
Massive language fashions (LLMs) have made spectacular developments in producing coherent textual content for varied actions and domains, together with grammatical error correction (GEC), textual content simplification, paraphrasing, and magnificence switch. One of many rising abilities of LLMs is their skill to generalize and carry out duties that they’ve by no means seen earlier than. To realize this, LLMs are fine-tuned on directions in an instruction-tuning course of. This reduces the necessity for few-shot exemplars because the fashions turn out to be more adept at understanding and following directions.
One of many greatest difficulties for writers is modifying their work to fulfill the necessities and limitations of their project. This may be difficult, even for skilled authors. To assist overcome this, textual content modifying benchmark duties can be utilized to fine-tune the textual content modifying capabilities of fashions. Whereas earlier research have tried to develop general-purpose textual content modifying fashions utilizing LLMs, their effectiveness, efficiency, and value are sometimes restricted by elements akin to unavailability or lack of task-specific datasets. Due to this fact, instruction tuning is crucial to enhance the general high quality of the textual content modifying course of.
Researchers from Grammarly (Vipul Raheja and Dhruv Kumar) and the College of Minnesota (Ryan Koo and Dongyeop Kang) introduce CoEdIT, an AI-based textual content modifying system designed to supply writing help with a pure language interface. CoEdIT could also be used as a writing assistant that may add, delete or change phrases, phrases, and sentences. CoEdIT meets syntactic, semantic, and stylistic edit standards with state-of-the-art efficiency on a number of textual content modifying benchmarks. The analysis group has demonstrated that CoEdIT can additional generalize to make modifications alongside a number of dimensions in a single flip, even for unseen, adjoining, and composite directions. They discover that by adhering to pure language tips, CoEdIT can assist authors with many sides of the textual content rewriting course of.
The principle contributions of the paper are as follows:
- The analysis group attained state-of-the-art efficiency on three stylistic modifying duties (paraphrasing, neutralization, and ritual type switch) along with GEC, textual content simplification, sentence fusion, and iterative textual content modifying.
- The analysis group found that, on each guide and computerized assessments, even their smallest instruction-tuned mannequin performs higher than different supervised textual content modifying, instruction-tuned, and general-purpose LLMs with roughly 60 instances as many parameters.
- Their knowledge and fashions are publicly obtainable.
- CoEdIT generalizes successfully to new, neighboring jobs not seen throughout fine-tuning, and composite directions with a number of activity descriptions.
They need to reply the next analysis inquiries:
- RQ1: Can CoEdIT comply with textual content modifying tips and supply high-quality adjustments for varied duties?
- RQ2: Can CoEdIT generalize to hold out edits for novel textual content modifying directions?
- RQ3: Does CoEdIT assist human authors write extra successfully and effectively?
First, they consider a baseline with no edits, by which the result’s only a copy of the unique enter with none adjustments. When used for duties like GEC, the place the purpose output and enter largely overlap, this methodology does slightly properly. Moreover, they consider present textual content modifying LLMs that have to be tailored utilizing instruction-specific knowledge. Specifically, they evaluate their FLAN-T5 fashions’ major options, the T52 fashions, to know the affect of task-specific fine-tuning. Moreover, they evaluate their fashions with IteraTeR and DELIteraTeR, two fashions which have demonstrated superior efficiency on varied textual content modifying duties.
Their comparisons with instruction-tuned LLMs make up a major subset:
- The first comparability they make is with PEER, which is primarily based on the T5 LM-Tailored model. They evaluate towards PEER-EDIT (3B and 11B variations) since their work goals to enhance the standard of revisions.
- The LM Tailored model of T5 serves as the start line for T0, T0++, and Tk-Instruct, that are then adjusted utilizing the PromptSource and Tremendous-NaturalInstructions datasets in that order.
- Additionally they evaluate InstructGPT, a type of GPT3 fine-tuned through reinforcement studying, on an enormous dataset of directions and human-written outputs.
- Alpaca is an instruction-tuned model of the LLaMA-7B mannequin skilled on 52000 directions following demos offered by GPT-3.4.
