
Initially designed for steady management duties, Proximal Coverage Optimization (PPO) has turn out to be extensively utilized in reinforcement studying (RL) purposes, together with fine-tuning generative fashions. Nonetheless, PPO’s effectiveness depends on a number of heuristics for secure convergence, corresponding to worth networks and clipping, making its implementation delicate and sophisticated. Regardless of this, RL demonstrates exceptional versatility, transitioning from duties like steady management to fine-tuning generative fashions. But, adapting PPO, initially meant to optimize two-layer networks, to fine-tune fashionable generative fashions with billions of parameters raises considerations. This necessitates storing a number of fashions in reminiscence concurrently and raises questions concerning the suitability of PPO for such duties. Additionally, PPO’s efficiency varies extensively on account of seemingly trivial implementation particulars. This raises the query: Are there easier algorithms that scale to fashionable RL purposes?
Coverage Gradient (PG) strategies, famend for his or her direct, gradient-based coverage optimization, are pivotal in RL. Divided into two households, PG strategies based mostly on REINFORCE typically incorporate variance discount strategies, whereas adaptive PG strategies precondition coverage gradients to make sure stability and sooner convergence. Nonetheless, computing and inverting the Fisher Data Matrix in adaptive PG strategies like TRPO pose computational challenges, resulting in coarse approximations like PPO.
Researchers from Cornell, Princeton, and Carnegie Mellon College introduce REBEL: REgression to RElative REward Based mostly RL. This algorithm reduces the issue of coverage optimization by regressing the relative rewards through direct coverage parameterization between two completions to a immediate, enabling strikingly light-weight implementation. Theoretical evaluation reveals REBEL as a basis for RL algorithms like Pure Coverage Gradient, matching prime theoretical ensures for convergence and pattern effectivity. REBEL accommodates offline information and addresses intransitive preferences which can be frequent in observe.
The researchers undertake the Contextual Bandit formulation for RL, which is especially related for fashions like LLMs and Diffusion Fashions on account of deterministic transitions. Immediate-response pairs are thought-about with a reward operate to measure response high quality. The KL-constrained RL drawback is formulated to fine-tune the coverage based on rewards whereas adhering to a baseline coverage. A closed-form resolution to the relative entropy drawback is derived from prior analysis work, permitting the reward to be expressed as a operate of the coverage. REBEL iteratively updates the coverage based mostly on a sq. loss goal, using paired samples to approximate the partition operate. This core REBEL goal goals to suit the relative rewards between response pairs, in the end searching for to unravel the KL-constrained RL drawback.
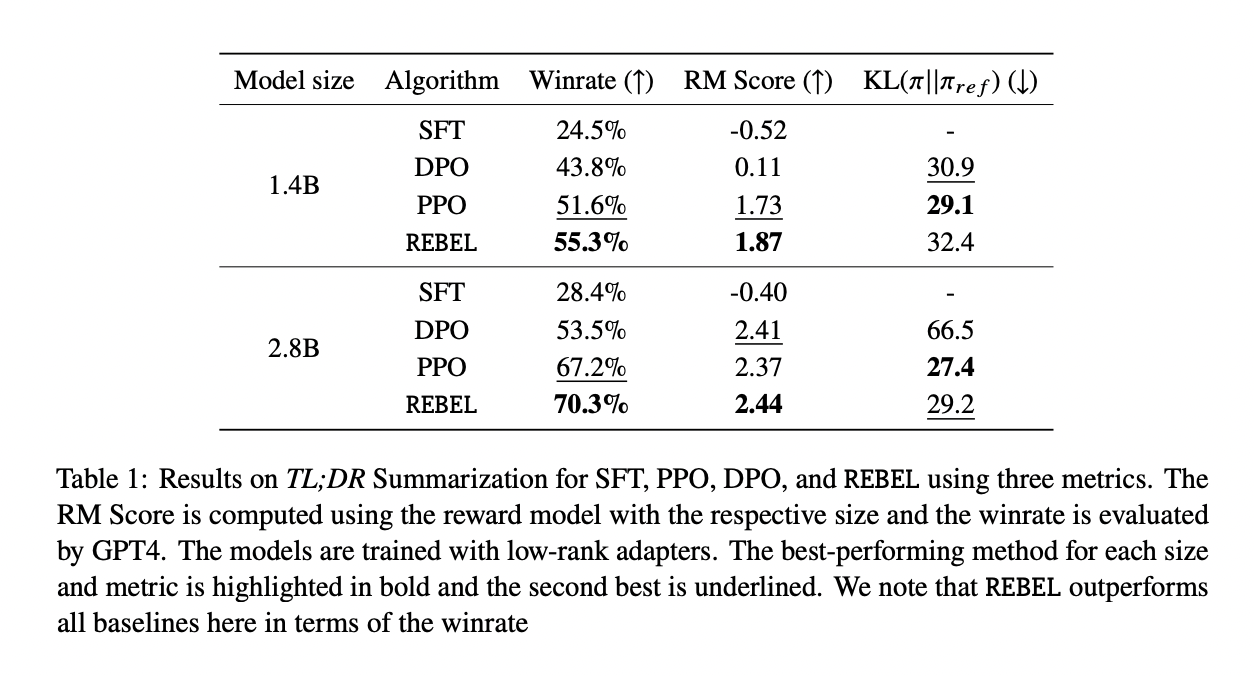
The comparability between REBEL, SFT, PPO, and DPO for fashions educated with LoRA reveals REBEL’s superior efficiency concerning RM rating throughout all mannequin sizes, albeit with a barely bigger KL divergence than PPO. Significantly, REBEL achieves the very best win fee beneath GPT4 when evaluated towards human references, indicating the benefit of regressing relative rewards. The trade-off between reward mannequin rating and KL divergence, the place REBEL displays greater divergence however achieves bigger RM scores than PPO, particularly in direction of the top of coaching.
In conclusion, this analysis presents REBEL, a simplified RL algorithm that tackles the RL drawback by fixing a collection of relative reward regression duties on sequentially gathered datasets. In contrast to coverage gradient approaches, which regularly depend on extra networks and heuristics like clipping for optimization stability, REBEL focuses on driving down coaching error on a least squares drawback, making it remarkably easy to implement and scale. Theoretically, REBEL aligns with the strongest ensures obtainable for RL algorithms in agnostic settings. In observe, REBEL demonstrates aggressive or superior efficiency in comparison with extra complicated and resource-intensive strategies throughout language modeling and guided picture era duties.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to observe us on Twitter. Be a part of our Telegram Channel, Discord Channel, and LinkedIn Group.
When you like our work, you’ll love our publication..
Don’t Overlook to affix our 40k+ ML SubReddit
Asjad is an intern advisor at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the purposes of machine studying in healthcare.


