
The fast progress of enormous language fashions (LLMs) and their rising computational necessities have prompted a urgent want for optimized options to handle reminiscence utilization and inference velocity. As fashions like GPT-3, Llama, and different large-scale architectures push the bounds of GPU capability, environment friendly {hardware} utilization turns into essential. Excessive reminiscence necessities, gradual token technology, and limitations in reminiscence bandwidth have all contributed to important efficiency bottlenecks. These issues are significantly noticeable when deploying LLMs on NVIDIA Hopper GPUs, as balancing reminiscence utilization and computational velocity turns into tougher.
Neural Magic introduces Machete: a brand new mixed-input GEMM kernel for NVIDIA Hopper GPUs, representing a serious development in high-performance LLM inference. Machete makes use of w4a16 mixed-input quantization to drastically scale back reminiscence utilization whereas guaranteeing constant computational efficiency. This progressive method permits Machete to cut back reminiscence necessities by roughly 4x in memory-bound environments. When in comparison with FP16 precision, Machete matches compute-bound efficiency whereas tremendously enhancing effectivity for memory-constrained deployments. As LLMs proceed to increase in scope, addressing reminiscence bottlenecks with sensible options like Machete turns into important for enabling smoother, quicker, and extra environment friendly mannequin inference.
One among Machete’s key improvements lies in its technical implementation. Constructed on CUTLASS 3.5.1, Machete leverages the wgmma tensor core directions to beat compute-bound limitations, leading to quicker mannequin inference. It additionally incorporates weight pre-shuffling, which permits for faster-shared reminiscence masses, successfully mitigating bottlenecks that usually come up in large-scale LLMs. This weight pre-shuffling mechanism optimizes shared reminiscence by permitting 128-bit masses, rising throughput and lowering latency. As well as, Machete has improved upconversion routines that facilitate environment friendly conversion of 4-bit parts to 16-bit, maximizing tensor core utilization. Collectively, these improvements make Machete an efficient resolution for enhancing LLM efficiency with out the overhead usually related to elevated precision or further computational prices.
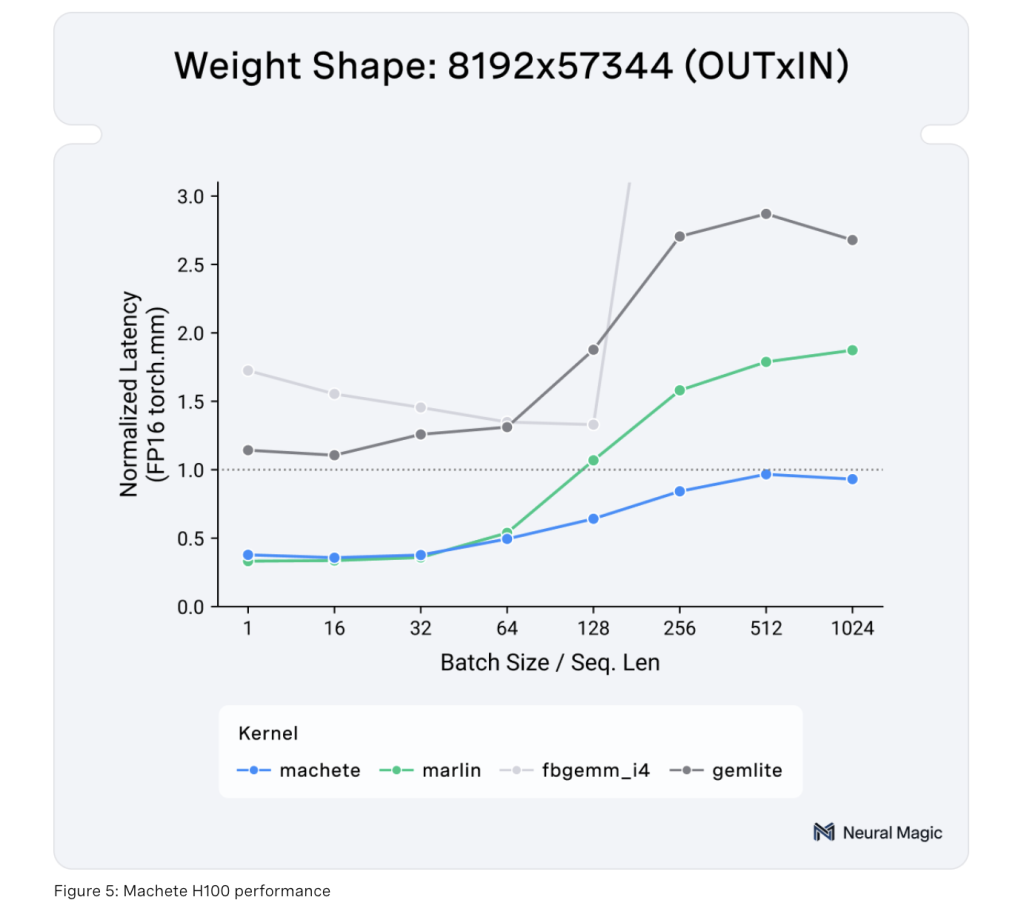
The significance of Machete can’t be overstated, significantly within the context of the rising demand for LLM deployments which might be each reminiscence and compute-efficient. By lowering reminiscence utilization by round fourfold, Machete helps be sure that even the biggest LLMs, comparable to Llama 3.1 70B and Llama 3.1 405B, may be run effectively on out there {hardware}. In testing, Machete achieved notable outcomes, together with a 29% improve in enter throughput and a 32% quicker output token technology fee for Llama 3.1 70B, with a powerful time-to-first-token (TTFT) of beneath 250ms on a single H100 GPU. When scaled to a 4xH100 setup, Machete delivered a 42% throughput speedup on Llama 3.1 405B. These outcomes reveal not solely the numerous efficiency increase offered by Machete but additionally its capability to scale effectively throughout completely different {hardware} configurations. The help for upcoming optimizations, comparable to w4a8 FP8, AWQ, QQQ, and improved efficiency for low-batch-size operations, additional solidifies Machete’s position in pushing the boundaries of environment friendly LLM deployment.
In conclusion, Machete represents a significant step ahead in optimizing LLM inference on NVIDIA Hopper GPUs. By addressing the vital bottlenecks of reminiscence utilization and bandwidth, Machete has launched a brand new method to managing the calls for of large-scale language fashions. Its mixed-input quantization, technical optimizations, and scalability make it a useful device for enhancing mannequin inference effectivity whereas lowering computational prices. The spectacular positive aspects demonstrated on Llama fashions present that Machete is poised to develop into a key enabler of environment friendly LLM deployments, setting a brand new commonplace for efficiency in memory-constrained environments. As LLMs proceed to develop in scale and complexity, instruments like Machete will probably be important in guaranteeing that these fashions may be deployed effectively, offering quicker and extra dependable outputs with out compromising on high quality.
Try the Particulars. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our e-newsletter.. Don’t Neglect to affix our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Finest Platform for Serving Positive-Tuned Fashions: Predibase Inference Engine (Promoted)
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.



