
Omost is an modern undertaking designed to boost the picture era capabilities of huge language fashions (LLMs) by changing their coding proficiency into superior picture composition abilities. Pronounced, “nearly,” the title Omost symbolizes two key concepts: first, after utilizing Omost, the picture will likely be “nearly” good; second, “O” stands for “omni” (multi-modal), and “most” signifies extracting the utmost potential from the know-how.
Omost equips LLMs with the power to write down code that composes visible content material on a digital Canvas agent. This Canvas can then be rendered utilizing particular implementations of picture mills to create precise photos.
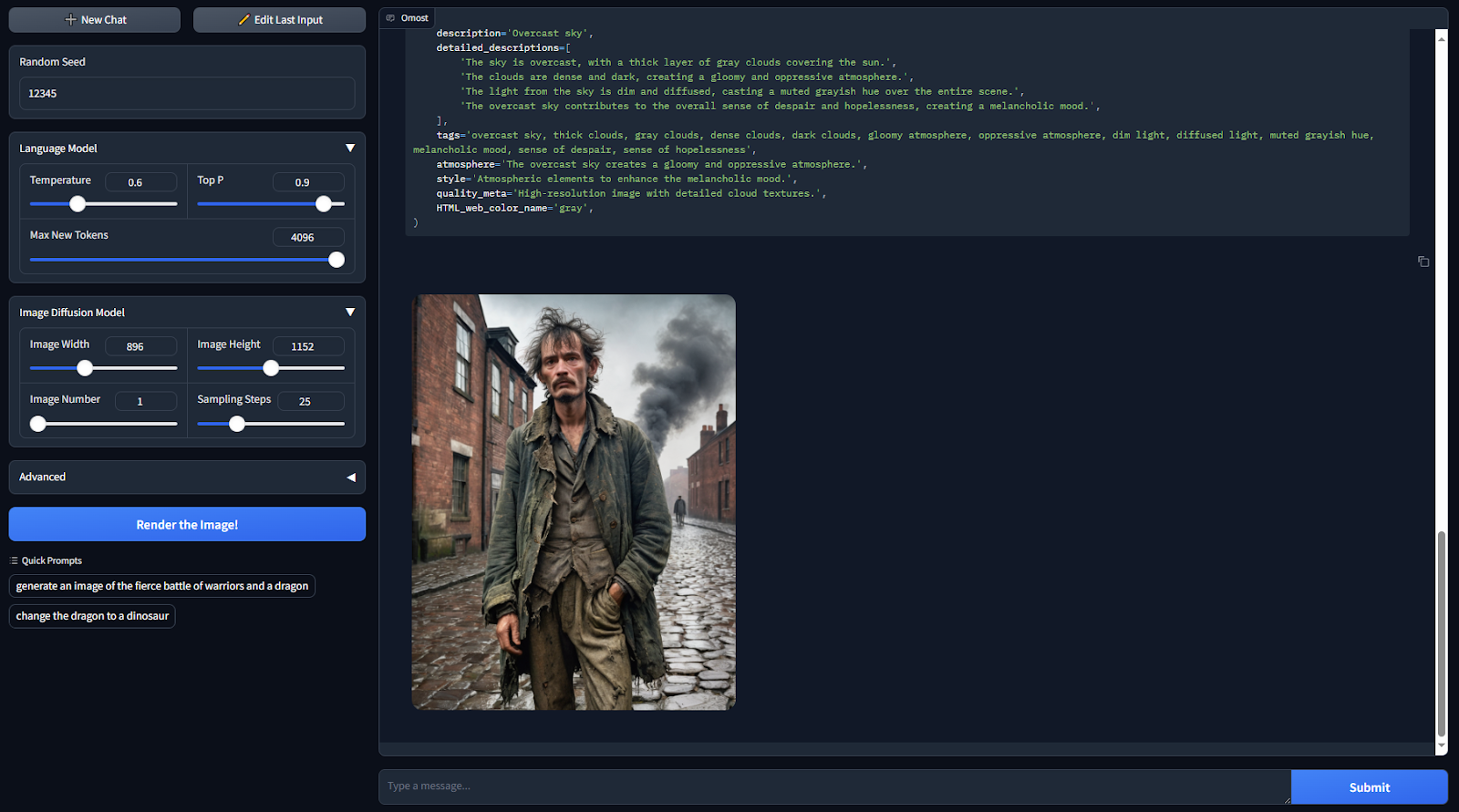
a ragged man carrying a tattered jacket within the nineteenth century:
Key Options and Fashions
Presently, Omost gives three pretrained LLM fashions based mostly on variations of Llama3 and Phi3:
1. omost-llama-3-8b
2. omost-dolphin-2.9-llama3-8b
3. omost-phi-3-mini-128k
These fashions are skilled utilizing a various dataset that features:
- Floor-truth annotations from a number of datasets, together with Open-Photographs.
- Knowledge extracted by means of automated picture annotation.
- Reinforcement studying by way of Direct Choice Optimization (DPO), guaranteeing the code could be compiled by Python 3.10.
- A small quantity of tuning information from OpenAI GPT -4’s multi-modal capabilities.
To start out utilizing Omost, customers can entry the official HuggingFace area or deploy it regionally. Native deployment requires an 8GB Nvidia VRAM.
Understanding the Canvas Agent
The Canvas agent is central to Omost’s picture composition. It gives capabilities to set international and native descriptions of photos:
- ‘Canvas.set_global_description`: Annotates the whole picture.
- `Canvas.add_local_description`: Annotates a particular a part of the picture.
Parameters for Picture Composition
- Descriptions: These are “sub-prompts” (lower than 75 tokens) that describe parts independently.
- Location, Offset, and Space: These outline the bounding field for picture parts utilizing a 9×9 grid system, leading to 729 doable areas.
- Distance to Viewer: Signifies the relative depth of parts.
- HTML Net Shade Identify: Specifies the colour utilizing normal HTML shade names.
Superior Rendering Methods
Omost gives a baseline renderer based mostly on consideration manipulation, providing a number of strategies for region-guided diffusion, together with:
1. Multi-Diffusion: Runs UNet on completely different areas and merges outcomes.
2. Consideration Decomposition: Splits consideration to deal with completely different areas individually.
3. Consideration Rating Manipulation: Modifies consideration scores to make sure correct activation in specified areas.
4. Gradient Optimization: Makes use of consideration activations to compute loss capabilities and optimize gradients.
5. Exterior Management Fashions: Makes use of fashions like GLIGEN and InstanceDiffusion for area steerage.
Experimental Options
- Immediate Prefix Tree: A construction that improves immediate understanding by merging sub-prompts into coherent descriptions.
- Tags, Environment, Fashion, and High quality Meta: Experimental parameters that may improve the general high quality and environment of the generated picture.
Omost represents a big step ahead in leveraging LLMs for classy picture composition. By combining strong coding capabilities with superior rendering methods, Omost permits customers to generate high-quality photos with detailed descriptions and exact management over visible parts. Whether or not utilizing the official HuggingFace area or deploying regionally, Omost gives a robust toolset for creating compelling visible content material.

Niharika is a Technical consulting intern at Marktechpost. She is a 3rd 12 months undergraduate, presently pursuing her B.Tech from Indian Institute of Know-how(IIT), Kharagpur. She is a extremely enthusiastic particular person with a eager curiosity in Machine studying, Knowledge science and AI and an avid reader of the most recent developments in these fields.


