
Transformers have discovered widespread utility in various duties spanning textual content classification, map development, object detection, level cloud evaluation, and audio spectrogram recognition. Their versatility extends to multimodal duties, exemplified by CLIP’s use of image-text pairs for superior picture recognition. This underscores transformers’ efficacy in establishing common sequence-to-sequence modeling, creating embeddings that unify information illustration throughout a number of modalities.
CLIP illustrates a notable methodology, leveraging information from one modality (textual content) to reinforce a mannequin’s efficiency in one other (photographs). Nonetheless, the requirement for related paired information samples is a big limitation typically neglected in analysis. As an illustration, whereas coaching with image-audio pairs may enhance picture recognition, the efficacy of a pure audio dataset in enhancing ImageNet classification with out significant connections between audio and picture samples stays to be decided.
Researchers from The Chinese language College of Hong Kong and Tencent AI Lab have proposed the Multimodal Pathway Transformer (M2PT). The researchers search to reinforce transformers designed for particular modalities, similar to ImageNet, by incorporating irrelevant information from unrelated modalities like audio or level cloud datasets. This method distinguishes itself from others that depend on paired or interleaved information from completely different modalities. The aim is to exhibit enchancment in mannequin efficiency by connecting transformers of disparate modalities, the place the information samples from the goal modality are deliberately irrelevant to these of the auxiliary modalities.
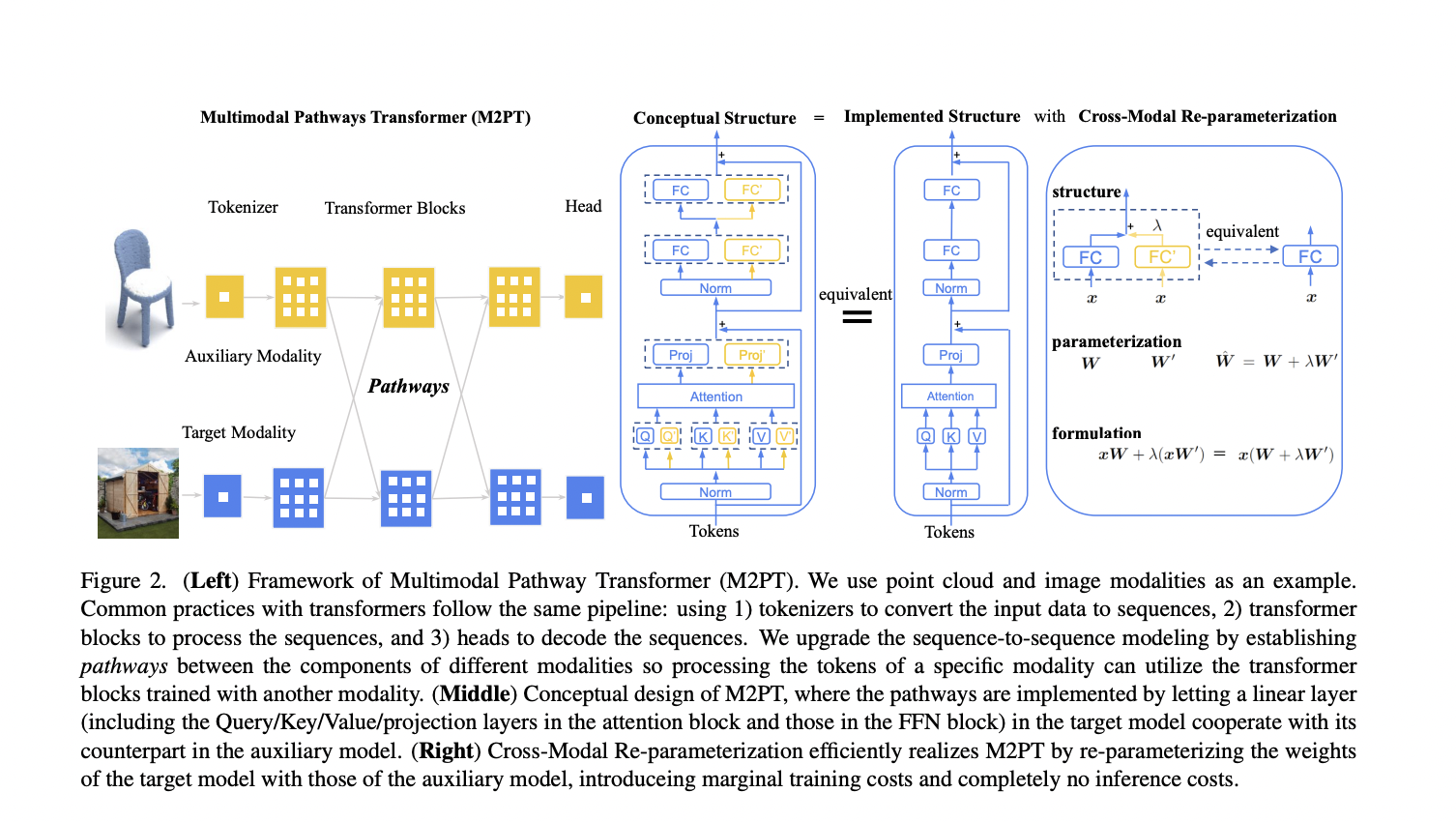
M2PT connects elements of a goal modality mannequin with an auxiliary mannequin by way of pathways. This permits the processing of goal modality information by each fashions, using the transformer’s common sequence-to-sequence modeling capabilities from two modalities. The method entails a modality-specific tokenizer and task-specific head, and it incorporates auxiliary mannequin transformer blocks utilizing cross-module re-parameterization, permitting the exploitation of extra weights with out inference prices. By incorporating irrelevant information from different modalities, their technique demonstrates substantial and constant efficiency enhancements throughout picture, level cloud, video, and audio recognition duties.