- GPT-3.5, usually referred to as ChatGPT, is an enhanced InstructGPT model tailor-made for dialog. They use the OpenAI API for all actions associated to inference.
- GPT-3 additionally supplies a textual content modifying API (GPT3-Edit), which is exactly analogous to the duties they prepare CoEdIT on since it could be used for modifying duties slightly than completion ones.
- Meta AI’s general-purpose language mannequin, LLaMA, was skilled solely utilizing knowledge that was made accessible to the general public. They use the 7B mannequin due to limitations in computation. Except in any other case indicated, grasping decoding was used to create the outputs of all fashions.
They make comparisons in two settings, zero-shot and few-shot, towards LLMs with out instruction tuning.
Desk 1 solutions Analysis Query 1 by evaluating CoEdIT’s efficiency with different fashions in varied textual content modifying duties. They begin by presenting the findings from probably the most well-known analysis units right here, after which in Desk 2, they offer further outcomes (i.e., subtasks and different datasets). The fashions are divided into seven classes. Whereas the second group (b) consists of instruction-fine-tuned T5-based fashions on non-text-editing duties, the primary group (a) consists of the copy baseline and T5-Massive baseline fine-tuned utilizing prefix-tuning (every knowledge level is prefixed with task-specific tags slightly than directions). They found that CoEdIT performs considerably higher on all duties than these fashions. The next two units (c, d) show a number of LLMs that have been assessed in a zero-shot situation and that vary in measurement from 7 billion to 175 billion parameters. Group (d) fashions are instruction-tuned, whereas group (c) fashions are decoder-only.
They found that CoEdIT performs higher on a lot of the duties than fashions that have been many instances larger, akin to ChatGPT and InstructGPT, and higher than all LLMs much like its mannequin measurement (like Alpaca and LLaMA). This implies that slightly than scaling mannequin measurement, it could be higher to densify the duty/instruction house as a result of the present general-purpose and instruction-tuned fashions are underfitted. Whereas Alpaca and T5-based fashions (Tk-Instruct, T0, T0++) have demonstrated nice efficiency previously on zero-shot duties, these fashions carry out much less properly than CoEdIT. Moreover, they observe that for tougher duties, akin to these falling throughout the Type intent class, the decoder-only fashions (like GPT-3 and LLaMA) continuously repeat the enter.
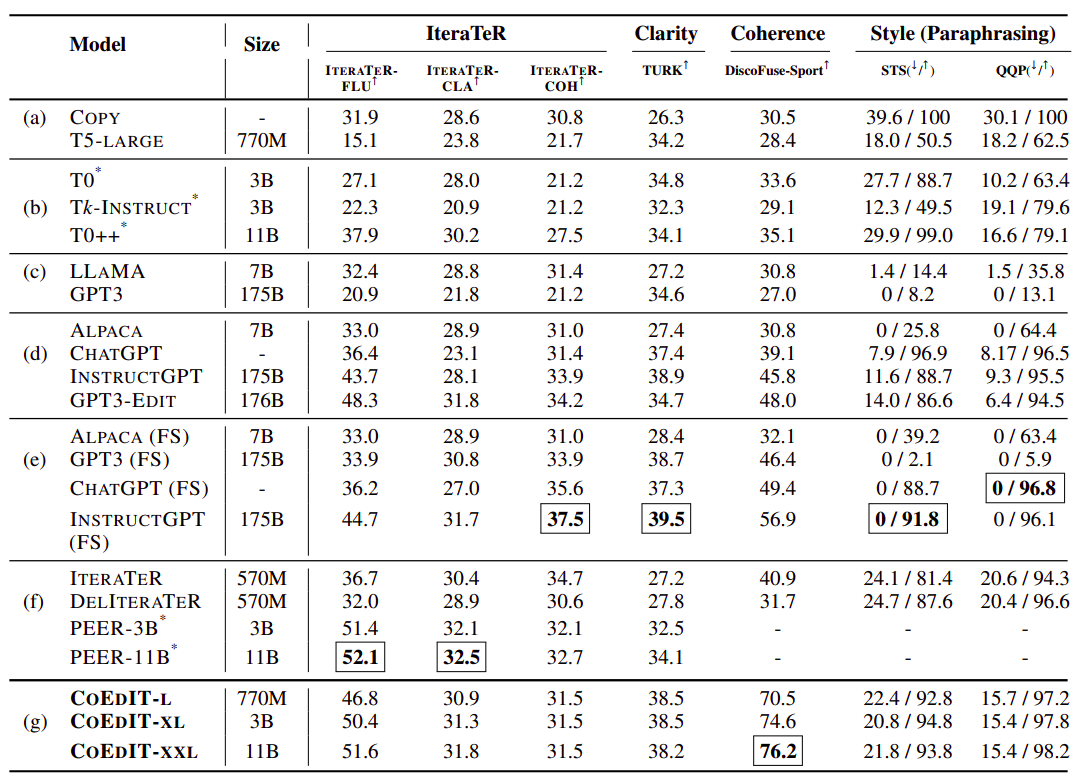
It’s because the fashions both repeated the enter sentence or produced a continuation that had nothing to do with the duty, which can be defined by their lack of ability to grasp the requested activity. Subsequently, in group (e), they assess the LLMs in a few-shot configuration. They conduct these experiments in a 4-shot analysis setup. Instance inputs have been created by randomly choosing 4 inputs from the CoEdIT dataset for every job, making certain each instance set would match contained in the enter window for each mannequin. The instructive immediate has the enter sentence prepended to it, together with its matching up to date reference. They do few-shot evaluations of three instruction-tuned LLMs (InstructGPT, ChatGPT, and Alpaca) and decoder-only LLMs (GPT-3).
