
A essential problem in Synthetic intelligence, particularly relating to massive language fashions (LLMs), is balancing mannequin efficiency and sensible constraints like privateness, price, and system compatibility. Whereas massive cloud-based fashions supply excessive accuracy, their reliance on fixed web connectivity, potential privateness breaches, and excessive prices pose limitations. Furthermore, deploying these fashions on edge units introduces challenges in sustaining low latency and excessive accuracy attributable to {hardware} limitations.
Current work consists of fashions like Gemma-2B, Gemma-7B, and Llama-7B, in addition to frameworks corresponding to Llama cpp and MLC LLM, which purpose to reinforce AI effectivity and accessibility. Initiatives like NexusRaven, Toolformer, and ToolAlpaca have superior function-calling in AI, striving for GPT-4-like efficacy. Methods like LoRA have facilitated fine-tuning underneath GPU constraints. Nonetheless, these efforts usually should grapple with an important limitation: attaining a steadiness between mannequin measurement and operational effectivity, significantly for low-latency, high-accuracy purposes on constrained units.
Researchers from Stanford College have launched Octopus v2, a sophisticated on-device language mannequin aimed toward addressing the prevalent problems with latency, accuracy, and privateness considerations related to present LLM purposes. Not like earlier fashions, Octopus v2 considerably reduces latency and enhances accuracy for on-device purposes. Its uniqueness lies within the fine-tuning methodology with useful tokens, enabling exact operate calling and surpassing GPT-4 in effectivity and velocity whereas dramatically slicing the context size by 95%.
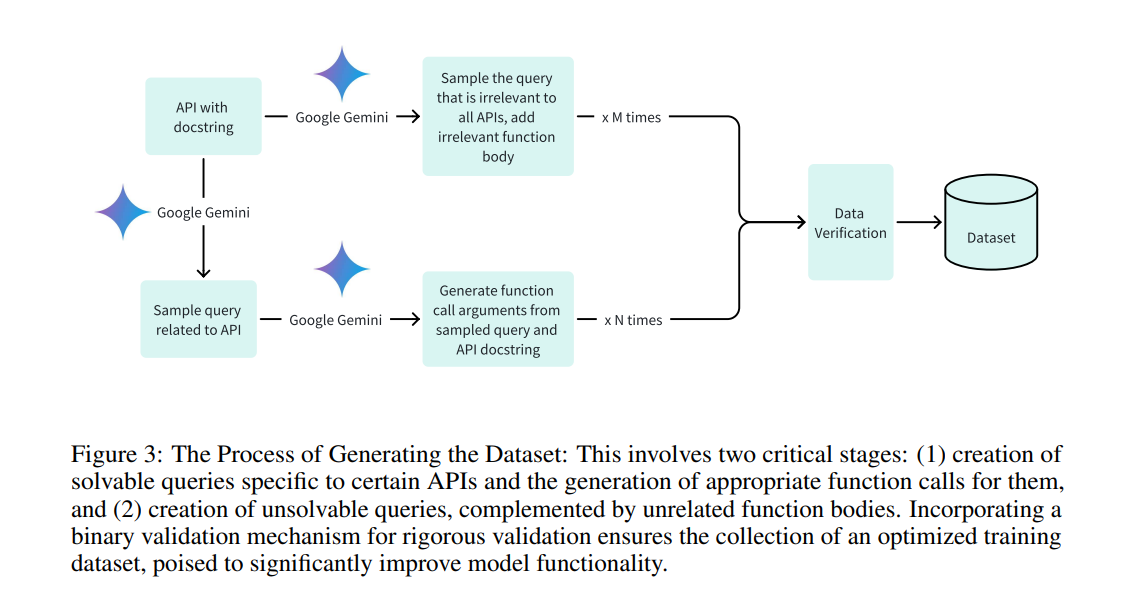
The methodology for Octopus v2 concerned fine-tuning a 2 billion parameter mannequin derived from Google DeepMind’s Gemma 2B on a tailor-made dataset specializing in Android API calls. This dataset was constructed with constructive and adverse examples to reinforce operate calling precision. The coaching included full mannequin and Low-Rank Adaptation (LoRA) methods to optimize efficiency for on-device execution. The important thing innovation was the introduction of useful tokens throughout fine-tuning, considerably decreasing latency and context size necessities. This course of allowed Octopus v2 to realize excessive accuracy and effectivity in operate calling on edge units with out in depth computational assets.
