
Giant Language Fashions (LLMs) with prolonged context home windows have proven outstanding potential in dealing with complicated duties equivalent to lengthy conversations, doc summarization, and code debugging. Nonetheless, their deployment faces vital challenges, primarily because of the monumental reminiscence consumption of the KV Cache mechanism. This difficulty is especially pronounced in fixed-memory {hardware} environments. For instance, a 7 billion-parameter mannequin with a modest enter batch measurement and sequence size can require 64GB of KV cache, far exceeding the reminiscence wanted for the mannequin weights themselves. This reminiscence bottleneck severely limits the sensible software of LLMs in resource-constrained settings.
Researchers have developed numerous strategies to deal with KV cache reminiscence challenges in LLMs. Approaches like H2O and Scissorhands discover sparsity in Transformer consideration blocks to evict pointless tokens. Different methods embrace learnable token choice mechanisms and modifications to consideration constructions. Environment friendly Transformers goal to cut back self-attention complexity utilizing methods like dilated sliding home windows or mixed consideration varieties. Size extrapolation analysis focuses on adapting positional embeddings for prolonged context home windows. Nonetheless, the effectiveness of those strategies in real-world long-context duties could also be overestimated when evaluated solely utilizing metrics like perplexity.
Researchers from the Institute of Info Engineering, Chinese language Academy of Sciences, Faculty of Cyber Safety, College of Chinese language Academy of Sciences, and Baidu Inc. introduce NACL a singular KV cache eviction framework for LLMs, specializing in the encoding section fairly than era. It implements a one-time eviction course of throughout the whole enter, progressively clearing KV caches layer by layer. The important thing characteristic, PROXY-TOKENS EVICTION, makes use of world statistics from task-relevant proxy tokens, usually present in query inputs on the finish of lengthy texts. This method overcomes consideration bias issues seen in strategies utilizing native statistics or irrelevant proxy tokens. NACL goals to reinforce long-context modeling efficiency whereas effectively managing reminiscence constraints in LLMs.
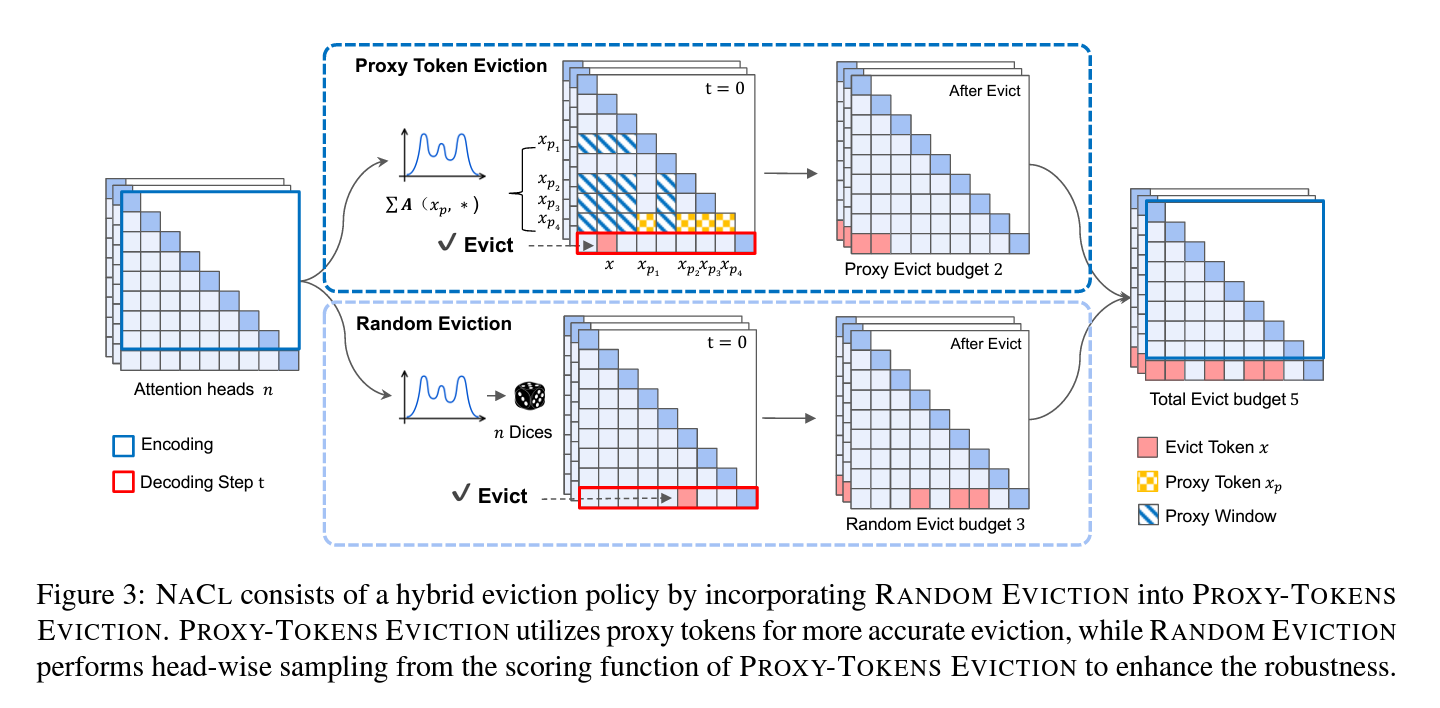
NACL introduces a hybrid KV cache eviction coverage combining PROXY-TOKENS EVICTION and RANDOM EVICTION.