They be aware that, besides MRPC for GPT-3, offering specific examples enhances efficiency in all fashions for all duties. This is likely to be the case as a result of GPT-3 repeats its generations equally, resulting in low semantic similarity and a poor BLEU rating. Since scores have a tendency to stay constant throughout duties, they don’t supply any outcomes for GPT3-Edit within the few-shot scenario, which means that GPT3-Edit’s in-context studying abilities may have to be stronger. Total, they uncover that for many duties, even their smallest, 770 million parameter mannequin can compete with LLMs evaluated in a few-shot scenario.
The analysis group contrasts their fashions with task-specific textual content modifying fashions like IteraTeR, DELIteraTeR, and PEER within the final group (f). As a result of IteraTeR and DELIteraTeR solely prepended directions to the inputs and have been skilled with task-specific tags, their efficiency is considerably poorer than the scores within the unique analysis. Furthermore, they weren’t ready to comply with directions; as an alternative, they have been skilled utilizing BART and Pegasus, which have separate pre-training goals associated to summarization. CoEdIT outperforms PEER on common in all documented evaluations besides the IteraTeR benchmark. Since PEER makes use of Wikipedia because the supply of tutorial edit knowledge, that is largely as a result of distinction in task-specific fine-tuning.
Whereas CoEdIT attains cutting-edge outcomes on a number of textual content modifying benchmarks, it possesses sure constraints with its methodology and evaluation methods. Like most earlier efforts, task-specific fine-tuning primarily targets sentence-level modifying assignments. Its efficacy on for much longer textual content sequences extra suited to real-world modifying situations has but to be decided. Moreover, the first focus of their system is on non-meaning-altering textual content alterations.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to comply with us on Twitter. Be part of our 36k+ ML SubReddit, 41k+ Fb Group, Discord Channel, and LinkedIn Group.
If you happen to like our work, you’ll love our publication..
Don’t Neglect to affix our Telegram Channel
Because of the Grammarly Analysis Crew for the thought management/ Academic article. The Grammarly Analysis Crew has supported us on this content material/article
Good day, My title is Adnan Hassan. I’m a consulting intern at Marktechpost and shortly to be a administration trainee at American Specific. I’m at present pursuing a twin diploma on the Indian Institute of Expertise, Kharagpur. I’m enthusiastic about expertise and need to create new merchandise that make a distinction.

