at MarktechPost and has accomplished his M.Tech twin diploma from the Indian Institute of Know-how (IIT), Kharagpur. With a robust ardour for Knowledge Science, he’s significantly within the numerous functions of synthetic intelligence throughout varied domains. Shoaib is pushed by a need to discover the most recent technological developments and their sensible implications in on a regular basis life. His enthusiasm for innovation and real-world problem-solving fuels his steady studying and contribution to the sphere of AI


