
The fast evolution in AI calls for fashions that may deal with large-scale knowledge and ship correct, actionable insights. Researchers on this area goal to create techniques able to steady studying and adaptation, guaranteeing they continue to be related in dynamic environments.
A big problem in creating AI fashions lies in overcoming the problem of catastrophic forgetting, the place fashions fail to retain beforehand acquired data when studying new duties. This problem turns into extra urgent as functions more and more demand steady studying capabilities. For example, fashions should replace their understanding of healthcare, monetary evaluation, and autonomous techniques whereas retaining prior data to make knowledgeable selections. The first downside is designing fashions that may effectively study new data with out compromising on beforehand acquired insights.
Current analysis consists of Elastic Weight Consolidation (EWC), which prevents catastrophic forgetting by penalizing essential weight adjustments, and replay-based strategies like Expertise Replay, which reinforces prior data by replaying previous experiences. Modular neural community architectures, like Progressive Neural Networks, add sub-networks for brand new duties, whereas meta-learning approaches, comparable to Mannequin-Agnostic Meta-Studying (MAML), permit fashions to adapt to new duties with minimal knowledge rapidly. Every method has distinctive trade-offs in complexity, effectivity, and flexibility.
Researchers from NVIDIA and MIT have launched a novel visible language mannequin (VLM) pre-training framework, VILA, which emphasizes efficient embedding alignment and makes use of dynamic neural community architectures. This analysis differs by leveraging a mixture of interleaved corpora and joint supervised fine-tuning (SFT) to reinforce visible and textual studying capabilities. The VILA framework is distinct for its emphasis on preserving in-context studying skills whereas bettering generalization, guaranteeing that fashions retain the power to deal with complicated duties effectively.
To enhance visible and textual alignment, the methodology concerned pre-training VILA on large-scale datasets, comparable to Coyo-700m. Researchers used a base LLaVA mannequin to check totally different pre-training methods, evaluating freezing and updating the big language mannequin (LLM) throughout coaching. They launched Visible Instruction Tuning to fine-tune the fashions utilizing visible language datasets with prompt-based instruction tuning. The analysis course of included testing the pre-trained fashions on benchmarks like OKVQA and TextVQA to evaluate visible question-answering capabilities, particularly measuring VILA’s accuracy and context-learning means.
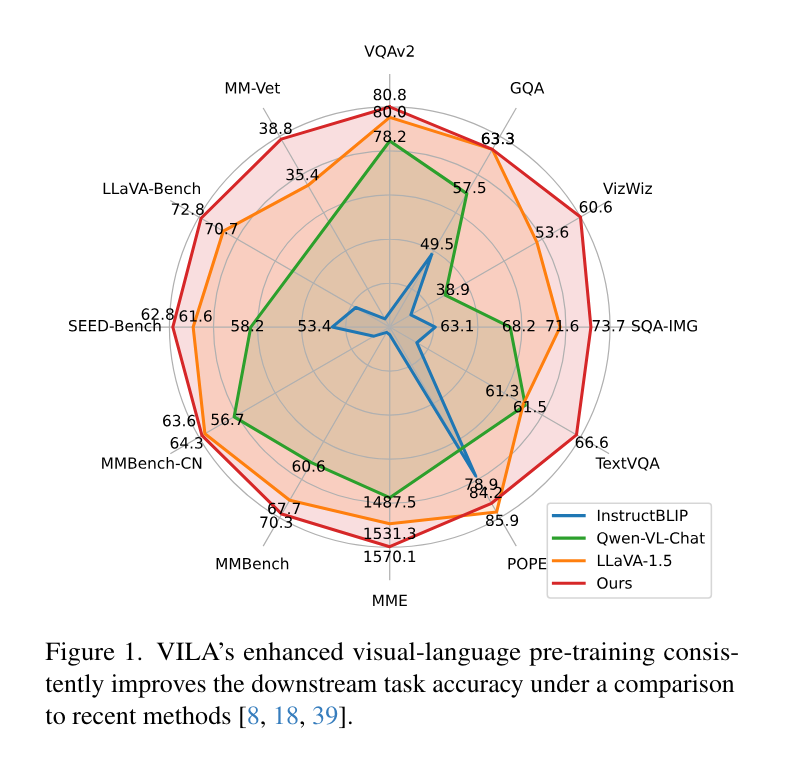
VILA demonstrated vital ends in bettering the efficiency of VLMs. It confirmed vital accuracy beneficial properties, attaining a mean of 70.7% on OKVQA and 78.2% on TextVQA, outperforming present benchmarks by noticeable margins. Moreover, VILA retained as much as 90% of beforehand discovered data when studying new duties. This end result signifies a discount in catastrophic forgetting, displaying that VILA might adapt to new visible language duties whereas sustaining prior data.
To conclude, the analysis introduced a novel framework for pre-training VLMs, emphasizing embedding alignment and environment friendly process studying. By using revolutionary methods like Visible Instruction Tuning and leveraging large-scale datasets, VILA demonstrated improved accuracy in visible question-answering duties. The analysis highlighted the significance of balancing new studying with prior data retention, decreasing catastrophic forgetting. This method contributes considerably to advancing VLMs, enabling simpler and adaptable AI techniques for various real-world functions.
Try the Paper and GitHub. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to comply with us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
In the event you like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our 41k+ ML SubReddit
Nikhil is an intern marketing consultant at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching functions in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