PROXY-TOKENS EVICTION identifies a subset of proxy tokens inside the enter that precisely estimates token significance. The scoring operate aggregates consideration scores from these proxy tokens, lowering bias and enhancing eviction high quality. This methodology optimizes token retention whereas satisfying cache funds constraints.
RANDOM EVICTION incorporates randomness into the eviction course of to reinforce robustness. It constructs a chance distribution based mostly on token significance and randomly samples from it. This method helps protect important info that may in any other case be misplaced as a consequence of consideration biases.
NACL combines these strategies, making use of an environment friendly one-eviction technique underneath a complete KV cache funds. The hybrid method balances correct token significance estimation with randomness to enhance efficiency in long-text duties. The strategy is suitable with environment friendly consideration mechanisms like FlashAttention-2, minimizing reminiscence and computational overhead for deployment in resource-constrained environments.

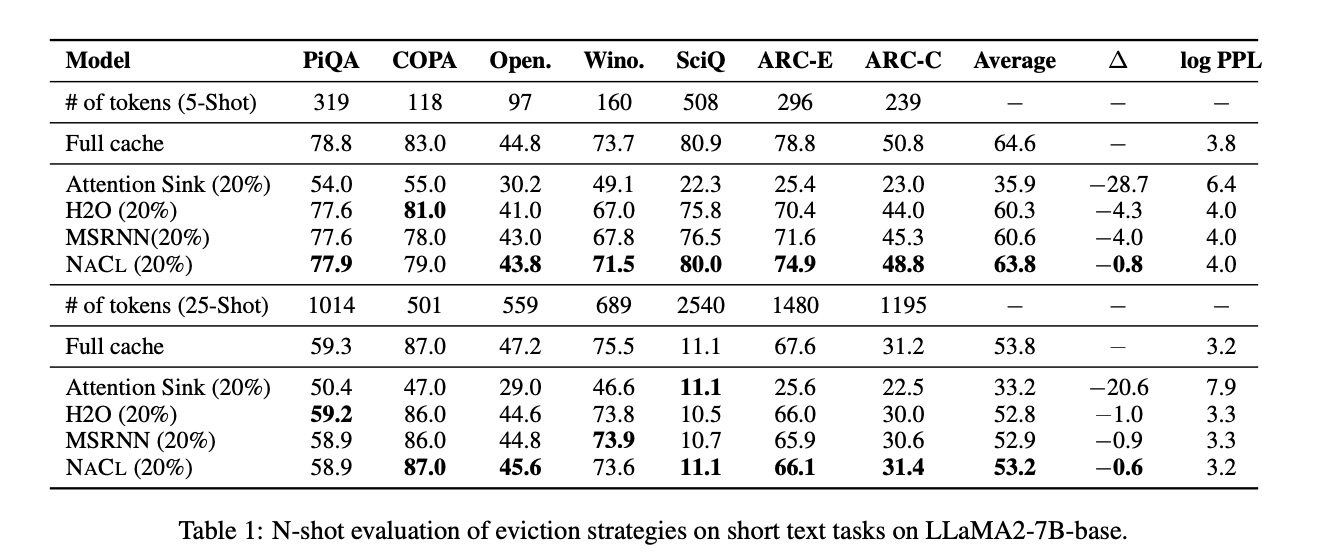
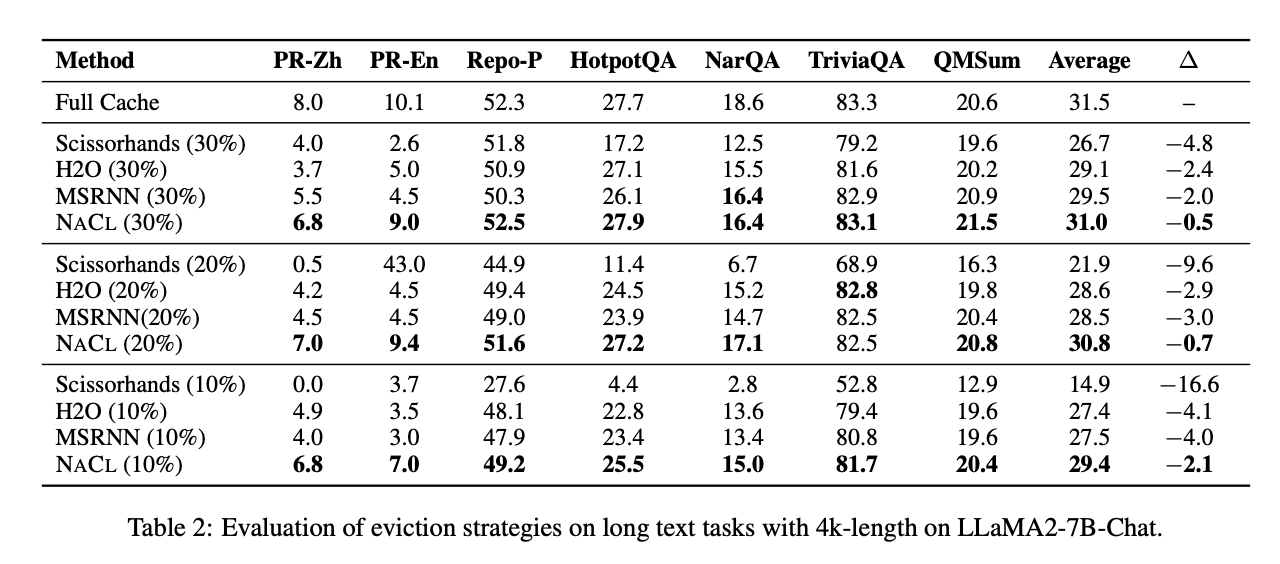
NACL demonstrates spectacular efficiency in each short-text and long-text situations whereas managing the KV cache underneath constrained reminiscence budgets. In brief-text benchmarks, NACL almost matches full cache efficiency, attaining a mean rating of 63.8% in 5-shot settings in comparison with the total cache’s 64.6%. It considerably outperforms H2O by 3.5 share factors. Even in additional complicated 25-shot settings, NACL reveals resilience, sustaining efficiency ranges near or matching full cache setups in some datasets. For long-text duties, NACL achieves an 80% reminiscence