
NVIDIA has launched Mistral-NeMo-Minitron 8B, a extremely subtle massive language mannequin (LLM). This mannequin continues their work in creating state-of-the-art AI applied sciences. It stands out attributable to its spectacular efficiency throughout a number of benchmarks, making it one of the superior open-access fashions in its dimension class.
The Mistral-NeMo-Minitron 8B was created utilizing width-pruning derived from the bigger Mistral NeMo 12B mannequin. This course of reduces the mannequin’s dimension by selectively pruning much less essential community components, corresponding to neurons and a spotlight heads. It’s adopted by a retraining section utilizing a way often known as data distillation. The result’s a smaller, extra environment friendly mannequin that retains a lot of the efficiency of the unique, bigger mannequin.
The Technique of Mannequin Pruning and Distillation
Mannequin pruning is a way for making AI fashions smaller and extra environment friendly by eradicating much less important parts. There are two major sorts of pruning: depth pruning, which reduces the variety of layers within the mannequin, and width pruning, which reduces the variety of neurons, consideration heads, and embedding channels inside every layer. Within the case of Mistral-NeMo-Minitron 8B, width pruning was chosen to attain the optimum steadiness between dimension and efficiency.
Following pruning, the mannequin undergoes a light-weight retraining course of utilizing data distillation. This system transfers the data from the unique, bigger trainer mannequin to the pruned, smaller pupil mannequin. The target is to create a quicker and fewer resource-intensive mannequin whereas sustaining excessive accuracy. For Mistral-NeMo-Minitron 8B, this course of concerned retraining with a dataset of 380 billion tokens, which is considerably smaller than the dataset used for coaching the unique Mistral NeMo 12B mannequin from scratch.
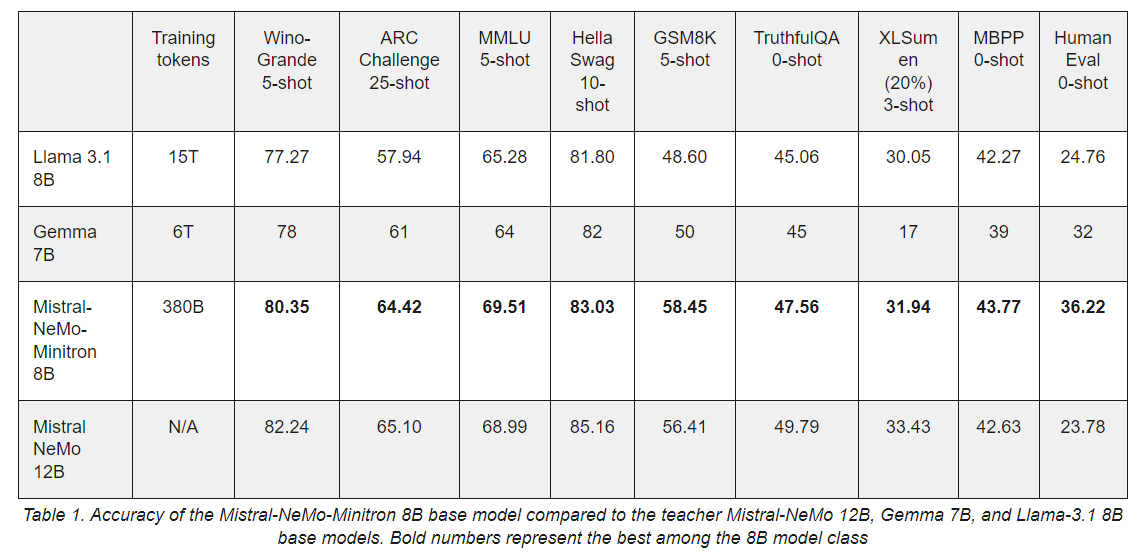
Efficiency and Benchmarking
Mistral-NeMo-Minitron 8B’s efficiency is a testomony to the success of this pruning and distillation strategy. The mannequin constantly outperforms different fashions in its dimension class throughout varied common benchmarks. As an example, a 5-shot WinoGrande take a look at scored 80.35, outperforming Llama 3.1 8B and Gemma 7B. Equally, it scored 69.51 within the MMLU 5-shot take a look at and 83.03 within the HellaSwag 10-shot take a look at, marking it as one of the correct fashions in its class.
The Mistral-NeMo-Minitron 8B’s comparability to different fashions, such because the Mistral NeMo 12B, Llama 3.1 8B, and Gemma 7B, highlights its superior efficiency in a number of key areas. This success is attributed to the Mistral NeMo 12B mannequin’s strategic pruning and the following mild retraining section. The Mistral-NeMo-Minitron 8B mannequin demonstrates the effectiveness of structured weight pruning and data distillation in producing high-performance, compact fashions.
Technical Particulars and Structure
The Mistral-NeMo-Minitron 8B mannequin structure is constructed on a transformer decoder for auto-regressive language modeling. It incorporates a mannequin embedding dimension 4096, 32 consideration heads, and an MLP intermediate dimension of 11,520, distributed throughout 40 layers. This design additionally incorporates superior strategies corresponding to Grouped-Question Consideration (GQA) and Rotary Place Embeddings (RoPE), contributing to strong efficiency throughout varied duties.
The mannequin was educated on a various dataset of English and multilingual textual content and code masking authorized, math, science, and finance domains. This intensive and various dataset ensures the mannequin is well-suited to numerous purposes. The coaching course of included the introduction of question-answering and alignment-style knowledge to reinforce the mannequin’s efficiency additional.
Future Instructions and Moral Issues
The discharge of Mistral-NeMo-Minitron 8B is just the start of NVIDIA’s efforts in creating smaller, extra environment friendly fashions by pruning and distillation. The corporate plans to proceed refining this method to create even smaller fashions with excessive accuracy and effectivity. These fashions will probably be built-in into the NVIDIA NeMo framework for generative AI, offering builders with highly effective instruments for varied NLP duties.
Nevertheless, it is very important observe the restrictions and moral concerns of the Mistral-NeMo-Minitron 8B mannequin. Like many massive language fashions, it was educated on knowledge which will comprise poisonous language and societal biases. Because of this, there’s a threat that the mannequin might amplify these biases or produce inappropriate responses. NVIDIA emphasizes the significance of accountable AI improvement and encourages customers to think about these components when deploying the mannequin in real-world purposes.
Conclusion
NVIDIA launched the Mistral-NeMo-Minitron 8B by utilizing width-pruning and data distillation. This mannequin rivals and infrequently surpasses different fashions in its dimension class. As NVIDIA continues to refine and develop its AI capabilities, the Mistral-NeMo-Minitron 8B units a brand new customary for effectivity and efficiency in pure language processing.
Try the Mannequin Card and Particulars. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. For those who like our work, you’ll love our e-newsletter..
Don’t Overlook to hitch our 49k+ ML SubReddit
Discover Upcoming AI Webinars right here
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.



