
Data retrieval (IR) fashions face important challenges in delivering clear and intuitive search experiences. Present methodologies primarily depend on a single semantic similarity rating to match queries with passages, resulting in a probably opaque consumer expertise. This method usually requires customers to interact in a cumbersome strategy of discovering particular key phrases, making use of varied filters in superior search settings, and iteratively refining their queries based mostly on earlier search outcomes. The necessity for customers to craft the “excellent” question to retrieve desired passages highlights the restrictions of present IR methods in offering environment friendly and user-friendly search capabilities.
Latest developments in IR fashions have launched using directions, transferring past conventional dense retriever coaching that centered on similarity capabilities akin to phrase-level matching. Early efforts like TART and Teacher integrated easy job prefixes throughout coaching. Newer fashions comparable to E5-Mistral, GritLM, and NV-Retriever have expanded on this method by scaling up each dataset and mannequin sizes. These newer fashions usually undertake the instruction set proposed by E5-Mistral. Nevertheless, whereas these developments characterize progress within the subject, they nonetheless primarily depend on a single instruction set and don’t totally tackle the challenges of offering customers with a extra clear and versatile search expertise.
Researchers from Johns Hopkins College and Samaya AI have launched Promptriever, a singular method to info retrieval that permits management by way of pure language prompts. This mannequin permits customers to dynamically alter relevance standards utilizing conversational descriptions, eliminating the necessity for a number of searches or advanced filters. For example, when looking for James Cameron films, customers can merely specify standards like “Related paperwork should not codirected and are created earlier than 2022.” Promptriever is constructed on a bi-encoder retriever structure, using massive language fashions comparable to LLaMA-2 7B as its spine. Whereas pre-trained language fashions can adapt to pure language directions, conventional IR coaching usually compromises this functionality by focusing solely on optimizing query-passage semantic similarity scores. Promptriever addresses this limitation, sustaining instruction-following capability post-IR coaching.
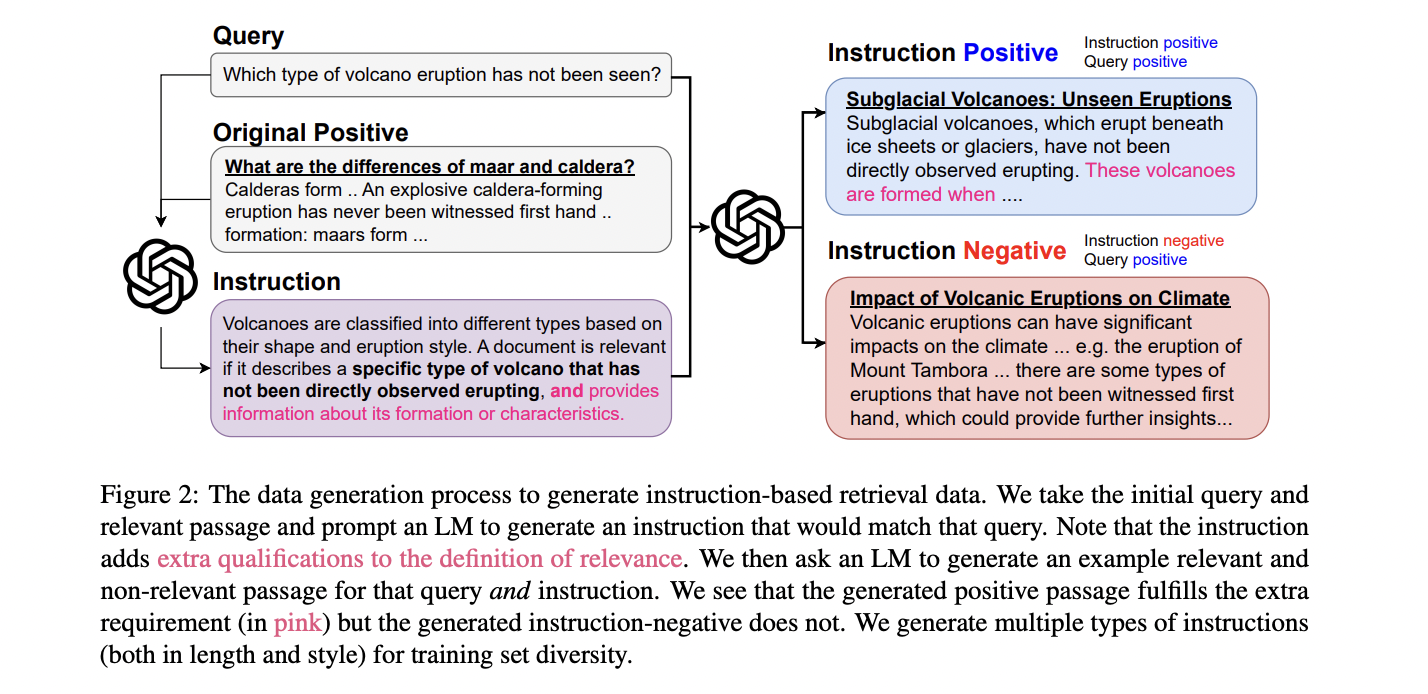
Promptriever makes use of a two-part knowledge technology course of to coach its bi-encoder for instruction-based retrieval. The mannequin builds upon the MS MARCO dataset, utilizing the tevatron-msmarco-aug model with arduous negatives. Step one entails instruction technology, the place Llama-3-70B-Instruct creates numerous, particular directions for every question, various in size and magnificence. These directions preserve relevance to the unique constructive passages, as verified by FollowIR-7B.
