
Synthetic intelligence (AI) and machine studying (ML) revolve round constructing fashions able to studying from information to carry out duties like language processing, picture recognition, and making predictions. A major facet of AI analysis focuses on neural networks, notably transformers. These fashions use consideration mechanisms to course of information sequences extra successfully. By permitting the mannequin to deal with probably the most related components of the information, transformers can carry out advanced duties that require understanding and prediction throughout varied domains.
One main challenge in AI mannequin growth is knowing how inside elements, reminiscent of consideration heads in transformers, evolve and specialize throughout coaching. Whereas the general efficiency of those fashions has improved, researchers nonetheless battle to know how totally different elements contribute to the mannequin’s operate. Refining mannequin habits or enhancing interpretability stays tough with out detailed insights into these processes, resulting in challenges in optimizing mannequin effectivity and transparency. This limits progress in mannequin enchancment and hinders the power to elucidate how choices are made.
A number of instruments have been developed to review how neural networks function. These embody strategies like ablation research, the place particular mannequin elements are disabled to look at their function, and clustering algorithms, which group related elements based mostly on their habits. Whereas these strategies have proven that focus heads concentrate on token prediction and syntax processing duties, they usually present static snapshots of the mannequin on the finish of coaching. Such approaches want perception into how the inner constructions of fashions evolve dynamically all through the educational course of. They fail to seize the gradual adjustments as these fashions transition from fundamental to advanced features.
Researchers from the College of Melbourne and Timaeus have launched the refined Native Studying Coefficient (rLLC). This new methodology offers a quantitative measure of mannequin complexity by analyzing the event of inside elements like consideration heads. By specializing in the refined LLCs, the researchers provide a extra detailed understanding of how totally different elements inside transformers specialize and differentiate over time. Their method permits for monitoring the evolutionary adjustments of consideration heads all through the coaching course of, offering clearer insights into their practical roles. This technique helps observe the progressive differentiation of consideration heads, revealing how they transfer from a uniform state firstly of coaching to distinct roles as studying continues.
The rLLC examines how consideration heads reply to information constructions and the geometry of the loss panorama. Throughout coaching, neural networks regulate their weights based mostly on how effectively they reduce prediction errors (loss). The rLLC captures this adjustment by quantifying how totally different heads specialize based mostly on their interplay with particular information constructions, reminiscent of bigrams or advanced patterns like induction or bracket matching. The researchers used a two-layer attention-only transformer for his or her experiments, specializing in how the heads in these layers developed. Early in coaching, consideration heads had been noticed to deal with easier duties, reminiscent of processing particular person tokens or smaller phrase teams (bigrams). As coaching progressed, heads diverged into extra specialised roles, specializing in advanced duties like dealing with multigrams, which contain predicting token sequences that aren’t essentially contiguous.
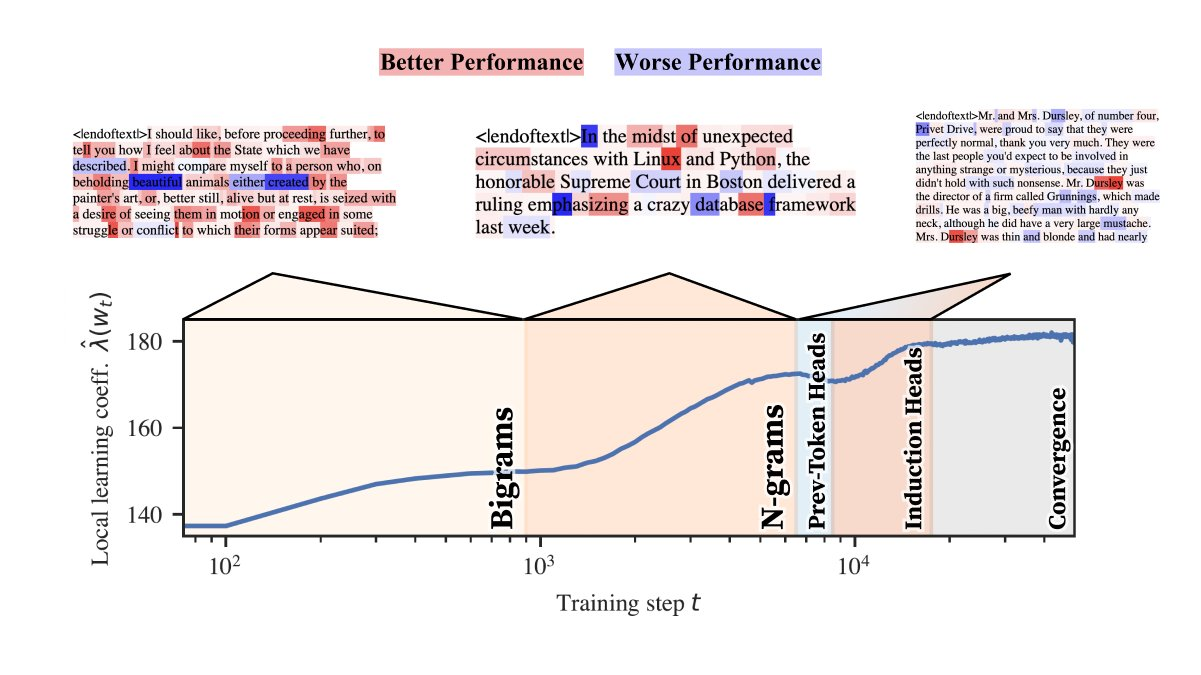
The analysis demonstrated a number of key findings. First, consideration heads specialised in distinct phases. Throughout the early levels of coaching, the heads realized to course of easy information constructions like bigrams. Over time, some heads transitioned to concentrate on extra advanced duties, reminiscent of dealing with skip n-grams (multigrams), sequences that span a number of tokens with gaps. The research discovered that sure heads, labeled induction heads, performed essential roles in recognizing recurring patterns, reminiscent of these seen in code and pure language processing duties. These heads contributed to the mannequin’s potential to foretell repeated syntactic constructions successfully. By monitoring the rLLC over time, the researchers might observe the levels of those transitions. For instance, the event of multigram prediction circuits was recognized as a key element, with heads from layer 1 within the transformer mannequin exhibiting elevated specialization towards the top of the coaching course of.
Along with revealing the specialization of consideration heads, the research found a beforehand unknown multigram circuit. This circuit is crucial for managing advanced token sequences and entails coordination between totally different consideration heads, particularly in layer 1. The multigram circuit demonstrates how totally different heads, initially tasked with processing easy sequences, evolve to deal with extra intricate patterns via their coordination. The analysis additionally highlighted that heads with decrease LLC values tended to depend on easy algorithms like induction, whereas these with increased values memorized extra advanced patterns. Refined LLCs enable for figuring out practical roles with out counting on guide or mechanistic interpretability strategies, making the method extra environment friendly and scalable.
Total, this research contributes important developments in understanding the developmental means of transformers. By introducing the refined LLC, researchers provide a strong instrument to investigate how totally different elements in a neural community specialize all through the educational course of. This developmental interpretability method bridges the hole between understanding information distribution constructions, mannequin geometry, studying dynamics, and computational specialization. The findings pave the best way for improved interpretability in transformer fashions, providing new alternatives to boost their design and effectivity in real-world purposes.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. When you like our work, you’ll love our e-newsletter.. Don’t Overlook to affix our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Finest Platform for Serving Wonderful-Tuned Fashions: Predibase Inference Engine (Promoted)
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching purposes in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