In benchmark exams, Octopus v2 achieved a 99.524% accuracy price in function-calling duties, markedly outperforming GPT-4. The mannequin additionally confirmed a dramatic discount in response time, with latency minimized to 0.38 seconds per name, representing a 35-fold enchancment in comparison with earlier fashions. Moreover, it required 95% much less context size for processing, showcasing its effectivity in dealing with on-device operations. These metrics underline Octopus v2’s developments in decreasing operational calls for whereas sustaining high-performance ranges, positioning it as a big development in on-device language mannequin expertise.
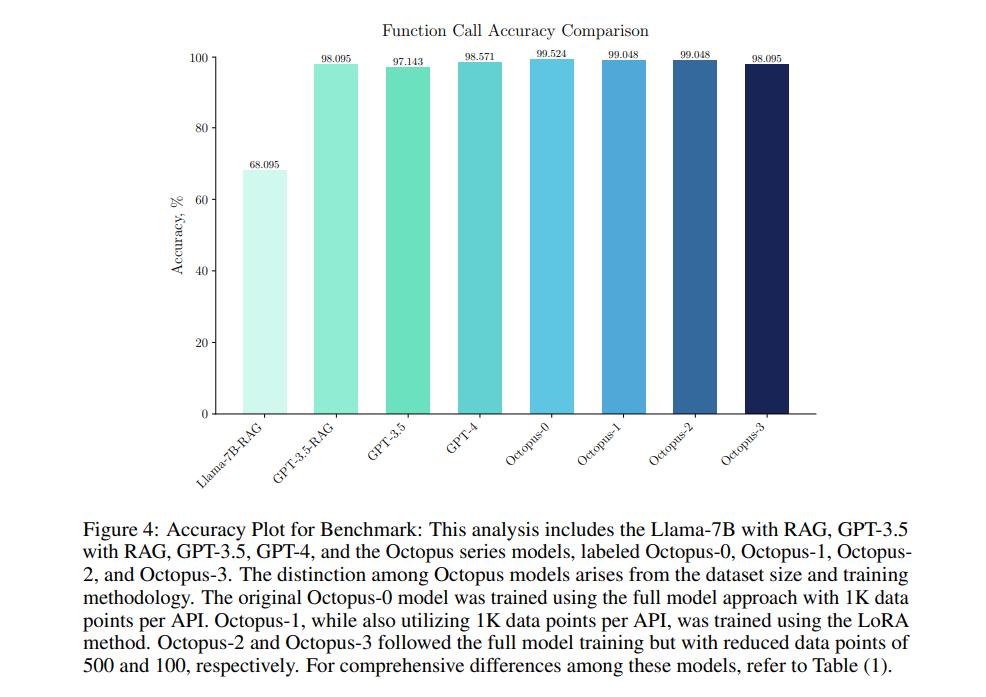
To conclude, Stanford College researchers have demonstrated that the event of Octopus v2 marks a big leap ahead in on-device language modeling. By attaining a excessive operate calling accuracy of 99.524% and decreasing latency to simply 0.38 seconds, Octopus v2 addresses key challenges in on-device AI efficiency. Its revolutionary fine-tuning method with useful tokens drastically reduces context size, enhancing operational effectivity. This analysis showcases the mannequin’s technical deserves and potential for broad real-world purposes.
Try the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to observe us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
If you happen to like our work, you’ll love our publication..
Don’t Neglect to affix our 39k+ ML SubReddit
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching purposes in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


