
Synthetic intelligence (AI) is reworking quickly, significantly in multimodal studying. Multimodal fashions intention to mix visible and textual data to allow machines to know and generate content material that requires inputs from each sources. This functionality is important for duties akin to picture captioning, visible query answering, and content material creation, the place greater than a single knowledge mode is required. Whereas many fashions have been developed to deal with these challenges, just some have successfully aligned the disparate representations of visible and textual knowledge, resulting in inefficiencies and suboptimal efficiency in real-world purposes.
A major problem in multimodal studying arises from how textual content and picture knowledge are encoded and represented. Textual knowledge are usually outlined utilizing embeddings derived from a lookup desk, making certain a structured and constant format. In distinction, visible knowledge are encoded utilizing imaginative and prescient transformers, which produce unstructured steady embeddings. This discrepancy in illustration makes it simpler for current multimodal fashions to fuse visible and textual knowledge seamlessly. Because of this, fashions battle to interpret complicated visual-textual relationships, limiting their capabilities in superior AI purposes that require coherent understanding throughout a number of knowledge modalities.
Historically, researchers have tried to mitigate this downside by utilizing a connector, akin to a multi-layer perceptron (MLP), to challenge visible embeddings into an area that may be aligned with textual embeddings. Whereas efficient in commonplace multimodal duties, this structure should resolve the elemental misalignment between visible and textual embeddings. Main fashions like LLaVA and Mini-Gemini incorporate superior strategies like cross-attention mechanisms and twin imaginative and prescient encoders to enhance efficiency. Nonetheless, they nonetheless face limitations as a result of inherent variations in tokenization and embedding methods, highlighting the necessity for a novel strategy that addresses these points at a structural stage.
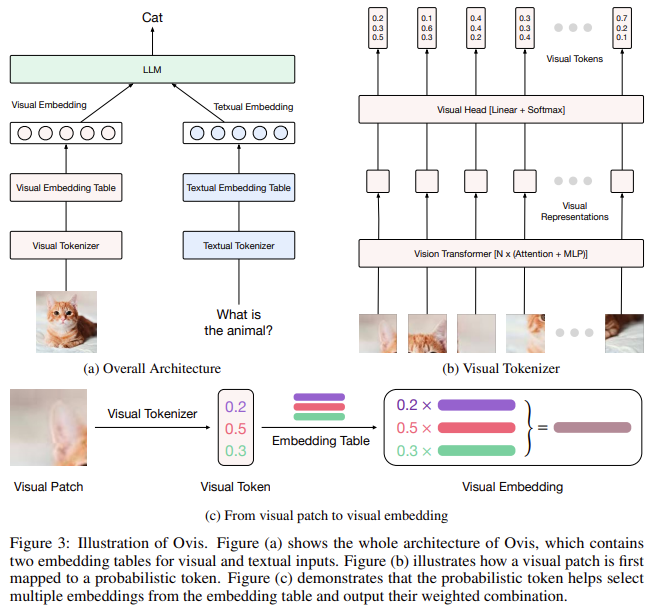
Researchers workforce from Alibaba Group and Nanjing College launched a brand new model of Ovis: Ovis 1.6 is a brand new multimodal giant language mannequin (MLLM) that structurally aligns visible and textual embeddings to deal with this problem. Ovis employs a novel visible embedding look-up desk, just like the one used for textual embeddings, to create structured visible representations. This desk permits the visible encoder to supply embeddings appropriate with textual embeddings, leading to more practical visible and textual data integration. The mannequin additionally makes use of probabilistic tokens for visible patches mapped into the visible embedding desk a number of instances. This strategy mirrors the structured illustration utilized in textual knowledge, facilitating a coherent mixture of visible and textual inputs.
Ovis’s core innovation lies in utilizing a visible embedding desk that aligns visible tokens with their textual counterparts. A probabilistic token represents every picture patch and indexes the visible embedding desk a number of instances to generate a closing visible embedding. This course of captures the wealthy semantics of every visible patch and ends in embeddings structurally just like textual tokens. In distinction to traditional strategies, which depend on linear projections to map visible embeddings right into a joint area, Ovis adopts a probabilistic strategy to generate extra significant visible embeddings. This methodology permits Ovis to beat the constraints of connector-based architectures and obtain higher efficiency in multimodal duties.
Empirical evaluations of Ovis reveal its superiority over different open-source MLLMs of comparable sizes. As an example, within the MathVista-Mini benchmark, Ovis scored 1808, considerably greater than its rivals. Equally, within the RealWorldQA benchmark, Ovis outperformed main proprietary fashions akin to GPT4V and Qwen-VL-Plus, scoring 2230, in comparison with GPT4V’s 2038. These outcomes spotlight Ovis’s power in dealing with complicated multimodal duties, making it a promising candidate for future developments within the discipline. The researchers additionally evaluated Ovis on a collection of normal multimodal benchmarks, together with MMBench and MMStar, the place it persistently surpassed fashions like Mini-Gemini-HD and Qwen-VL-Chat by a margin of seven.8% to 14.1%, relying on the precise benchmark.

Key Takeaways from the analysis:
- Structural Alignment: Ovis introduces a novel visible embedding desk that structurally aligns visible and textual embeddings, enhancing the mannequin’s capability to course of multimodal knowledge.
- Superior Efficiency: Ovis outperforms open-source fashions of comparable sizes in numerous benchmarks, reaching a 14.1% enchancment over connector-based architectures.
- Excessive-Decision Capabilities: The mannequin excels in duties requiring visible understanding of high-resolution pictures, such because the RealWorldQA benchmark, the place it scored 2230, surpassing GPT4V by 192 factors.
- Scalability: Ovis demonstrates constant efficiency throughout totally different parameter tiers (7B, 14B), making it adaptable to varied mannequin sizes and computational assets.
- Sensible Purposes: With its superior multimodal capabilities, Ovis will be utilized to complicated and difficult real-world eventualities, together with visible query answering and picture captioning, the place current fashions battle.
In conclusion, the researchers have efficiently addressed the longstanding misalignment between visible and textual embeddings. By introducing a structured visible embedding technique, Ovis permits more practical multimodal knowledge integration, bettering efficiency throughout numerous duties. The mannequin’s capability to outperform open-source and proprietary fashions of comparable parameter scales, akin to Qwen-VL-Max, underscores its potential as a brand new commonplace in multimodal studying. The analysis workforce’s strategy gives a major step ahead in creating MLLMs, offering new avenues for future analysis and software.
Try the Paper, GitHub, and HF Mannequin. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. For those who like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our 52k+ ML SubReddit.
We’re inviting startups, firms, and analysis establishments who’re engaged on small language fashions to take part on this upcoming ‘Small Language Fashions’ Journal/Report by Marketchpost.com. This Journal/Report might be launched in late October/early November 2024. Click on right here to arrange a name!
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.