The second step, instruction-negative mining, introduces passages which might be query-positive however instruction-negative. This course of encourages the mannequin to contemplate each question and instruction throughout coaching. GPT-4 generates these passages, that are then filtered utilizing FollowIR-7B to make sure accuracy. Human validation confirms the effectiveness of this filtering course of, with the model-human settlement reaching 84%.
This complete knowledge augmentation method allows Promptriever to adapt its relevance standards dynamically based mostly on pure language directions, considerably enhancing its retrieval capabilities in comparison with conventional IR fashions.
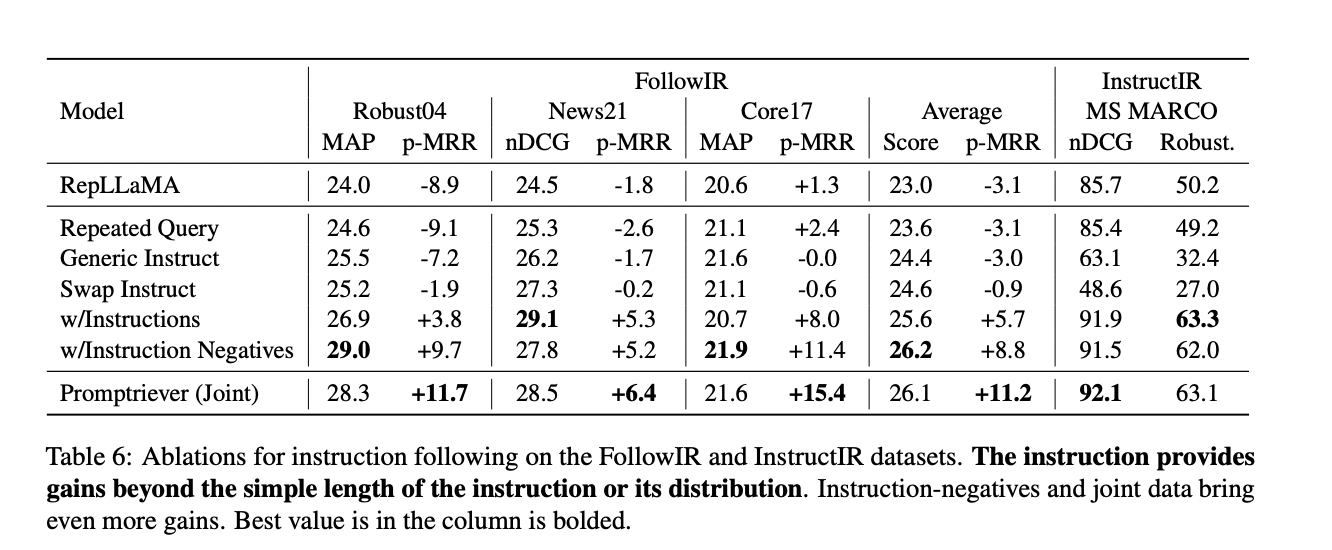
Promptriever demonstrates superior efficiency in instruction following whereas sustaining robust normal retrieval capabilities. It outperforms the unique RepLLaMA by a major margin, with enhancements of +14.3 p-MRR and +3.1 in nDCG/MAP, establishing itself because the highest-performing dense retriever. Whereas cross-encoder fashions obtain the most effective outcomes as a consequence of their computational benefit, Promptriever’s efficiency as a bi-encoder mannequin is comparable and extra environment friendly.
In normal retrieval duties with out directions, Promptriever performs on par with RepLLaMA for in-domain duties (MS MARCO) and out-of-domain duties (BEIR). Additionally, Promptriever displays 44% much less variance to prompts in comparison with RepLLaMA and 77% lower than BM25, indicating increased robustness to enter variations. These outcomes underscore the effectiveness of Promptriever’s instruction-based method in enhancing each retrieval accuracy and adaptableness to numerous queries.
This examine presents Promptriever, a major development in info retrieval, introducing the primary zero-shot promptable retriever. Developed utilizing a singular instruction-based dataset derived from MS MARCO, this mannequin demonstrates superior efficiency in each normal retrieval duties and instruction following. By adapting its relevance standards dynamically based mostly on per-query directions, Promptriever showcases the profitable software of prompting methods from language fashions to dense retrievers. This innovation paves the best way for extra versatile and user-friendly info retrieval methods, bridging the hole between pure language processing and environment friendly search capabilities.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. When you like our work, you’ll love our publication..
Don’t Overlook to hitch our 52k+ ML SubReddit
Asjad is an intern marketing consultant at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the purposes of machine studying in healthcare.


