
Giant language fashions (LLMs) have gained important consideration in fixing planning issues, however present methodologies should be revised. Direct plan technology utilizing LLMs has proven restricted success, with GPT-4 attaining solely 35% accuracy on easy planning duties. This low accuracy highlights the necessity for simpler approaches. One other important problem lies within the lack of rigorous strategies and benchmarks for evaluating the interpretation of pure language planning descriptions into structured planning languages, such because the Planning Area Definition Language (PDDL).
Researchers have explored numerous approaches to beat the challenges of utilizing LLMs for planning duties. One methodology entails utilizing LLMs to generate plans immediately, however this has proven restricted success because of poor efficiency even on easy planning duties. One other method, “Planner-Augmented LLMs,” combines LLMs with classical planning strategies. This methodology frames the issue as a machine translation job, changing pure language descriptions of planning issues into structured codecs like PDDL, finite state automata, or logic programming.
The hybrid method of translating pure language to PDDL makes use of the strengths of each LLMs and conventional symbolic planners. LLMs interpret pure language, whereas environment friendly conventional planners guarantee answer correctness. Nevertheless, evaluating code technology duties, together with PDDL translation, stays difficult. Current analysis strategies, equivalent to match-based metrics and plan validators, must be revised in assessing the accuracy and relevance of generated PDDL to the unique directions.
Researchers from the Division of Pc Science at Brown College current Planetarium, a rigorous benchmark for evaluating LLMs’ capability to translate pure language descriptions of planning issues into PDDL, addressing the challenges in assessing PDDL technology accuracy. This benchmark affords a rigorous method to evaluating PDDL equivalence, formally defining planning drawback equivalence and offering an algorithm to test whether or not two PDDL issues fulfill this definition. Planetarium features a complete dataset that includes 132,037 floor reality PDDL issues with corresponding textual content descriptions, various in abstraction and dimension. The benchmark additionally gives a broad analysis of present LLMs in each zero-shot and fine-tuned settings, revealing the duty’s issue. With GPT-4 attaining solely 35.1% accuracy in a zero-shot setting, Planetarium serves as a precious software for measuring progress in LLM-based PDDL technology and is publicly accessible for future growth and analysis.
The Planetarium benchmark introduces a rigorous algorithm for evaluating PDDL equivalence, addressing the problem of evaluating totally different representations of the identical planning drawback. This algorithm transforms PDDL code into scene graphs, representing each preliminary and aim states. It then totally specifies the aim scenes by including all trivially true edges and creates drawback graphs by becoming a member of preliminary and aim scene graphs.
The equivalence test entails a number of steps: First, it performs fast checks for apparent non-equivalence or equivalence circumstances. If these fail, it proceeds to completely specify the aim scenes, figuring out all propositions true in all reachable aim states. The algorithm then operates in two modes: one for issues the place object id issues, and one other the place objects in aim states are handled as placeholders. For issues with object id, it checks isomorphism between mixed drawback graphs. For placeholder issues, it checks isomorphism between preliminary and aim scenes individually. This method ensures a complete and correct analysis of PDDL equivalence, able to dealing with numerous illustration nuances in planning issues.

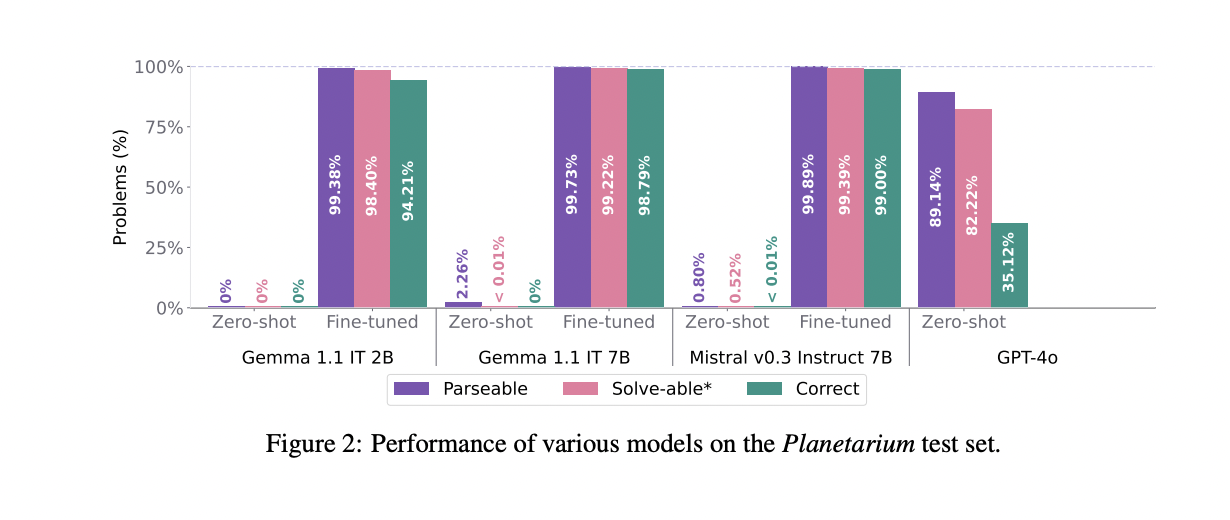
The Planetarium benchmark evaluates the efficiency of assorted massive language fashions (LLMs) in translating pure language descriptions into PDDL. Outcomes present that GPT-4o, Mistral v0.3 7B Instruct, and Gemma 1.1 IT 2B & 7B all carried out poorly in zero-shot settings, with GPT-4o attaining the very best accuracy at 35.12%. GPT-4o’s efficiency breakdown reveals that summary job descriptions are tougher to translate than express ones, whereas totally express job descriptions facilitate the better technology of parseable PDDL codeThey can be so, Nice-tuning considerably improved efficiency throughout all open-weight fashions. Mistral v0.3 7B Instruct achieved the very best accuracy after fine-tuning.
This examine introduces the Planetarium benchmark which marks a big advance in evaluating LLMs’ capability to translate pure language into PDDL for planning duties. It addresses essential technical and societal challenges, emphasizing the significance of correct translations to forestall potential hurt from misaligned outcomes. Present efficiency ranges, even for superior fashions like GPT-4, spotlight the complexity of this job and the necessity for additional innovation. As LLM-based planning programs evolve, Planetarium gives an important framework for measuring progress and making certain reliability. This analysis pushes the boundaries of AI capabilities and underscores the significance of accountable growth in creating reliable AI planning programs.
Try the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to observe us on Twitter.
Be a part of our Telegram Channel and LinkedIn Group.
In case you like our work, you’ll love our e-newsletter..
Don’t Overlook to affix our 46k+ ML SubReddit
Asjad is an intern guide at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the purposes of machine studying in healthcare.