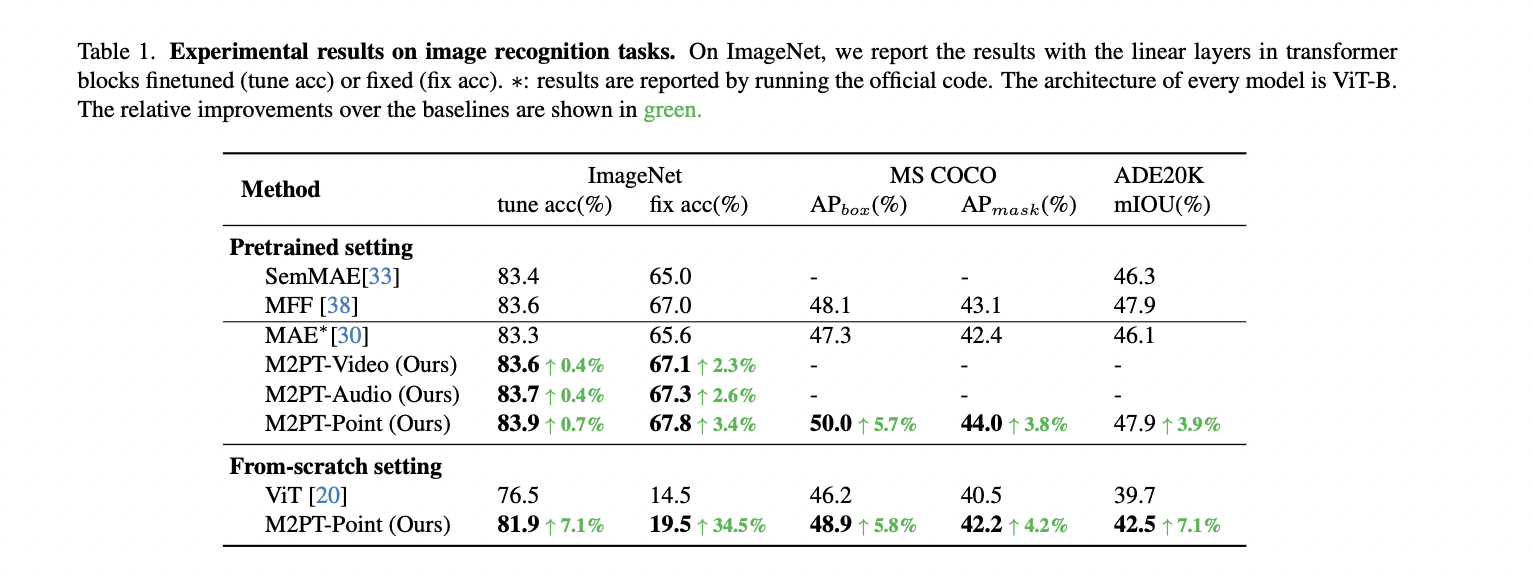
The researchers current experimental findings in picture recognition, using the ViT-B structure throughout fashions. M2PT-Video, M2PT-Audio, and M2PT-Level are in contrast with SemMAE, MFF, and MAE. Outcomes on ImageNet, MS COCO, and ADE20K exhibit accuracy and activity efficiency enhancements. M2PT-Level notably excels, showcasing substantial enhancements in APbox, APmask, and mIOU metrics in comparison with baseline fashions.
In conclusion, the paper introduces the Multimodal Pathway to reinforce transformer efficiency on a particular modality by incorporating irrelevant information from different modalities. The researchers current Cross-Modal Re-parameterization as a tangible implementation, enabling the utilization of auxiliary weights with out incurring inference prices. Experimental outcomes constantly present substantial efficiency enhancements throughout picture, level cloud, video, and audio recognition duties, emphasizing the efficacy of leveraging irrelevant information from various modalities in transformer-based fashions.
Take a look at the Paper and Github. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to observe us on Twitter. Be a part of our 36k+ ML SubReddit, 41k+ Fb Neighborhood, Discord Channel, and LinkedIn Group.
Should you like our work, you’ll love our publication..
Don’t Neglect to affix our Telegram Channel
Asjad is an intern guide at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the purposes of machine studying in healthcare.