utilization discount with solely a 0.7 share level lower in common accuracy. It could actually obtain 3x extra discount in KV cache whereas sustaining comparable efficiency to baselines. NACL reveals secure efficiency throughout completely different funds settings, even surpassing full cache efficiency in some duties like HotpotQA and QMSum.
NACL’s effectiveness is especially evident in retaining pivotal info in lengthy inputs, outperforming strategies like H2O and MSRNN that undergo from consideration bias. This demonstrates NACL’s sturdy means to course of complicated lengthy texts whereas effectively managing reminiscence constraints.
The analysis introduces NACL, a sturdy KV cache eviction algorithm for LLMs processing lengthy texts. NACL combines PROXY-TOKENS EVICTION and RANDOM EVICTION, lowering reminiscence utilization throughout inference with out extra coaching. The method fashions eviction as a combinatorial optimization downside, utilizing importance-based references and composite sampling. Intensive analysis reveals NACL considerably improves cache eviction methods, reduces inference reminiscence prices, and minimizes influence on LLM job efficiency. This analysis contributes to optimizing LLM effectivity, probably enabling longer textual content processing with fewer computational sources. Future work might discover additional refinements and broader functions of NACL.
Take a look at the Paper and GitHub. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. For those who like our work, you’ll love our publication..
Don’t Neglect to hitch our 48k+ ML SubReddit
Discover Upcoming AI Webinars right here
Asjad is an intern advisor at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the functions of machine studying in healthcare.


