
Group Query Answering (CQA) platforms, exemplified by Quora, Yahoo! Solutions, and StackOverflow, function interactive hubs for data change. Regardless of their reputation, the various high quality of responses poses a problem for customers who should navigate via quite a few solutions to search out related data effectively. Reply choice turns into pivotal, aiming to pinpoint probably the most pertinent responses from a pool of choices. This activity is complicated because of syntactic variations and the presence of noise in solutions. Conventional strategies and newer applied sciences like consideration mechanisms deal with these challenges, but there’s room for enhancing the interplay between questions and solutions.
Conventional strategies for reply choice in CQA embody content material/consumer modeling and adaptive assist. Content material/consumer modeling entails extracting options from consumer interactions, whereas adaptive assist aids consumer collaboration via query retrieval and routing. Consideration mechanisms, broadly utilized in question-answering duties, improve options and facilitate cross-sequence relationships. Giant language fashions (LLMs) like chatGPT have garnered consideration in pure language processing, notably in Q&A duties.
Researchers from PricewaterhouseCoopers launched Query-Reply cross-attention networks (QAN), they used the exterior information generated by the big language mannequin LLaMa to reinforce reply choice efficiency by LLM. BERT was utilized for pre-training on query topics, our bodies, and solutions, together with cross-attention mechanisms, capturing complete semantic data and interactive options. Integration of llama-7b-hf, a big language mannequin, enhances alignment between questions and solutions. Immediate optimization from 4 views permits LLM to pick appropriate solutions extra successfully, providing insights into immediate optimization methods. These contributions result in state-of-the-art efficiency on SemEval2015 and SemEval2017 datasets, surpassing present fashions.
The QAN mannequin contains three layers. Firstly, it employs BERT to seize contextual representations of query topics, our bodies, and solutions in token type. Subsequent, the cross-attention mechanism analyzes relationships between query subject-answer and query body-answer pairs, computing relevance and producing similarity matrices. Subsequently, the Interplay and Prediction Layer processes interplay options and assigns labels to every reply primarily based on conditional possibilities. It incorporates bidirectional GRU for context acquisition, adopted by max and imply pooling of questions and solutions to acquire fixed-length vectors. These vectors are concatenated to provide a worldwide illustration that’s handed to an MLP classifier to find out semantic equivalence within the question-answer pair.
QAN outperforms all baseline fashions on three analysis metrics, with developments attributed to the pre-trained BERT mannequin and a spotlight mechanism. Six variants of QAN have been evaluated on the Yahoo! Solutions dataset. Variations included excluding BERT in favor of task-specific phrase embeddings or character embeddings, eliminating cross consideration, or the interplay and prediction layer. Some variants mixed outputs instantly or handled query topics and our bodies as one entity throughout pre-training with BERT. These variations aimed to evaluate the impression of various elements on reply choice efficiency.
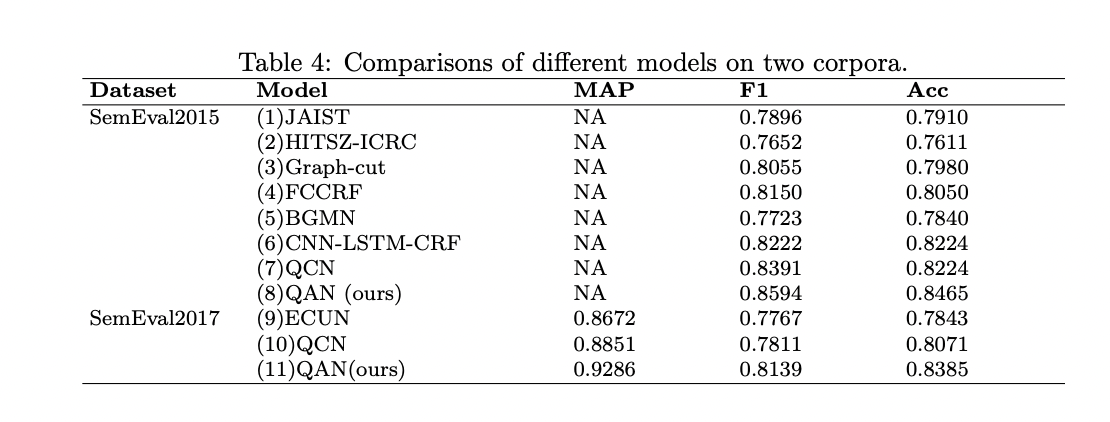
The proposed QAN mannequin makes use of BERT to seize context options of query topics, our bodies, and solutions. With a cross-attention mechanism, it gathers complete interactive data between questions and solutions. By integrating attention-questions and attention-answers, the QAN mannequin achieves state-of-the-art efficiency. Additionally, integrating giant language fashions with information enhancement improves reply choice accuracy.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to comply with us on Twitter. Be a part of our Telegram Channel, Discord Channel, and LinkedIn Group.
Should you like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our 43k+ ML SubReddit | Additionally, take a look at our AI Occasions Platform
Asjad is an intern marketing consultant at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the purposes of machine studying in healthcare.


