
Signal language analysis goals to advance expertise that improves the understanding, translation, and interpretation of signal languages utilized by Deaf and hard-of-hearing communities globally. This subject includes creating in depth datasets, growing subtle machine-learning fashions, and enhancing instruments for translation and identification in varied purposes. By bridging communication gaps, this analysis helps higher inclusion and accessibility for people who depend on signal language for day by day communication.
A major problem on this subject is extra information for a lot of signal languages. Not like spoken languages, signal languages lack a standardized written kind, complicating information assortment and processing. This information bottleneck restricts the event of efficient translation and interpretation instruments, notably for lesser-studied signal languages. The shortage of considerable datasets hinders the progress of machine studying fashions tailor-made to those distinctive visuospatial languages.
Current strategies for processing signal languages embrace specialised datasets like YouTube-ASL for American Signal Language (ASL) and BOBSL for British Signal Language (BSL). Whereas these datasets symbolize important strides, they’re typically restricted to particular person languages and contain labor-intensive guide annotation processes. Automated content-based annotations and expert human filtering are frequent practices, but these strategies should be extra simply scalable to accommodate the huge variety of signal languages worldwide.
Google and Google DeepMind researchers launched YouTube-SL-25, a complete, open-domain multilingual corpus of signal language movies. This dataset is the most important and most numerous of its variety, comprising over 3,000 hours of video content material and that includes over 3,000 distinctive signers throughout 25 signal languages. By offering well-aligned captions, YouTube-SL-25 considerably expands the assets for signal language translation and identification duties.
The creation of YouTube-SL-25 concerned a meticulous two-step course of. First, automated classifiers recognized potential signal language movies from YouTube. Not like earlier datasets that required in depth guide evaluation, this step was adopted by a triage course of the place researchers audited and prioritized movies based mostly on content material high quality and alignment. This method enabled the environment friendly assortment of 81,623 candidate movies, then refined to 39,197 high-quality movies totaling 3,207 hours of content material. This dataset contains well-aligned captions overlaying 2.16 million captions with 104 million characters, setting a brand new customary for signal language datasets.
The dataset’s utility was demonstrated by benchmarks utilizing a unified multilingual multitask mannequin based mostly on T5. The researchers prolonged this mannequin to assist a number of supply and goal languages, enhancing its signal language identification and translation functionality. The outcomes confirmed substantial advantages from multilingual switch, with notable enhancements in high-resource and low-resource signal languages. As an illustration, the mannequin’s efficiency on benchmarks for ASL, Swiss German Signal Language, Swiss-French Signal Language, and Swiss Italian Signal Language demonstrated important developments, with BLEURT scores of 40.1 for ASL and 37.7 for Swiss German Signal Language.
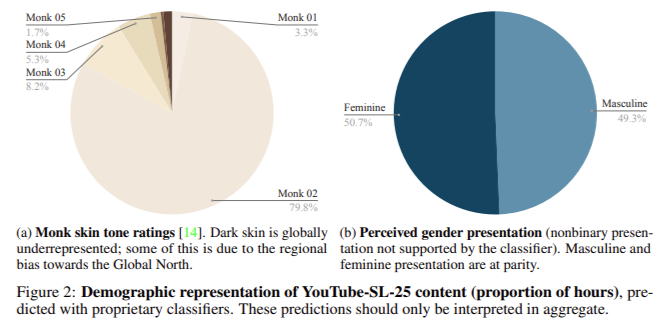
The researchers supplied detailed statistics to guage YouTube-SL-25’s efficiency. The dataset consists of three,207 hours of video content material throughout greater than 25 signal languages, greater than thrice bigger than YouTube-ASL, which had 984 hours. This scale permits for a extra complete illustration of signal languages, together with these with not less than 15 hours of content material, guaranteeing even low-resource languages are higher supported. Together with 3,072 distinctive channels highlights this dataset’s variety of signers and contexts.
YouTube-SL-25 considerably impacts, providing a foundational useful resource for growing signal language applied sciences. This dataset addresses important gaps in multilingual signal language information availability by enabling higher pretraining for sign-to-text translation fashions and enhancing signal language identification duties. The dataset’s open-domain nature permits for broad purposes, from normal signal language pretraining to medium-quality finetuning for particular duties corresponding to translation and caption alignment.

In conclusion, YouTube-SL-25 is a pivotal development in signal language analysis, addressing the longstanding information shortage subject. With its in depth and numerous assortment of signal language movies, the dataset facilitates the event of more practical translation and interpretation instruments. This useful resource helps higher-quality machine studying fashions and fosters higher inclusivity for Deaf and hard-of-hearing communities worldwide, guaranteeing that expertise continues to advance towards broader accessibility and understanding.
Try the Paper and GitHub. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to observe us on Twitter.
Be a part of our Telegram Channel and LinkedIn Group.
In the event you like our work, you’ll love our publication..
Don’t Neglect to hitch our 46k+ ML SubReddit
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.


