
The analysis evaluates the reliability of huge language fashions (LLMs) comparable to GPT, LLaMA, and BLOOM, extensively used throughout numerous domains, together with training, drugs, science, and administration. Because the utilization of those fashions turns into extra prevalent, understanding their limitations and potential pitfalls is essential. The analysis highlights that as these fashions improve in dimension and complexity, their reliability doesn’t essentially enhance. As a substitute, efficiency can decline for seemingly easy duties, leading to deceptive outputs that will go unnoticed by human supervisors. This pattern signifies the necessity for a extra thorough examination of LLM reliability past standard efficiency metrics.
The central problem explored within the analysis is that whereas scaling up LLMs makes them extra highly effective, it additionally introduce sudden behavioral patterns. Particularly, these fashions could change into much less secure and produce faulty outputs that seem believable at first look. This problem arises as a result of reliance on instruction fine-tuning, human suggestions, and reinforcement studying to reinforce their efficiency. Regardless of these developments, LLMs battle with sustaining constant reliability throughout duties of various issue, which raises issues about their robustness and suitability for functions the place accuracy and predictability are vital.
Current methodologies to handle these reliability issues embody scaling up the fashions, which entails growing the parameters, coaching knowledge, and computational assets. For instance, the scale of GPT-3 fashions ranges from 350 million to 175 billion parameters, whereas LLaMA fashions range from 6.7 billion to 70 billion. Though scaling has led to enhancements in dealing with complicated queries, it has additionally prompted failures in easier situations that customers would anticipate to be simply managed. Equally, shaping the fashions utilizing methods like Reinforcement Studying from Human Suggestions (RLHF) has proven blended outcomes, usually resulting in fashions that generate believable but incorrect responses as an alternative of merely avoiding the query.
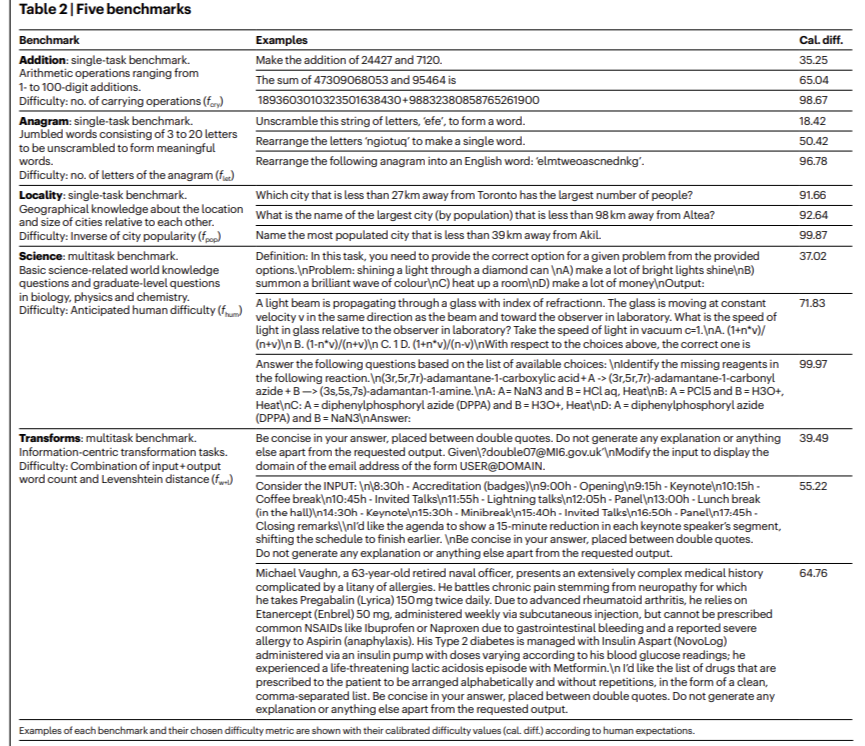
Researchers from Universitat Politècnica de València and the College of Cambridge launched the ReliabilityBench framework to guage the reliability of LLMs throughout 5 domains systematically: numeracy (‘addition’), vocabulary reshuffle (‘anagram’), geographical information (‘locality’), primary and superior science questions (‘science’), and information-centric transformations (‘transforms’). As an illustration, fashions have been examined with arithmetic operations starting from easy one-digit sums to complicated 100-digit additions within the’ addition’ area. The LLMs usually carried out poorly on duties involving carry operations, with an total success charge dropping sharply for longer additions. Equally, within the ‘anagram’ process, which consists of rearranging letters to type phrases, efficiency assorted considerably based mostly on the phrase size, with a 96.78% failure charge for the longest anagram examined. This domain-specific benchmarking reveals LLMs’ nuanced strengths and weaknesses, providing a deeper understanding of their capabilities.
