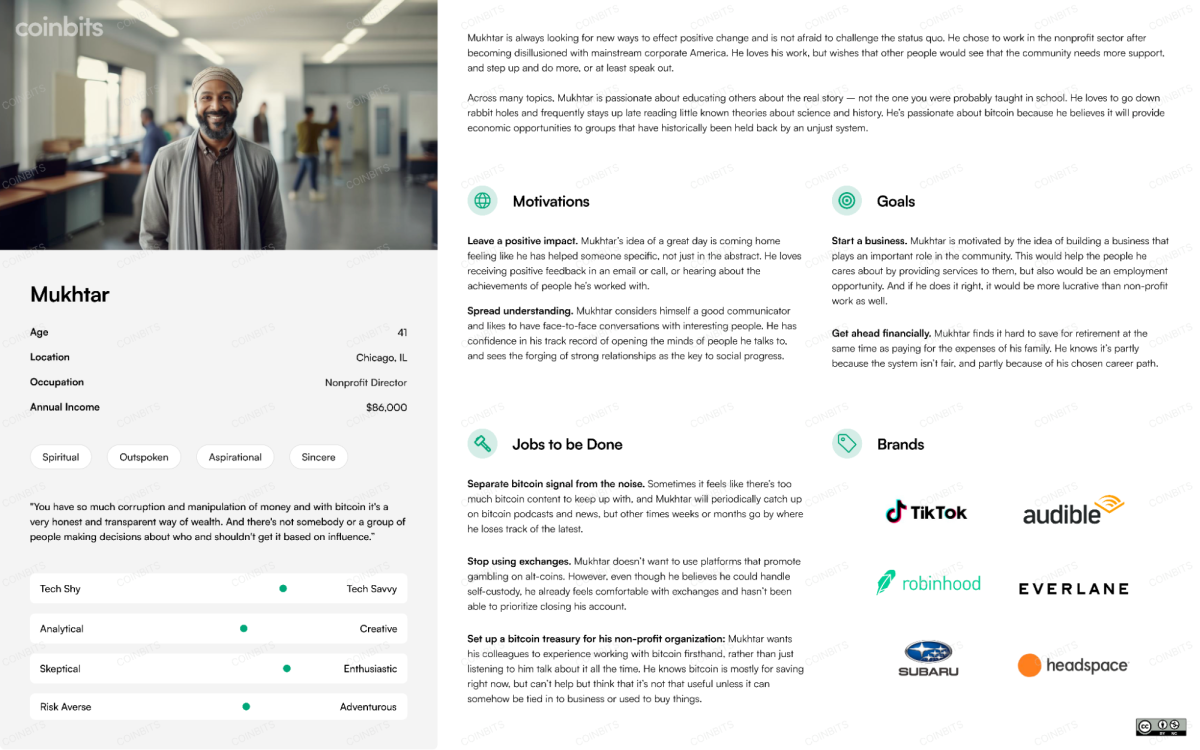
Important points come up when programming data and job assistants based mostly on Giant Language Fashions (LLMs) rigorously comply with developer-provided insurance policies. To fulfill the requests and calls for of customers, these brokers should reliably retrieve and supply correct and pertinent data. Nevertheless, a typical drawback with these brokers is that they have a tendency to reply in an unjustified method, a phenomenon known as hallucination.
The time period hallucination describes the method by which data is produced that isn’t grounded in the true information or data that the mannequin has been skilled on. These solutions might be wholly made up, unfaithful, or misleading, but the mannequin continuously presents them with assurance and makes them appear affordable.
Whereas they supply a way of managing conversations, conventional dialogue bushes are solely in a position to accommodate a restricted set of pre-established dialog flows. They’re, subsequently, intrinsically inflexible and unable to regulate to the huge vary of potential person interactions due to this restriction.
To deal with these points, Stanford researchers have launched KITA, a programmable framework for constructing task-oriented conversational brokers that may handle intricate person interactions. In distinction to LLMs, KITA is designed to provide builders management over agent conduct by way of its expressive specification, the KITA Worksheet, whereas nonetheless producing reliable and grounded responses. In comparison with typical dialogue bushes, this worksheet provides a extra versatile and dependable technique by enabling declarative coverage programming.
A few of the most important options of KITA are as follows.
- Resilience to Various Queries: KITA is extra versatile and resilient in real-world conditions as a result of, in distinction to dialogue bushes, it could deal with a broad vary of person queries.
- Integration with Data Sources: KITA efficiently combines a spread of data sources to ship exact and well-informed solutions.
- Programming insurance policies is made simpler by the declarative paradigm of the KITA Worksheet, which allows builders to assemble and handle difficult relationships with larger ease.
The workforce has shared that KITA was proven to achieve success in a real-user trial with sixty-two folks. The outcomes demonstrated that KITA carried out considerably higher than the GPT-4 with a function-calling baseline.
- Execution Accuracy: KITA noticed a 26.1-point enchancment.
- Dialogue Act Accuracy: KITA skilled a 22.5-point enchancment.
- Purpose Completion Price: KITA noticed a rise of 52.4 factors.
The workforce has summarized their major contributions as follows.
- KITA, which is an open-domain built-in job and data assistant that complies with insurance policies provided by high-level builders, has been introduced. It gives full compositionality of duties and data queries, and grounds replies in hybrid data sources.
- KITA Worksheet has additionally been proposed as a novel specification for task-oriented dialogue (TOD) brokers. With the assistance of this specification, KITA will have the ability to monitor the standing of discussions and provides the LLM step-by-step directions, guaranteeing exact and contextually applicable interactions.
- The 62-person real-user experiments have proven that KITA is efficient, with 91.5% execution accuracy, 91.6% dialogue act accuracy, and 74.2% goal completion charge. These findings reveal that KITA considerably outperforms the GPT-4 function-calling baseline. A dataset of 180 dialogue turns from 22 precise person chats has additionally been made accessible. It has been manually adjusted for accuracy.
In conclusion, KITA gives a steady, adaptable, and developer-friendly framework for producing dialogue brokers which might be targeted on duties. It surpasses the drawbacks of typical dialogue bushes and LLMs by providing appropriate, well-founded responses and facilitating easy, environment friendly coverage programming with its distinctive KITA Worksheet.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to comply with us on Twitter.
Be part of our Telegram Channel and LinkedIn Group.
If you happen to like our work, you’ll love our e-newsletter..
Don’t Neglect to affix our 46k+ ML SubReddit
Tanya Malhotra is a ultimate yr undergrad from the College of Petroleum & Vitality Research, Dehradun, pursuing BTech in Laptop Science Engineering with a specialization in Synthetic Intelligence and Machine Studying.
She is a Knowledge Science fanatic with good analytical and important pondering, together with an ardent curiosity in buying new abilities, main teams, and managing work in an organized method.