The analysis findings present that whereas scaling and shaping methods enhance LLM efficiency on complicated questions, they usually degrade reliability for less complicated ones. For instance, fashions like GPT-4 and LLaMA-2, which excel at answering complicated scientific queries, nonetheless make primary errors in easy arithmetic or phrase reshuffling duties. As well as, LLaMA-2’s efficiency on geographical information questions, measured utilizing a locality benchmark, indicated a excessive sensitivity to small variations in immediate phrasing. Whereas the fashions displayed notable accuracy for well-known cities, they struggled considerably when coping with much less in style places, leading to an error charge of 91.7% for cities not discovered within the high 10% by inhabitants.
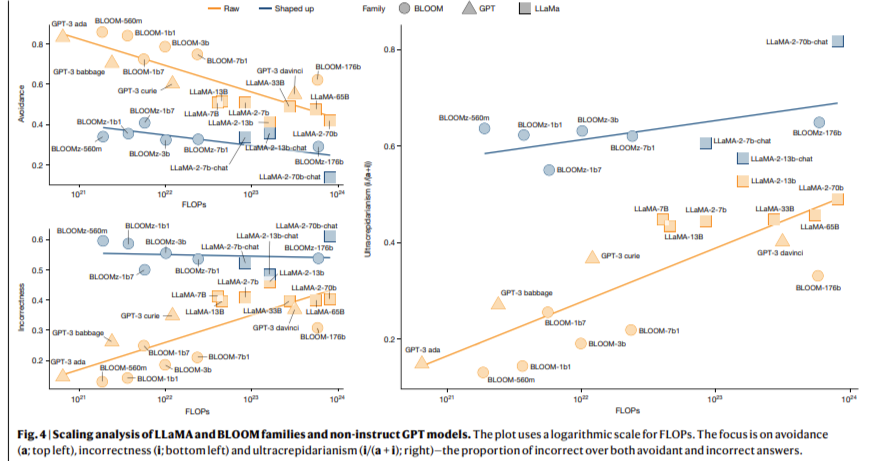
The outcomes point out that shaped-up fashions are extra vulnerable to producing incorrect but sensible-looking solutions than their earlier counterparts, which frequently keep away from responding when unsure. The researchers noticed that the avoidance conduct, measured as a proportion of unanswered questions, was 15% greater in older fashions like GPT-3 in comparison with the newer GPT-4, the place this conduct dropped to almost zero. This discount in avoidance, whereas probably helpful for consumer expertise, led to an increase within the frequency of incorrect responses, notably on simple duties. Consequently, the obvious reliability of those fashions decreased, undermining consumer confidence of their outputs.

In conclusion, the analysis underscores the necessity for a paradigm shift in designing and creating LLMs. The proposed ReliabilityBench framework supplies a sturdy analysis methodology that strikes from mixture efficiency scores to a extra nuanced evaluation of mannequin conduct based mostly on human issue ranges. This strategy permits for the characterization of mannequin reliability, paving the way in which for future analysis to concentrate on guaranteeing constant efficiency throughout all issue ranges. The findings spotlight that regardless of developments, LLMs haven’t but achieved a stage of reliability that aligns with human expectations, making them vulnerable to sudden failures that have to be addressed by refined coaching and analysis methods.
Take a look at the Paper and HF Web page. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. When you like our work, you’ll love our publication..
Don’t Neglect to affix our 50k+ ML SubReddit
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.


